Clear Sky Science · sv
CMT-Unet: utnyttjar ett etappdelat hybridramverk för förbättrad noggrannhet och effektivitet vid segmentering av medicinska bilder
Skarpare vyer inuti kroppen
Modern medicin är i hög grad beroende av avbildningar som CT och MRI för att se in i kroppen, men att förvandla dessa suddiga gråskalebilder till tydliga konturer av organ och vävnader är fortfarande en utmaning. Läkare behöver precisa gränser för att planera operationer, följa hjärtats funktion eller mäta hur en tumör svarar på behandling. Denna artikel presenterar en ny datorvisionsmetod, kallad CMT-Unet, utformad för att rita dessa gränser mer exakt och effektivt, vilket tar automatisk bildanalys ett steg närmare daglig klinisk användning.
Varför bildkonturer är viktiga
Inför en operation eller en komplex behandling behöver kliniker ofta en pixelnivåkarta över organ eller strukturer i en bild—en process som kallas segmentering. Traditionellt ritade experter dessa områden för hand, ett tidskrävande och tröttande arbete som är känsligt för variation mellan observatörer. Under det senaste decenniet har metoder baserade på djupinlärning tagit över mycket av detta arbete, särskilt modeller baserade på konvolutionella neurala nätverk och Transformer-liknande uppmärksamhetsmekanismer. Konvolutionella modeller är duktiga på att fånga fina lokala detaljer såsom kanter, medan Transformermodeller särskilt bra på att fånga bredare kontext över hela bilden. Båda har dock kompromisser: konvolutioner kan missa långdistansrelationer, medan Transformrar ofta kräver kraftig beräkningskapacitet och minne.
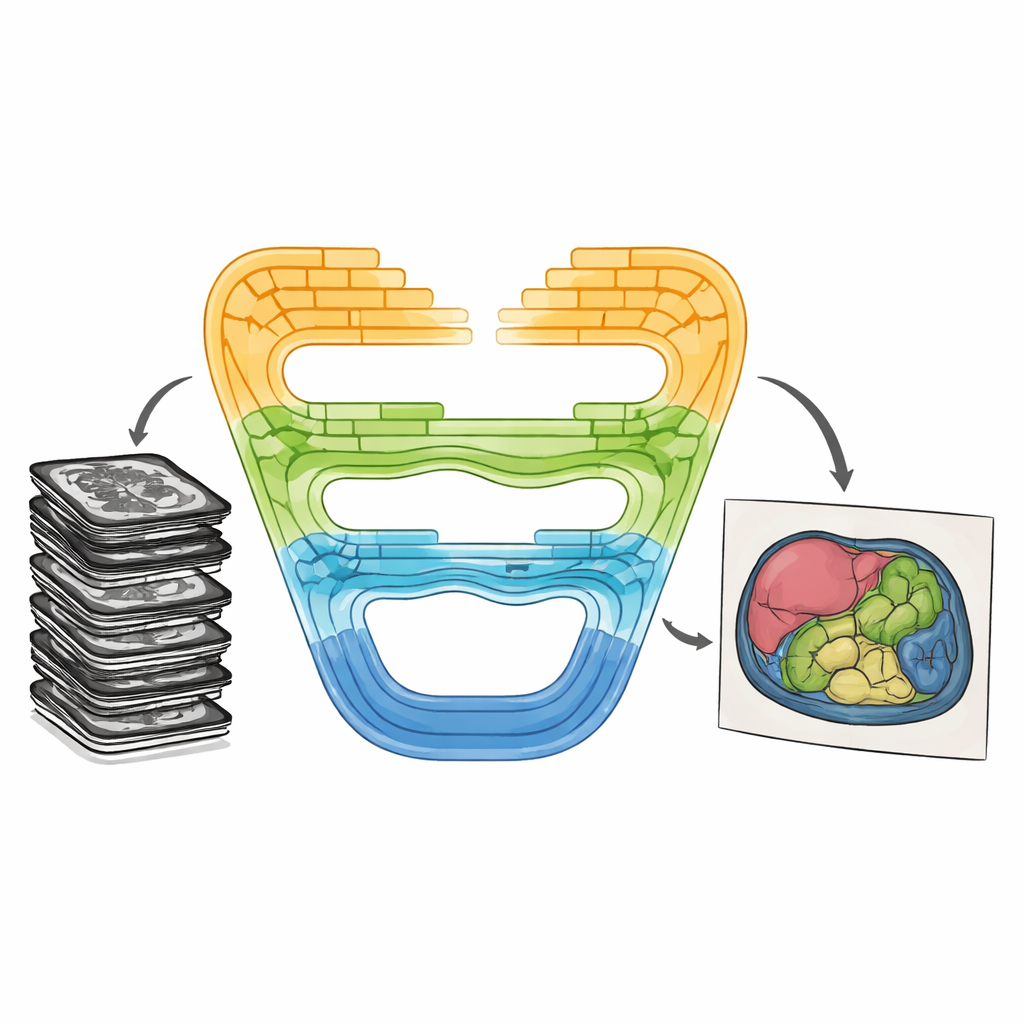
Kombinera styrkor på ett nytt sätt
CMT-Unet tacklar dessa kompromisser genom att väva samman tre typer av byggstenar i en etappvis struktur, istället för att förlita sig på en enda typ genom hela nätverket. I systemets framsida lär en inverterad residual konvolutionsenhet snabbt lokala mönster—skarpa gränser och texturer som hjälper till att skilja intilliggande vävnader. I de mellersta skedena förmedlar en modul baserad på så kallade tillståndsrymdsmodeller, anpassad från en nyare arkitektur kallad Mamba, information längs sekvenser av bildfunktioner på ett sätt som både är kontextmedvetet och beräkningsmässigt sparsamt. Längre in i nätverket delar Transformer-block förbättrade med HiLo-uppmärksamhet informationen i högfrekventa och lågfrekventa komponenter, vilket tillåter modellen att fånga både mycket små detaljer och breda organsformer innan de sammanfogas igen. Denna lagerindelade design speglar den naturliga progressionen från råa pixlar till abstrakt betydelse när bilder bearbetas.
Hur den nya modellen fungerar under huven
I praktiken följer CMT-Unet den välkända U-formade layouten som är populär inom medicinsk bildbehandling: en encoder som komprimerar information till rikare representationer, en decoder som återskapar en prediktion i full storlek, och skip-anslutningar som förmedlar rumslig detalj. Nyckelskillnaden ligger i vilka moduler som används på varje djupnivå. Den tidiga konvolutionsenheten hanterar den finstrukturella information som Mamba- och Transformer-komponenterna annars kan sudda ut. Det modifierade MambaVision-blocket förbättrar sedan mellanlång kontext genom att blanda rumslig information via särskilt utformade tvådimensionella operationer, vilket undviker den tunga kostnaden för full uppmärksamhet samtidigt som det ser bortom lokala patcher. HiLo-uppmärksamhet i Transformer-stadiet separerar uttryckligen skarpa kanter från släta bakgrundsmönster och kombinerar dem på ett sätt som bevarar gränser. Slutligen hjälper en dubbel uppsamplingsmodul i decodern till att rekonstruera rena, kontinuerliga konturer samtidigt som vanliga artefakter som schackrutemönster minskas.
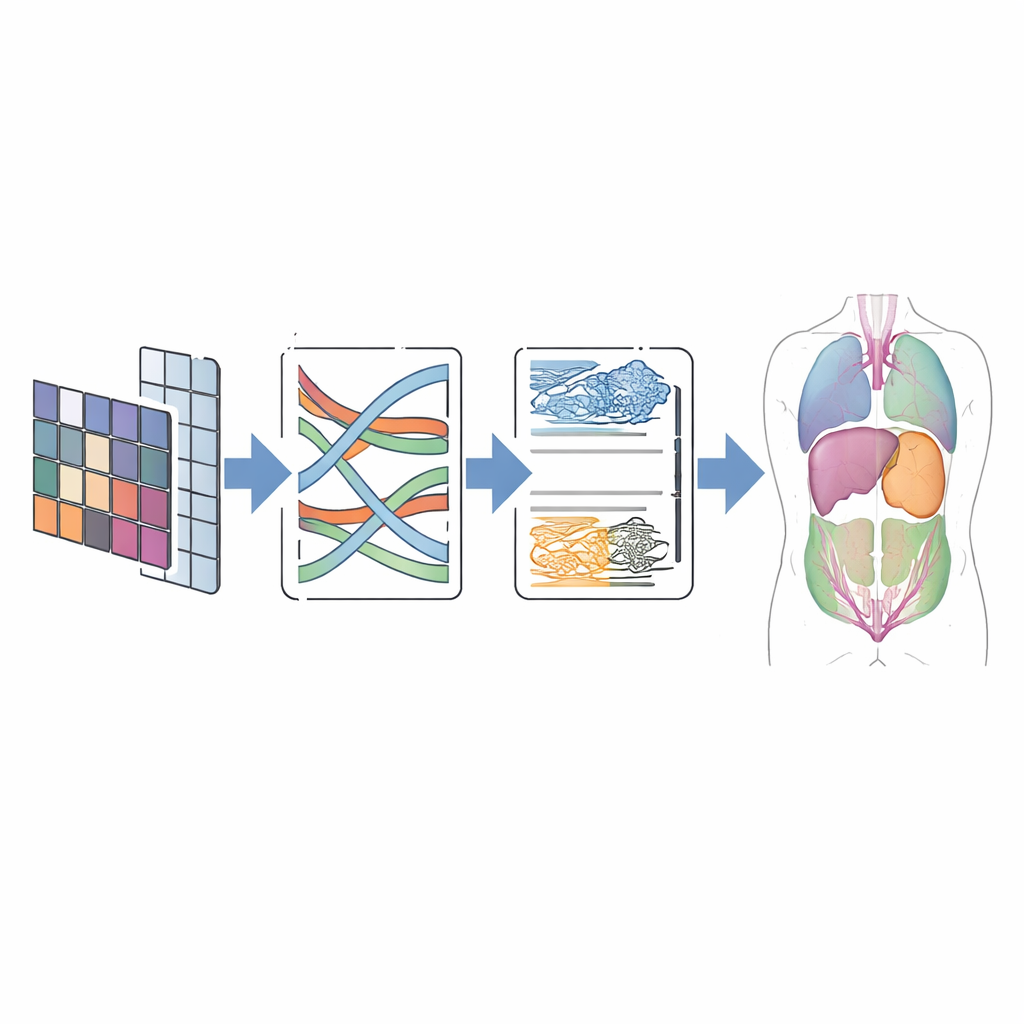
Testning på verkliga avbildningar
För att bedöma om denna design ger resultat testade författarna CMT-Unet på två allmänt använda publika dataset. Det första, kallat Synapse, innehåller abdominala CT-skanningar med åtta märkta organ, inklusive lever, njurar och magsäck. Det andra, ACDC, inkluderar kardiella MRI-bilder med etiketter för hjärtats kammare och muskelvägg. Över dessa benchmarks uppnådde CMT-Unet segmenteringsresultat i nivå med eller bättre än ledande konvolutionella, Transformer- och hybridmodeller, samtidigt som den använde ett måttligt antal parametrar och en hanterbar mängd beräkning. Visuella jämförelser visade mjukare och mer anatomiskt konsekventa gränser, särskilt kring utmanande områden som hjärtats kammare, vilka är avgörande för att mäta funktion och planera ingrepp.
Vad detta betyder för patienter och kliniker
För icke-specialister är huvudslutsatsen att CMT-Unet erbjuder ett smartare sätt att spåra strukturer i medicinska bilder genom att noggrant matcha rätt verktyg till rätt bearbetningssteg. Genom att balansera lokal detalj och global kontext kan modellen producera precisa, rena organskonturer utan att kräva superdatorresurser. Även om det nuvarande arbetet fokuserar på tvådimensionella skanningar och en begränsad uppsättning publika dataset, är tillvägagångssättet lovande för framtida utvidgningar till tredimensionell avbildning och bredare kliniska miljöer. Om det valideras ytterligare skulle denna typ av lättviktsmen ändå precis segmentering kunna stödja snabbare diagnoser, mer pålitlig behandlingsplanering och realtidsstöd i upptagna sjukhusmiljöer.
Citering: Wang, R., Liu, H. & Wang, G. CMT-Unet: leveraging stage-wise hybrid framework for enhanced accuracy and efficiency in medical image segmentation. Sci Rep 16, 10079 (2026). https://doi.org/10.1038/s41598-026-40572-w
Nyckelord: segmentering av medicinska bilder, djupinlärning, hybrida neurala nätverk, tillståndsrymdsmodeller, medicinsk bildbehandling