Clear Sky Science · sv
Exakta funktionskollisioner i neurala nätverk
När olika bilder lurar en smart maskin
Moderna artificiella intelligenssystem kan känna igen ansikten, läsa medicinska röntgenbilder och styra självkörande bilar. Vi vet sedan tidigare att de kan luras av små, noggrant utformade förändringar i en bild. Den här artikeln visar något ännu mer överraskande: samma nätverk kan vara blinda för stora, uppenbara förändringar och behandla mycket olika bilder som om de vore samma. Att förstå hur och varför detta sker är avgörande om vi vill ha AI-system som vi verkligen kan lita på.
Från små tweak till stora blinda fläckar
Djupa neurala nätverk driver dagens genombrott inom vision, språk och många andra områden. Tidigare forskning om adversariala exempel avslöjade att en knappast synlig förändring i en bild kan få ett nätverk att klassificera fel med hög säkerhet. Nyare arbete har upptäckt den motsatta problematiken: vissa nätverk reagerar nästan inte alls på stora, uppenbara förändringar och ger ändå nästan identiska prediktioner. I sådana fall "kolliderar" de interna funktionerna som extraheras från två mycket olika bilder — det vill säga nätverket representerar dem på nästan samma sätt. Denna studie tar idén mycket längre och bevisar att vanliga nätverk inte bara har approximativa kollisioner utan kan ha exakta funktionskollisioner, där två distinkta indata mappas till precis samma interna signaler.
Hur kollisioner uppstår inuti ett nätverk
För att förklara dessa kollisioner undersöker författarna neurala nätverks inre och fokuserar på deras viktmatriser, de tränade talen som kopplar ett lager till nästa. En funktionskollision uppstår när två olika indata ger samma utdata i något lager; när det inträffar ser alla senare lager också samma sak och kan därför inte skilja indatan åt. Matematiskt sker detta när skillnaden mellan två indata ligger i ett lagers "nullrum": riktningar i indatarummet som lagret fullständigt ignorerar. Författarna visar att när en viktmatris har en egenvärde noll eller mappar från ett högre-dimensionellt rum till ett lägre-dimensionellt, måste sådana ignorerade riktningar finnas. Eftersom de flesta verkliga arkitekturer, inklusive populära modeller för klassificering, segmentering och objektigenkänning, använder många sådana lager, är kollisioner inte sällsynta kantfall utan en nästan oundviklig egenskap hos dessa nätverk.
Ett nytt sätt att konstruera kolliderande indata
Byggt på denna insikt introducerar artikeln ett praktiskt recept kallat nullrumsökning. Istället för att förlita sig på trial-and-error eller gradientbaserade trick använder denna metod direkt nullrummet hos den första viktmatrisen. Med start från vilken bild som helst beräknar författarna en vektor som det första lagret ignorerar och adderar sedan en skalad version av denna vektor till bilden. Eftersom den riktningen är osynlig för lagret förblir nätverkets interna funktioner — och slutliga prediktion — exakt desamma, även om bilden själv ter sig kraftigt förvrängd för en mänsklig observatör. Samma idé förlängs till konvolutionella lager och, i princip, till senare lager också. Författarna undersöker många standardmodeller och finner att de flesta har gott om sådana ignorerade riktningar, vilket innebär att otaliga kolliderande bilder kan genereras på detta sätt för en rad olika uppgifter.
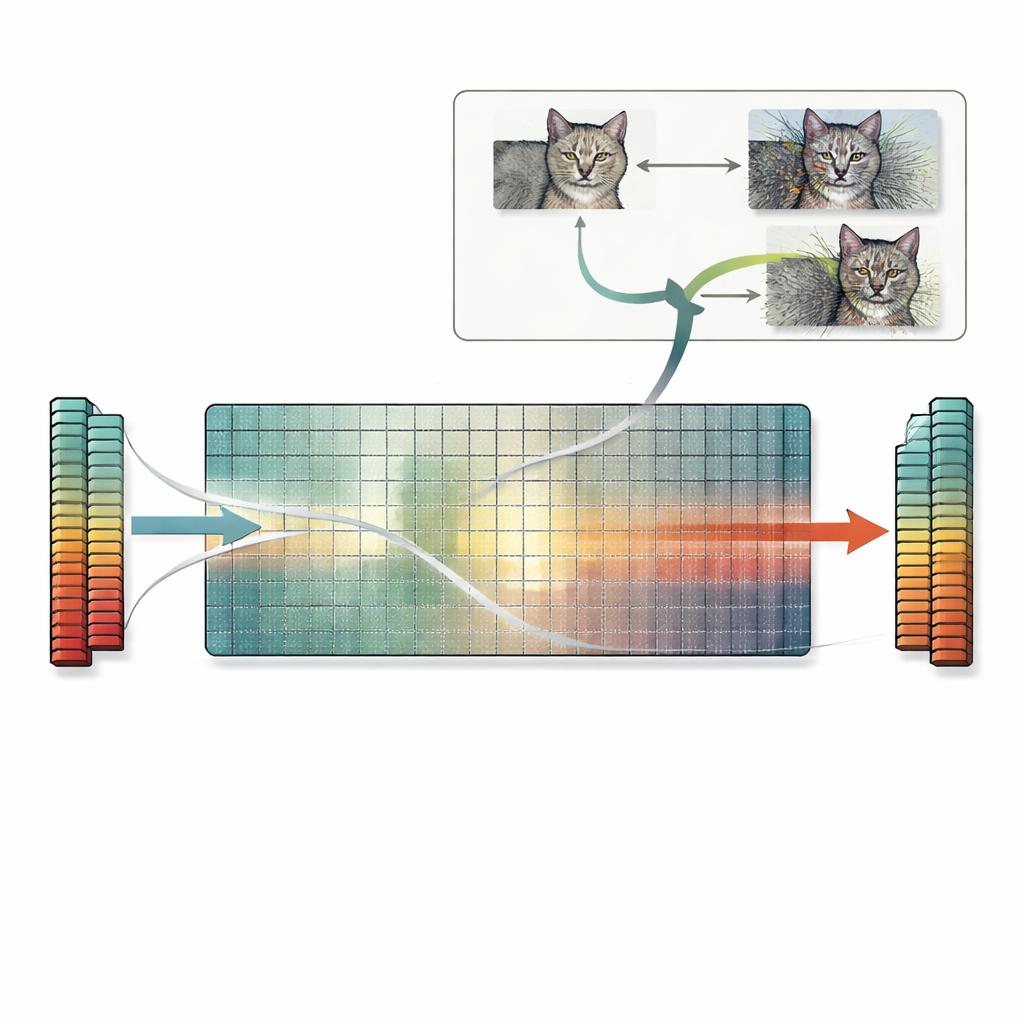
Dolda risker för likhet, förklaringar och säkerhet
Dessa exakta funktionskollisioner har långtgående konsekvenser. Två bilder med kolliderande funktioner kommer inte bara att dela samma prediktion, de kommer ofta också att dela samma förklaringskartor som produceras av populära tolkningsverktyg. Det kan få en oigenkännlig, kraftigt störd bild att framstå som lika väl underbyggd som en ren bild, vilket undergräver tilltron till förklaringsmetoder. Problemet påverkar också funktionsbaserade likhetsmått som förlitar sig på neurala nätverk: sådana mått kan bedöma en kraftigt korrupt bild som "identisk" med originalet eftersom funktionerna matchar exakt, trots att enkla pixelbaserade mått korrekt flaggar stora skillnader. Slutligen kan nullrumsökningen kombineras med standard adversariala attacker, vilket producerar många olika adversariala bilder som alla ger samma felaktiga prediktion och håller sig inom vanliga perturbationsgränser, vilket fördjupar befintliga säkerhetsbekymmer.
Vad detta betyder för att bygga säkrare AI
Enkelt uttryckt visar detta arbete att dagens neurala nätverk ofta kastar bort information på förutsägbara sätt och lämnar hela riktningar i indatarummet som inte påverkar deras beslut alls. Angripare kan utnyttja dessa blinda fläckar för att skapa bisarra eller adversariala bilder som ett nätverk behandlar som identiska med normala sådana. Författarna föreslår att man kan använda enkla räkningar av dessa ignorerade riktningar som ett sätt att bedöma hur sårbar en modell kan vara, och argumenterar för att slankare, bättre regulariserade nätverk med mindre nullrum kan vara mer robusta. Mycket återstår att testa i praktiken, men huvudbudskapet är tydligt: om vi vill ha pålitlig AI måste vi uppmärksamma inte bara vad nätverk reagerar på, utan också vad de ignorerar.
Citering: Ozbulak, U., Rao, S., De Neve, W. et al. Exact feature collisions in neural networks. Sci Rep 16, 10139 (2026). https://doi.org/10.1038/s41598-026-40605-4
Nyckelord: neurala nätverk, adversariala exempel, funktionskollisioner, modellrobusthet, nullrumsökning