Clear Sky Science · sv
DPAS: sjukdomsassocierad peptid‑anomalipoäng för identifiering av patogena peptider via one‑class‑inlärning
Varför små proteindelar spelar roll för vår hälsa
Peptider — korta proteinkedjor — har blivit framträdande inom modern medicin. De kan fungera som precisa budbärare i kroppen och används i allt större utsträckning som läkemedel och sjukdomsmarkörer. Att avgöra vilka peptider som verkligen är kopplade till sjukdom bygger dock oftast på att man har tydliga exempel på både ”sjukdoms‑” och ”icke‑sjukdoms”‑peptider, något biologin sällan levererar. Denna studie presenterar ett nytt sätt att upptäcka potentiellt skadliga peptider genom enbart de som redan är kända för att vara involverade i sjukdom, vilket erbjuder en snabbare och mindre biased väg till framtida diagnostik och behandlingar.
Problemet med att hitta gruppen ”icke‑sjukdom”
Traditionella datorbaserade modeller lär sig genom att jämföra två sidor: positiva exempel som är kända för att vara sjukdomsrelaterade och negativa exempel som antas vara ofarliga. Inom peptidforskning är den andra gruppen ett problem. Många peptider har helt enkelt inte testats, så att märka dem som ”icke‑sjukdom” kan vara missvisande och introducera bias. Tidigare studier om anti‑cancer‑ eller anti‑inflammatoriska peptider uppnådde imponerande noggrannhet men byggde ofta på handgjorda eller antagna negativa dataset. Som följd kan deras modeller ha svårt med sällsynta signaler eller nya typer av sjukdomspeptider som inte liknar träningsdata.
Lära av det vi vet, istället för av det vi gissar
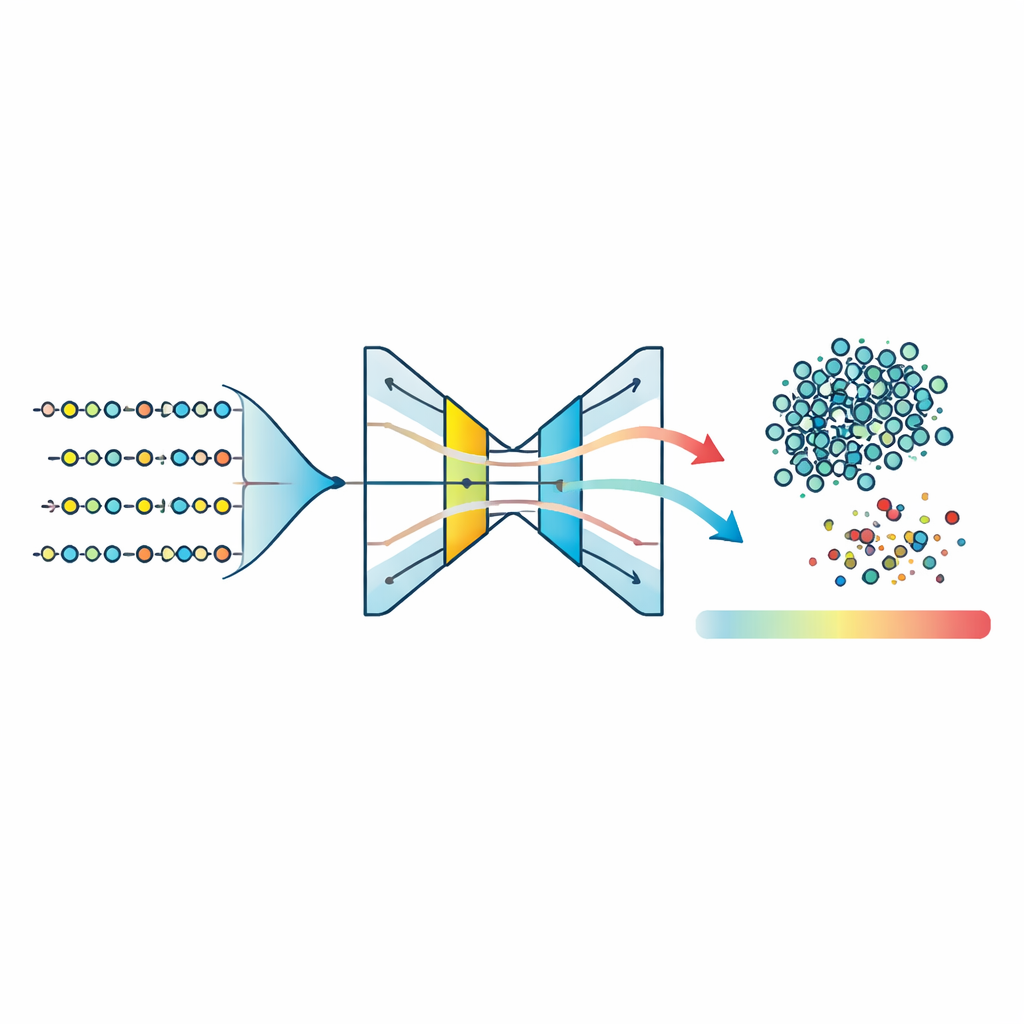
Författarna väljer en annan väg: istället för att tvinga fram ett tvåsidigt problem behandlar de sjukdomsassocierade peptider som en sammanhängande grupp och frågar: ”Hur ser denna grupp ut i detalj?” De samlar in över 760 000 muterade humana peptider från en specialiserad cancerrelaterad databas och beskriver varje peptid med ett rikt uppsättning egenskaper. Dessa inkluderar hur ofta varje aminosyra förekommer, hur aminosyror parar sig, grundläggande fysikaliska och kemiska egenskaper som volym och hydrofil/hydrofob beteende, samt korta återkommande sekvensmönster kända som motiv. En teknik kallad huvudkomponentanalys (PCA) komprimerar sedan denna högdimensionella beskrivning till en mer hanterbar form samtidigt som de viktigaste variationskällorna bevaras.
Upptäcka ovanliga peptider med one‑class‑modeller
Med detta komprimerade featurespace tränar teamet tre ”one‑class”‑modeller — algoritmer utformade för att lära sig formen av en enda grupp och flagga allt som inte passar. De testar One‑Class Support Vector Machines, Isolation Forests och en typ av neuralt nätverk kallat autoencoder. Autoencodern lär sig att pressa varje peptids egenskaper till en smal intern representation och sedan rekonstruera dem; peptider som tillhör det inlärda sjukdomsmönstret återbyggs noggrant, medan ovanliga får högre rekonstruktionsfel. Jämförelse av normaliserade anomalipoäng över metoderna visar att autoencodern ger den tightaste klusteringen av typiska peptider och den klaraste separationen mellan inliers och outliers. Genom att sätta en tröskel på rekonstruktionsfelet kring 95:e percentilen klassificerar modellen majoriteten av peptiderna som sannolikt sjukdomsassocierade samtidigt som en liten andel konsekvent flaggas som atypiska.
Göra komplexa poäng till ett enda meningsfullt tal
För att göra resultaten lättare att tolka biologiskt introducerar författarna Disease Peptide Anomaly Score (DPAS). Denna poäng blandar två komponenter: hur ovanlig en peptid ser ut för autoencodern (dess normaliserade rekonstruktionsfel) och hur starkt dess egenskaper bidrar till prediktioner, mätt med en populär förklaringsmetod kallad SHAP. I praktiken framträder motiv och specifika fysikalisk‑kemiska egenskaper som särskilt informativa. DPAS kombinerar dessa signaler så att peptider som både är strukturellt avvikande och stöds av biologiskt meningsfulla funktioner får högre ranking. De toppskiktade peptiderna undersöks sedan med ett motivsökningsverktyg som kopplar dem till kända funktionella signaturer såsom fosforyleringsställen, metallbindande regioner och andra reglerande mönster som ofta är involverade i signalering och enzymkontroll.
Vad detta innebär för framtida diagnostik och läkemedel
I mer vardagliga termer erbjuder detta arbete ett smartare filter för att hitta misstänkta peptider utan att låtsas att vi vet vilka som definitivt är ofarliga. Genom att enbart lära från bekräftade sjukdomsrelaterade exempel och sedan rangordna nya kandidater med DPAS kan forskare prioritera en kort, biologiskt plausibel lista med peptider för laboratorietestning. Många av de högst rankade kandidaterna innehåller välkända funktionella motiv, vilket stärker idén att de kan spela roller i sjukdomsprocesser. Även om metoden fortfarande vilar på antaganden och saknar experimentellt bevisade ”säkra” peptider för fullständig validering, ger den en mer realistisk och transparent grund för upptäckt av peptidbiomarkörer och kan anpassas till andra biologiska datatyper där tillförlitliga negativa exempel är sällsynta.
Citering: Khalid, Z., Khalid, R. & Sezerman, O.U. DPAS: disease-associated peptide anomaly score for identifying pathogenic peptides via one-class learning. Sci Rep 16, 9170 (2026). https://doi.org/10.1038/s41598-026-40099-0
Nyckelord: sjukdomsassocierade peptider, anomalidetektion, autoencoder, biomarkörupptäckt, one‑class‑inlärning