Clear Sky Science · sv
KM-DBSCAN: ett förbättrat ramverk för gränsdetektion baserat på täthet och centroid för datareduktion mot grön AI
Varför göra AI mindre kan göra den grönare
Artificiell intelligens har en dold kostnad: elektricitet. Att träna moderna maskininlärningsmodeller innebär ofta att bearbeta miljontals datapunkter på strömkrävande hårdvara, vilket i sin tur genererar koldioxidutsläpp. Denna artikel introducerar KM‑DBSCAN, ett nytt sätt att krympa dataset innan träning utan att kasta bort den information modeller faktiskt behöver. Genom att behålla endast de mest informativa exemplaren gör metoden inlärningen snabbare, minskar energianvändningen och bibehåller ändå noggranna prediktioner i uppgifter från handskriven siffrigigenkänning till tidig upptäckt av hudcancer.
För mycket data, för mycket energi
Under år har den dominerande tron inom AI varit att mer data nästan alltid leder till bättre modeller. Även om det kan förbättra noggrannheten innebär det också längre träningstider, större datorer och högre elräkningar. Forskare har börjat skilja mellan ”Red AI”, som jagar noggrannhet till varje pris, och ”Green AI”, som försöker balansera prestanda med miljöpåverkan. En lovande väg mot grönare AI är datareduktion: i stället för att mata modellen med varje tillgängligt exempel, identifiera en mycket mindre uppsättning fall som ändå definierar problemet väl, särskilt de svårhanterliga gränsfallen som avgör en klassificerares beslut.
Att blanda två enkla idéer till ett smart filter
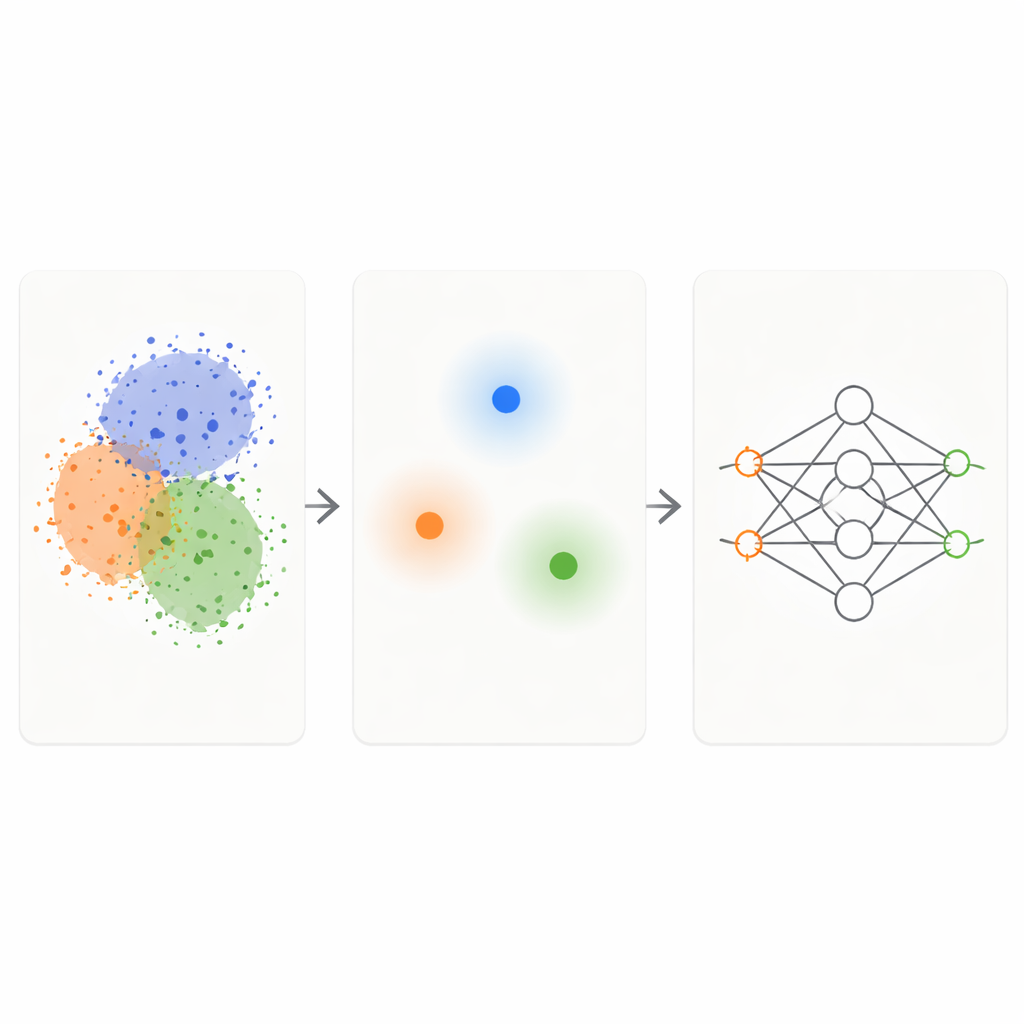
KM‑DBSCAN-ramverket kombinerar två välkända klustringstekniker för att fungera som ett intelligent filter på rådata. Först grupperar en snabb metod kallad K‑Means punkter i kompakta kluster och ersätter varje grupp med en representativ punkt, eller centroid. Detta krymper problemet från tusentals eller miljontals punkter till några hundra representativa. Därefter körs en täthetsbaserad metod (DBSCAN) på dessa centroids för att hitta vilka regioner som ligger vid gränserna mellan kluster och vilka som är täta, homogena inre områden eller isolerat brus. Genom att arbeta på centroidnivå blir DBSCAN mycket snabbare och mindre känslig för pilliga parameterinställningar än när den tillämpas direkt på alla datapunkter.

Endast svåra, informativa fall bevaras
När KM‑DBSCAN har identifierat var olika grupper möts eller överlappar, behåller det endast datapunkterna som ligger nära dessa gränser och kasserar både djupa inre punkter och tydliga avvikare. Inre punkter är i hög grad överflödiga: de ser i stort sett lika dana ut och skickar samma signal till modellen om deras klass. Gränspunkter, däremot, berättar för modellen exakt var en klass slutar och en annan börjar. På syntetiska leksaksdataset reproducerar denna strategi samma beslutsgränser som en klassificerare lär sig från fullständiga data, även när de flesta punkter tas bort. På verkliga dataset som Banana, USPS-siffror, Adult-income-datasetet, fordonskollisionsdata, torra bönsorter och melanombilder bevarar de reducerade mängderna problemets nyckelstruktur samtidigt som de är en storleksordning mindre.
Hastighet, koldioxidbesparing och verkliga tillämpningar
Författarna testade KM‑DBSCAN som ett förarbete till flera populära modeller, inklusive supportvektormaskiner, multilagerperceptroner och konvolutionella neurala nätverk. I många fall var träningen på de reducerade data tiotals till tusentals gånger snabbare samtidigt som noggrannheten nästan bibehölls—och ibland till och med förbättrades något. Till exempel, vid handskriven siffrigigenkänning minskade metoden träningsmängden till endast 1,4% av ursprungsstorleken och ökade ändå noggrannheten något, samtidigt som träningen blev 284 gånger snabbare. I en uppgift för inkomstprediktion med obalanserade klasser uppnåddes en 6907-faldig hastighetsökning med endast ungefär 3% av datan och minimal förlust i noggrannhet. I ett melanomdetektionsexperiment nådde ett djupt neuralt nätverk över 90% noggrannhet medan det tränades på mindre än en tredjedel av det ursprungliga hudbildsdatasetet, med koldioxidutsläpp minskade med mer än 70%.
Vad det betyder för vardaglig AI
För icke‑specialister är huvudbudskapet att smartare urval kan slå ren mängd. KM‑DBSCAN visar att noggrant val av vilka exempel en modell ser—med fokus på de mest informativa gränsfallen—kan kraftigt minska beräkningstid och energianvändning samtidigt som prediktioner förblir pålitliga. Detta tillvägagångssätt passar väl in i den bredare strävan efter Green AI, där dataprestanda och genomtänkt design av träningspipelines betyder lika mycket som rå modellstorlek. Om det antas i stor skala kan sådan data‑medveten filtrering göra allt från medicinsk bildanalys till trafiksäkerhetssystem mer hållbart och göra kraftfulla AI-verktyg tillgängliga för organisationer som saknar massiva beräkningsresurser.
Citering: AboElsaad, M.Y., Farouk, M. & Khater, H.A. KM-DBSCAN: an enhanced density and centroid based border detection framework for data reduction towards green AI. Sci Rep 16, 10349 (2026). https://doi.org/10.1038/s41598-026-40062-z
Nyckelord: grön AI, datareduktion, klustring, effektivitet inom maskininlärning, melanomdetektion