Clear Sky Science · sv
Klustering-och-regressionsbaserad modell och prestandaanalys för tidig förutsägelse av hjärtsjukdom
Varför det är viktigt att upptäcka hjärtproblem tidigt
Hjärtsjukdom utvecklas ofta tyst under många år, och när tydliga symtom väl dyker upp kan skadan redan vara skedd. Denna studie undersöker hur vardagliga kroppsburna sensorer och smart dataanalys kan samverka för att upptäcka varningstecken tidigare, vilket ger läkare och patienter mer tid att agera. Genom att kombinera två olika sätt att betrakta hälsodata strävar forskarna efter att göra förutsägelser mer träffsäkra utan att göra tekniken svårare att använda i verkliga kliniska miljöer.
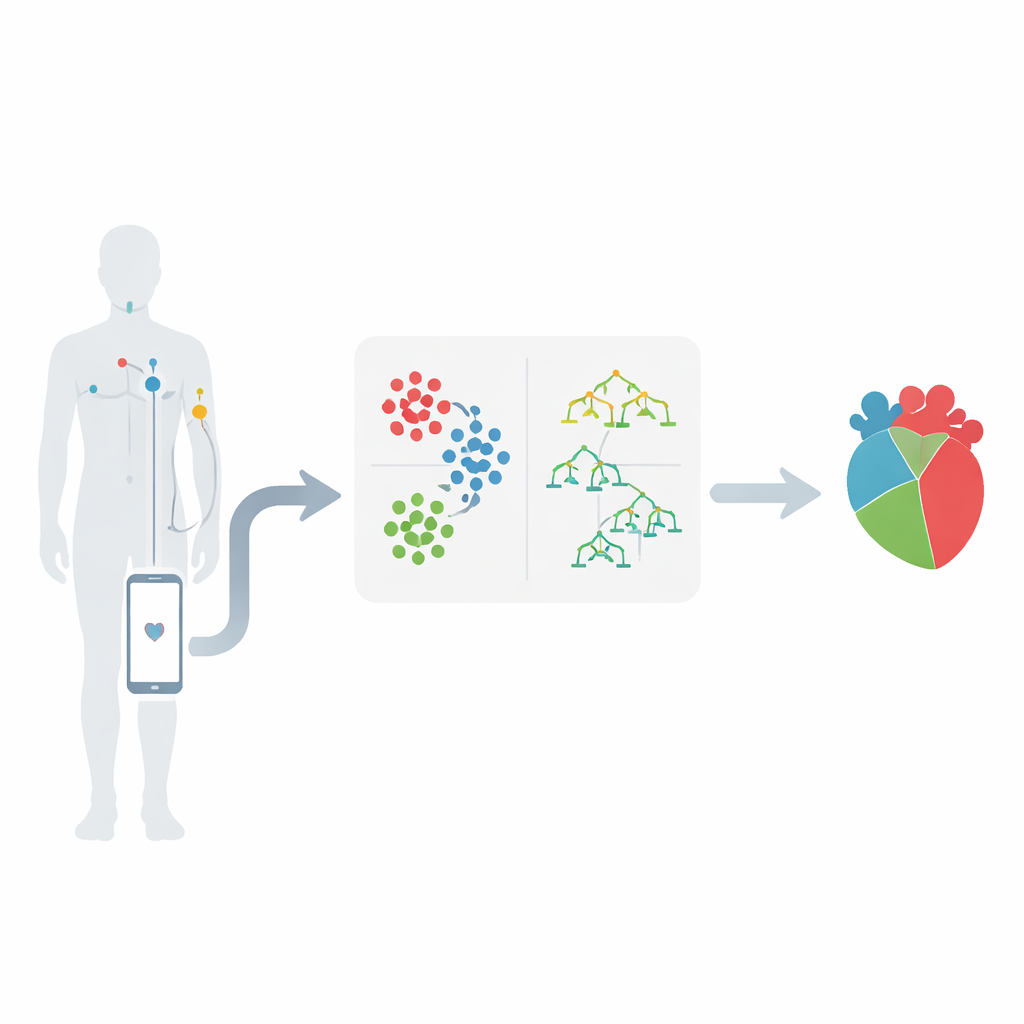
Från kroppssensorer till smarta varningar
Arbetet är förlagt till världen av trådlösa kroppsområdesnätverk, där små sensorer placerade på huden mäter signaler som puls, blodtryck och hjärtats elektriska aktivitet. Dessa sensorer skickar mätvärden till en mobil enhet som vidarebefordrar dem till ett medicinskt center för analys. Den centrala idén är att dessa sifferströmmar kan avslöja mönster som antyder utvecklande hjärtproblem långt innan en kris inträffar. Författarna fokuserar på en välkänd hjärtsjukdomsdataset och väljer ut 12 viktiga variabler, inklusive typ av bröstsmärta, blodtryck, kolesterol, blodsocker, ansträngningsutlösta bröstbesvär och förändringar som syns på ett elektrokardiogram.
Hitta dolda grupper i patientdata
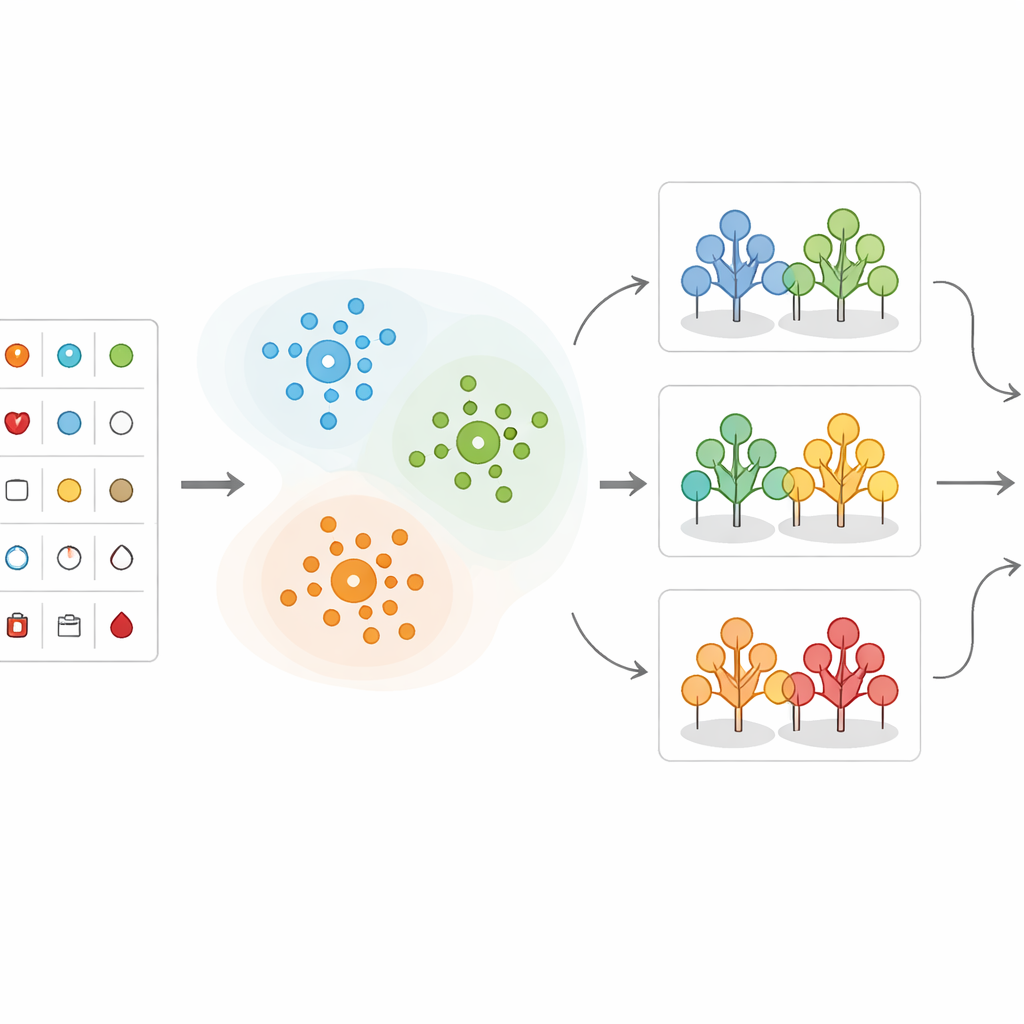
I stället för att mata in alla patientregister direkt i en enda förutsägelseformel grupperar teamet först liknande patienter tillsammans. De använder en metod som kallas K-means-klustring, vilken sorterar personer i kluster baserat på hur lika deras mätvärden är, med ålder som en central faktor. Till exempel kan patienter naturligt falla in i grupper med mycket högt blodtryck, högt kolesterol eller särskilda mönster i hjärttester. Detta klustringssteg hjälper till att lyfta fram vilka kombinationer av mätvärden som är särskilt oroande. Det visar också att vissa intervall—såsom blodtryck över 150, kolesterol över 300 eller särskilda förändringar i hjärtspår—tendensvis är kopplade till mycket högre risk.
Lära maskiner bedöma risk
När data har grupperats tillämpar forskarna flera maskininlärningsmetoder som lär sig av tidigare fall för att förutsäga om en ny patient sannolikt har betydande hjärtsjukdom. De jämför olika angreppssätt, inklusive beslutsträd, k-närmsta grannar, supportvektormaskiner, logistisk regression, Naiv Bayes och random forests. I deras hybriddesign tilldelas varje ny patient först det närmaste klustret; därefter gör en random forest-modell, tränad särskilt på den typen av patienter, den slutgiltiga riskbedömningen. Datan rengörs, skalas och delas noggrant in i tränings- och testset, och klassobalans (fler friska än sjuka patienter) hanteras så att modellerna inte blir förskjutna mot majoritetsgruppen.
Hur väl den hybrida modellen presterar
För att bedöma framgång tittar studien inte bara på total noggrannhet utan även på hur ofta modellen korrekt flaggar sjuka patienter (recall), korrekt lugnar friska (specificitet) och hur väl den balanserar båda målen (F1-poäng och ROC–AUC). Tidigare studier som använt liknande data nådde ofta upp mot cirka 85 procent noggrannhet och hade svårt att förbättra dessa finare mått. Här når den kombinerade klustrings-och-random-forest-metoden omkring 91 procents noggrannhet, med stark recall och mycket hög specificitet. Konfidensintervallen för denna modell överlappar inte med dem för de enklare metoderna, vilket antyder att förbättringen troligen inte beror på slumpen. Samtidigt håller beräkningstiden sig inom ett praktiskt spann—i storleksordningen millisekunder till sekunder—lämpligt för realtids- eller nära realtidsövervakningssystem.
Vad detta betyder för patienter och läkare
I praktiska termer visar studien att låta datorer först sortera patienter i meningsfulla grupper och sedan tillämpa skräddarsydda förutsägelseregler kan skärpa den tidiga upptäckten av hjärtsjukdom. Metoden är särskilt lovande för kontinuerliga övervakningssystem där bärbara sensorer tyst samlar data i bakgrunden. Även om resultaten kommer från ett måttligt stort, strukturerat dataset snarare än fullständiga kliniska journaler, och författarna varnar för möjliga bias, är budskapet tydligt: smartare användning av befintliga mätningar kan ge läkare ett mer pålitligt tidigt varningssystem. Med vidare arbete och större, rikare dataset skulle denna typ av hybridanalys kunna hjälpa till att förvandla råa sensorsignaler till tidiga, personliga larm som förhindrar hjärtinfarkter och andra allvarliga händelser innan de inträffar.
Citering: Tolani, M., AlZahrani, Y., Suman, G. et al. Clustering-cum-regression based model and performance analysis for early prediction of heart disease. Sci Rep 16, 9494 (2026). https://doi.org/10.1038/s41598-026-40626-z
Nyckelord: förutsägelse av hjärtsjukdom, bärbara hälsosensorer, maskininlärning, klustring av medicinska data, random forest-modell