Clear Sky Science · sv
Sekretessbevarande federerat lärande med lättviktsuppmärksamhet förbättrade CNN:er för automatiserad leukemidetektion över distribuerad medicinsk bildbehandling
Varför det spelar roll att dela kunskap utan att dela hemligheter
Modern medicin förlitar sig i allt större utsträckning på datorer för att tolka medicinska bilder, från röntgenbilder till mikroskopiska preparat. Men att lära upp dessa system innebär ofta att samla känsliga patientdata på ett och samma ställe, vilket väcker allvarliga integritetsfrågor. Denna studie visar en metod för att sjukhus ska kunna bygga ett kraftfullt system för att upptäcka leukemi i blodbilder utan att någonsin dela rå patientdata, och kombinerar sekretesskydd med diagnostisk noggrannhet nära toppnivå.
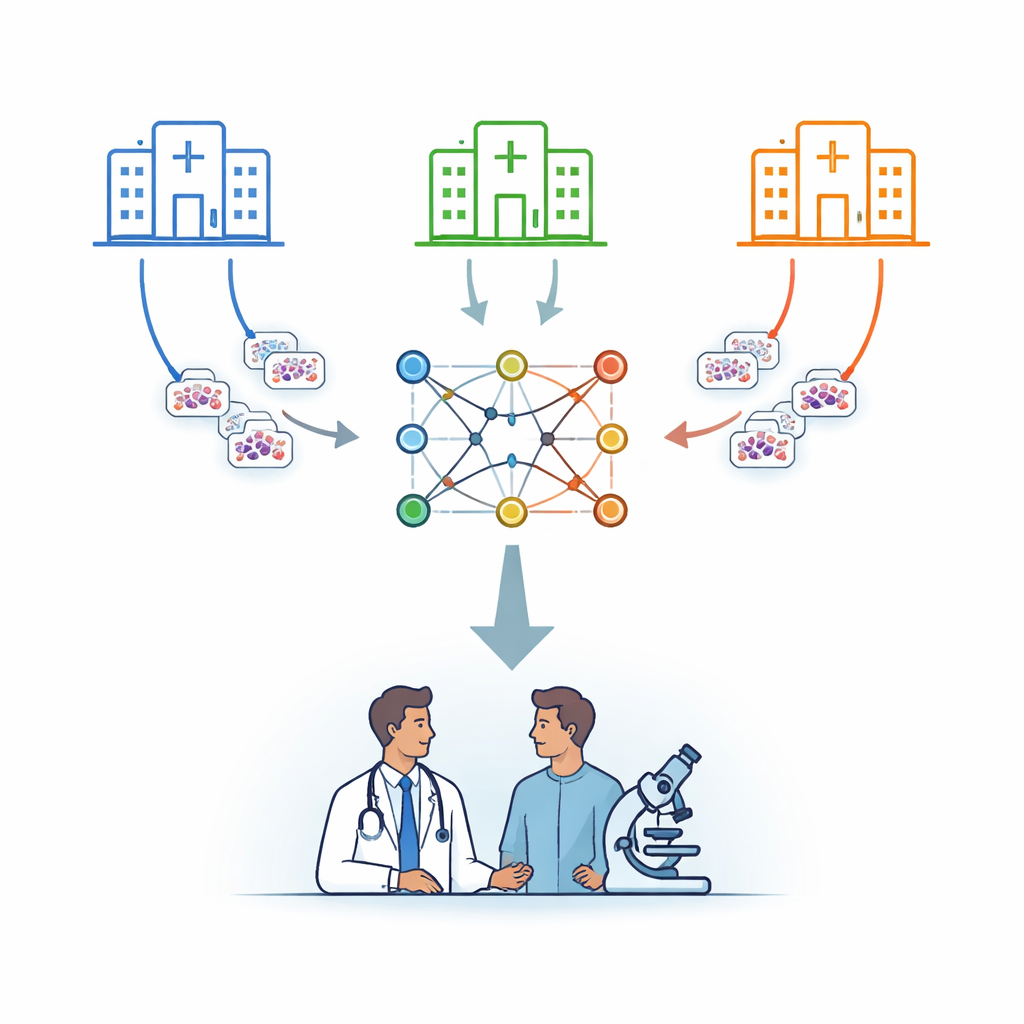
Många sjukhus, en gemensam intelligens
Forskarna inriktar sig på leukemi, en blodcancer som delvis diagnostiseras genom att granska celler i mikroskop. Istället för att skicka patientbilder till en central server använder de en strategi som kallas federerat lärande. I detta upplägg behåller flera sjukhus sina bilder lokalt och tränar en kopia av samma datoriserade modell på plats. Periodvis skickas endast modellens inlärda parametrar till en säker central server, som genomsnittar dem och skickar tillbaka en förbättrad, sammanslagen modell. På så sätt samlas kunskap utan att de underliggande bilderna lämnar sin heminstans.
Att lära ett litet nätverk att rikta uppmärksamhet
I kärnan av ramverket finns en lättviktsmodell för bildanalys baserad på convolutional neural networks, ett standardverktyg för bildtolkning. Författarna förbättrar den med en kompakt "uppmärksamhets"-mekanism som hjälper nätverket att fokusera på de mest informativa delarna av varje blodcell, såsom cellkärnans form och texturen i omgivande material. Trots att modellen bara har ungefär 33 000 justerbara inställningar — en bråkdel av många moderna nätverks storlek — kan den ändå skilja mellan fyra kliniskt viktiga kategorier: benigna celler, tidiga förändringar, pre-leukemiska tillstånd och fullt utvecklade pro-leukemiska celler. Genomtänkt design håller beräkningarna tillräckligt snabba för realistisk användning i rutinlaboratorier.
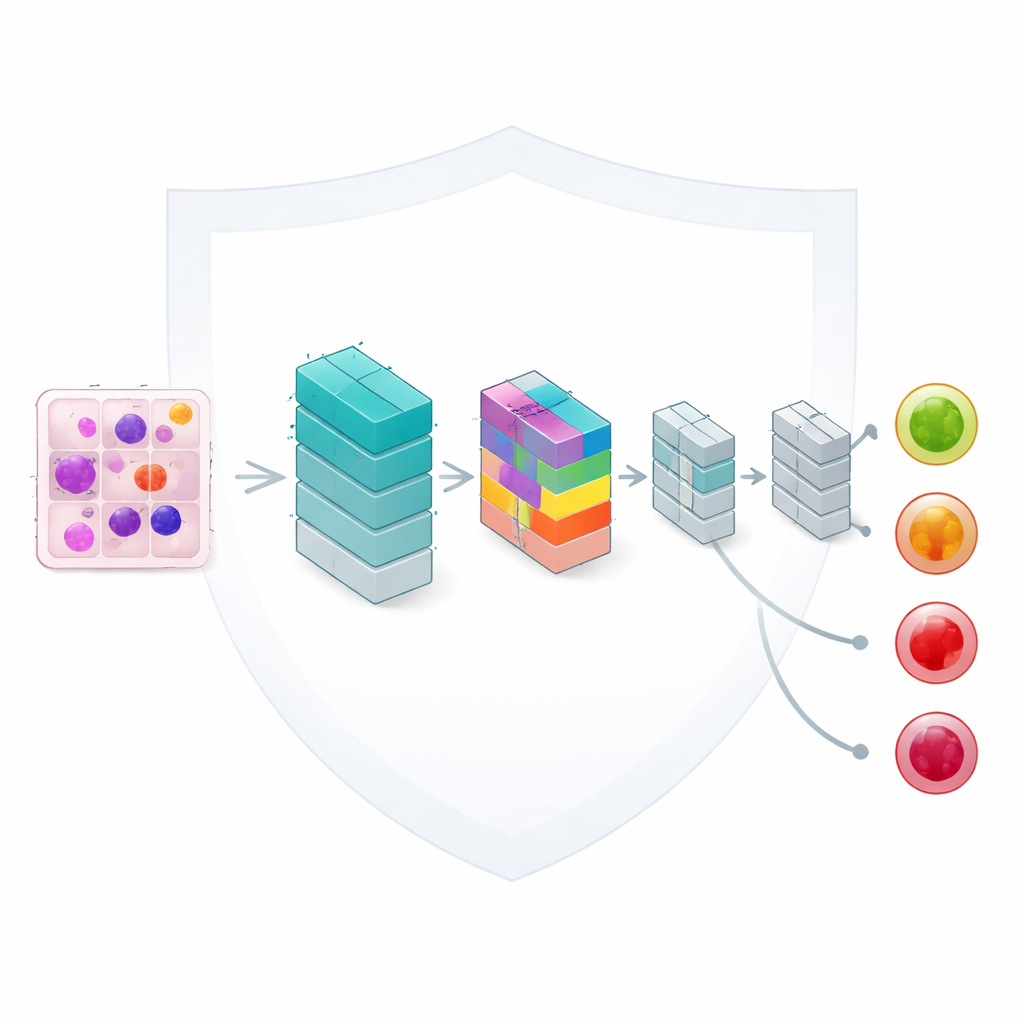
Rättvist lärande från ojämn och utspridd data
I verkliga vårdsystem möter sjukhus inte samma sammansättning av patienter. Ett center kan främst se tidig sjukdom, ett annat mer avancerade fall. Teamet speglar avsiktligt denna verkliga obalans genom att dela en datamängd på 3 256 blodutstrykbilder över flera simulerade sjukhus med olika andelar av varje leukemistadium. De analyserar sedan hur denna ojämna fördelning påverkar inlärningen, med statistiska mått för att kvantifiera hur olika varje sjukhus data är och hur lika deras slutliga noggrannheter blir. Ett viktat genomsnittsschema säkerställer att siter med mer data får proportionerligt större inflytande samtidigt som prestandaskillnader mellan siter hålls mycket små.
Noggrannhet som matchar central träning
Trots att data hålls fragmenterade och ojämnt fördelade lär sig den delade modellen att klassificera leukemistadier med imponerande skicklighet. Med tre simulerade sjukhus når den globala modellen ungefär 95,7 % noggrannhet på hållna testbilder; med fem sjukhus och fler träningsrundor stiger noggrannheten till cirka 96,6 %. Maligna kategorier — de som representerar pre-leukemiska och mer avancerade sjukdomsstadier — känns igen särskilt väl, med i vissa fall nästan perfekta poäng. Den mer utmanande benigna kategorin, som är underrepresenterad, presterar något sämre, vilket belyser behovet av bättre balans eller riktade tekniker för sällsynta men viktiga klasser. Ändå kommer det federerade systemet mycket nära den noggrannhet som uppnås när all data centraliseras, samtidigt som det behåller sekretessfördelarna med lokal lagring.
Göra maskinens resonemang synligt och trovärdigt
För att bygga förtroende hos kliniker går författarna bortom ren noggrannhet och undersöker hur modellen fattar sina beslut. De genererar visuella överlagringar som framhäver vilka delar av varje cellbild som mest påverkade utgången. Dessa kartor visar att modellen koncentrerar sig på medicinskt meningsfulla funktioner, såsom avvikande kärnformer i farligare leukemistadier, och visar mer diffusa mönster för benigna celler. Teamet studerar också hur säker modellen är i sina prediktioner och finner att korrekta svar tenderar att ha hög tilltro, särskilt för maligna stadier, vilket tyder på en god överensstämmelse mellan systemets säkerhet och dess tillförlitlighet.
Vad detta betyder för framtida cancerdiagnostik
För icke-specialister är huvudbudskapet att det nu är möjligt för sjukhus att samarbeta om smartare cancerdiagnostik utan att lämna över sina patientbilder. Detta arbete visar att en kompakt, omsorgsfullt designad modell tränad via federerat lärande kan närma sig noggrannheten hos traditionella metoder med samlad data samtidigt som den respekterar sekretessregler och praktiska begränsningar i beräkningskraft och nätverkstrafik. Med vidare arbete för att bättre hantera underrepresenterade celltyper och minska kommunikationskostnader kan liknande sekretessbevarande system utsträckas till andra cancerformer och avbildningstester, vilket hjälper kliniker världen över att dra nytta av delad erfarenhet utan att exponera enskilda patienter.
Citering: Awan, M.Z., Khan, N.A., Strakos, P. et al. Privacy-preserving federated learning with light-weight attention improved CNNs for automated leukemia detection across distributed medical imaging. Sci Rep 16, 9768 (2026). https://doi.org/10.1038/s41598-026-40581-9
Nyckelord: federerat lärande, leukemiavbildning, medicinsk AI-sekretess, uppmärksamhetsbaserad CNN, digital patologi