Clear Sky Science · sv
Förbättring av källsignalsparsitet baserat på lokal maxima synkron extraktions-transformalgoritm för blandad matrisuppskattning i UBSS
Att reda ut dolda signaler
Många av de tekniker vi förlitar oss på — trådlösa nätverk, radar, medicinska skannrar och till och med smarta mikrofoner — måste urskilja svaga signaler som är hopplöst blandade. Föreställ dig att försöka följa flera samtal samtidigt i ett fullt kafé med bara två öron. Denna artikel presenterar ett nytt sätt att "reda ut" sådana överlappande signaler när det finns färre sensorer än källor, en berömdt svår situation. Genom att skärpa hur vi betraktar signaler i tid och frekvens, och genom att förbättra hur datorer grupperar relaterad data, visar författarna att de kan separera blandningar mer precist och mer tillförlitligt, även i brusiga verkliga förhållanden. 
Varför blandade signaler är så svåra att separera
I många system färdas flera oberoende signaler genom samma kanal och fångas upp av ett litet antal mottagare. Denna situation, kallad underbestämd blind källa-separation, innebär att det finns fler okända signaler än mätningar. Klassiska metoder för signalseparation antar vanligtvis motsatsen, så de fallerar här. Ett viktigt modernt knep är att utnyttja sparsitet: i en lämplig representation är varje källa aktiv endast vid få ögonblick eller frekvenser. Om, vid de flesta tidpunkter, bara en källa dominerar, bildar molnet av observerade data naturligt kluster vars riktningar kodar hur varje källa blandats in i mottagarna. Att hitta dessa kluster noggrant beror dock på att ha en representation där energin för varje källa är skarpt koncentrerad snarare än utsmetad.
Skärpa bild av en signal
För att avslöja sparsitet omvandlar ingenjörer ofta signaler till en tids–frekvensbild som visar vilka toner som förekommer vid vilka tidpunkter. Den enkla korttids-Fouriertransformen gör detta genom att glida ett fönster längs tiden och ta många små spektra, men den suddar ut energi och kan inte samtidigt ge skarp tidsupplösning och exakt tonhöjd. Mer avancerade varianter som synchrosqueezing och synchroextracting försöker dra ut spridd energi mot den ås som följer en signals momentanfrekvens. Dessa metoder förbättrar fokus, men förblir känsliga för brus: när slumpmässiga störningar komprimeras längs samma åsar som signalen kan resultatet bli ett ljust men suddigt band som döljer fin struktur.
Hitta lokala toppar för att öka sparsiteten
Byggt på dessa idéer introducerar författarna Local Maximum Synchroextracting Transform, eller LMSET. I stället för att trycka all närliggande energi mot en frekvensåse skannar LMSET tids–frekvensplanet och låser, för varje ögonblick, fast vid lokala toppar längs frekvensaxeln. Endast koefficienter runt dessa lokala maxima behålls och omfördelas, medan resten undertrycks. Denna enkla förändring ger en representation där energin för varje komponent signal är koncentrerad i tunna, rena kurvor med betydligt färre spridda punkter. Genom simuleringar med mångkomponents testsignaler ger LMSET den lägsta Rényi-entropin, en standardmått på koncentration, och överträffar konventionella och toppmoderna metoder över ett brett spektrum av brusnivåer. Kort sagt ger LMSET en tydligare bild av var varje signal befinner sig i tid och frekvens.
Smartere gruppering för att lära sig den dolda blandningen
En skarpare bild är bara halva striden; nästa steg är att klustra de resulterande punkterna för att uppskatta den okända blandningsmatrisen som beskriver hur varje källa bidrar till varje mottagare. Många tillvägagångssätt förlitar sig på fuzzy C-means, en populär klustringsmetod som ofta fastnar i dåliga lösningar eftersom den är mycket känslig för sin startgissning och för avvikande datapunkter. För att övervinna dessa svagheter parar författarna LMSET med ett nytt, mer robust klustringsschema. De använder först en PID-baserad sökalgoritm, inspirerad av reglerteknik, för att utforska hela rummet av möjliga klustercentra och undvika dåliga startpositioner. Därefter introducerar de en boolesk viktmekanism för att nedtona avvikare och använder en informationsentropistrategi som minskar känsligheten för begynnelsevillkor. Tillsammans gör dessa steg att klustringen kan låsa sig på de sanna riktningarna för de dolda källorna mer konsekvent.
Vad testerna avslöjar
Författarna testar hela sin kedja — LMSET plus den förbättrade klustringen — på blandningar av digitalt modulerade kommunikationssignaler, inklusive QAM, QPSK och FSK, i både tysta och brusiga miljöer. De jämför de uppskattade blandningsmatriserna med de verkliga med hjälp av vinkelavvikelse och normaliserat medelkvadratfel. Över hela linjen minskar användningen av LMSET istället för en traditionell transform felmarginalerna, eftersom datapunkterna bildar tätare, mer distinkta kluster. Bland klustringsmetoderna uppnår den föreslagna PID-optimerade robusta fuzzy C-means de minsta genomsnittliga vinkelavvikelserna och de bästa felvärdena. Sammantaget förbättrar den kombinerade metoden noggrannheten i uppskattningen av blandningsmatrisen med nästan 20 procent jämfört med konventionella tillvägagångssätt, samtidigt som den bibehåller stark prestanda även vid höga brusnivåer. 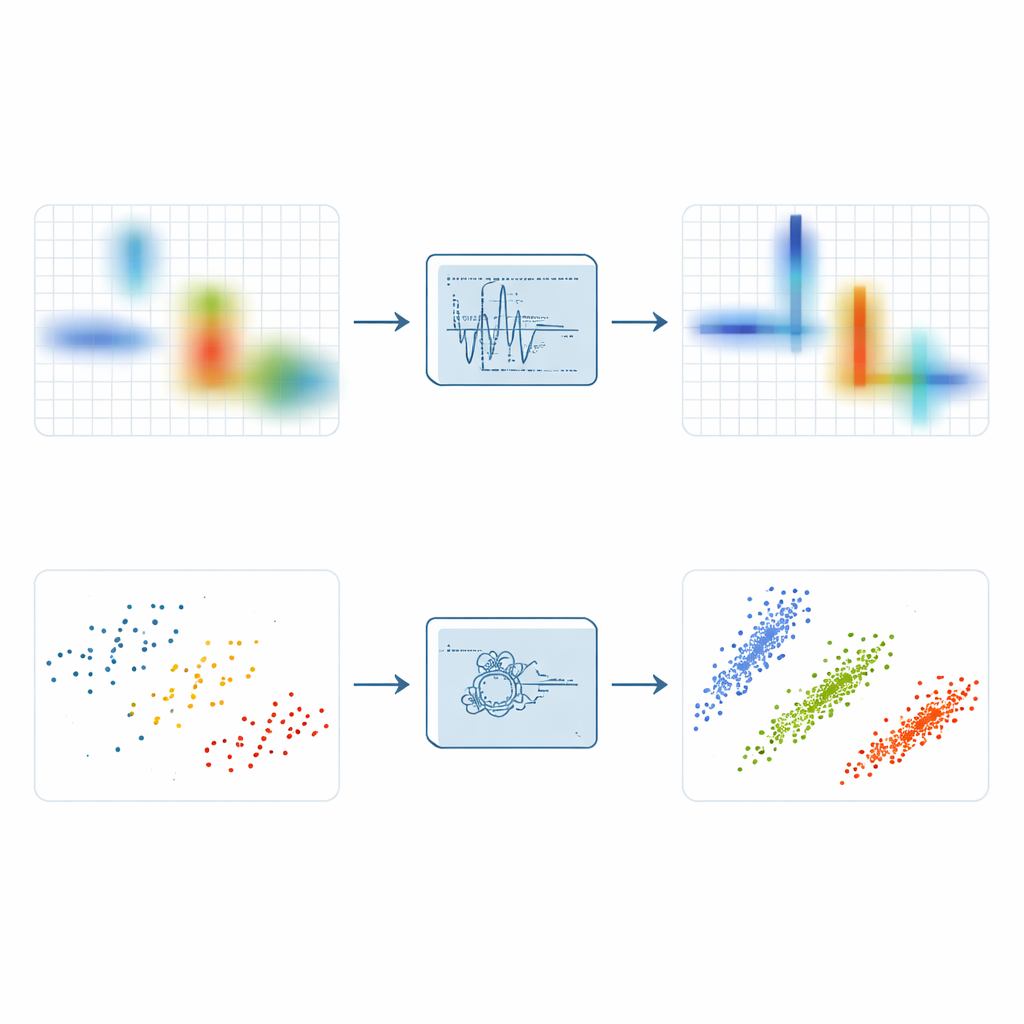
Varför detta betyder något bortom teorin
För icke-specialister är huvudpoängen att författarna har funnit ett bättre sätt att betrakta och gruppera intrasslade signaler så att varje ursprunglig ström kan återhämtas renare. Genom att fokusera på lokala toppar i tids–frekvenslandskapet och kombinera denna vy med en noggrannare klustringsstrategi gör deras metod det omöjliga kaféproblemet — många röster, för få öron — något mer lösbart. Denna framsteg kan gynna tillämpningar från satellitlänkar som måste separera överlappande sändningar till medicinska system som behöver isolera svaga biologiska signaler begravda i brus, och därigenom erbjuda klarare information från samma begränsade mätningar.
Citering: Li, X., Li, Z., Yao, R. et al. Source signal sparsity enhancement based on local maximum synchronous extraction transform algorithm for mixed matrix estimation in UBSS. Sci Rep 16, 9378 (2026). https://doi.org/10.1038/s41598-026-40055-y
Nyckelord: blind källa-separation, signalsparsitet, tids–frekvensanalys, klustringsalgoritmer, trådlös kommunikation