Clear Sky Science · sv
De novo-generering och in silico-screening av kandidatpeptider mot diabetes via ett djupinlärnings–attention-ramverk med fusion av fysikaliskt-kemiska egenskaper
Varför smartare peptiddesign spelar roll för diabetes
Diabetes påverkar hundratals miljoner människor globalt och dagens läkemedel fungerar inte perfekt för alla. Många behandlingar tappar effekt över tid eller ger bieffekter. Ett lovande nytt alternativ är en klass små proteiner kallade anti-diabetiska peptider, som kan finjustera blodsocker med hög precision. Utmaningen är att hitta nya peptidläkemedel i laboratoriet är långsamt och kostsamt. Den här studien presenterar en datorstyrd pipeline som kan skapa och sålla bland stora mängder potentiella anti-diabetiska peptider och peka forskare mot de mest lovande kandidaterna att testa i verkliga världen.
Från kända diabetespeptider till ren startdata
Forskarna började med att sätta ihop en högkvalitativ samling peptider som experimentellt visats påverka blodsocker, främst genom att påverka hormoner som GLP-1 eller enzymer som DPP-IV. Dessa utgjorde de "positiva" exemplen. Därefter byggde de en matchande "negativ" uppsättning peptider utan rapporterad anti-diabetisk aktivitet, noggrant utvalda så att längd, sammansättning och grundläggande kemi liknade de positiva. För att undvika att lura modellen med nästintill identiska sekvenser använde de verktyg för sekvenslikhet för att säkerställa att nära besläktade peptider aldrig förekom i både tränings- och testgrupperna. Denna homologimedvetna uppdelning säkerställde att systemet bedömdes efter sin förmåga att känna igen verkligt nya mönster snarare än att memorera gamla.
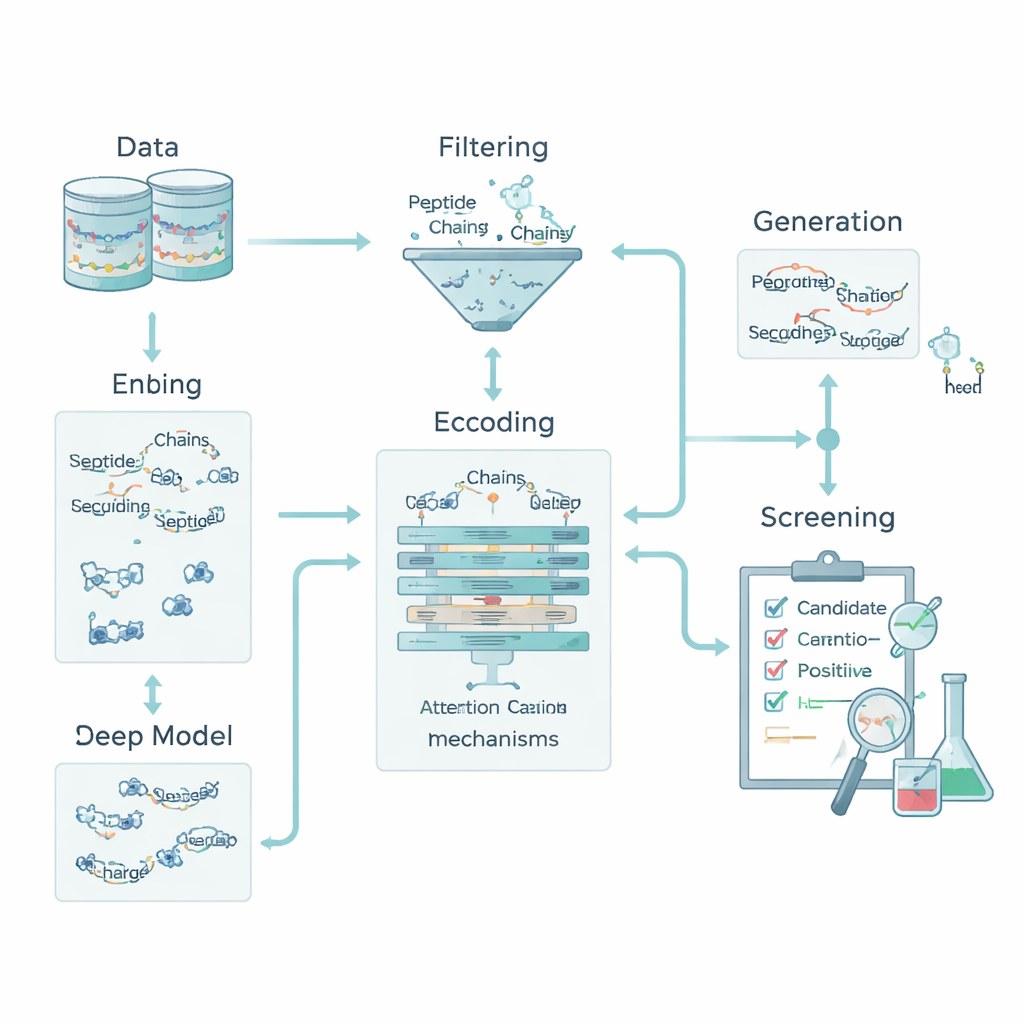
Koda kemin så att maskiner kan läsa peptider
För en dator är en peptid bara en sträng av bokstäver som representerar aminosyror. För att koppla dessa bokstäver till biologi transformerade teamet varje aminosyra till fem grundläggande kemiska egenskaper: hur vattenavvisande den är, dess elektriska laddning, dess benägenhet att bilda vätebindningar, dess massa och huruvida den har en aromatisk ring. Detta omvandlade varje peptid till en liten "bild" som fångar både ordning och kemi. Utöver detta lade de till helpeptidbeskrivare såsom total laddning, genomsnittlig hydrofobicitet och Boman-indexet, som relaterar till hur starkt en peptid tenderar att binda till andra proteiner. Tillsammans låter dessa egenskaper modellen betrakta både lokala mönster—kortare aminosyramotiv—och globala egenskaper som påverkar hur en peptid beter sig i kroppen.
Ett djupinlärningsmotor som förklarar sina val
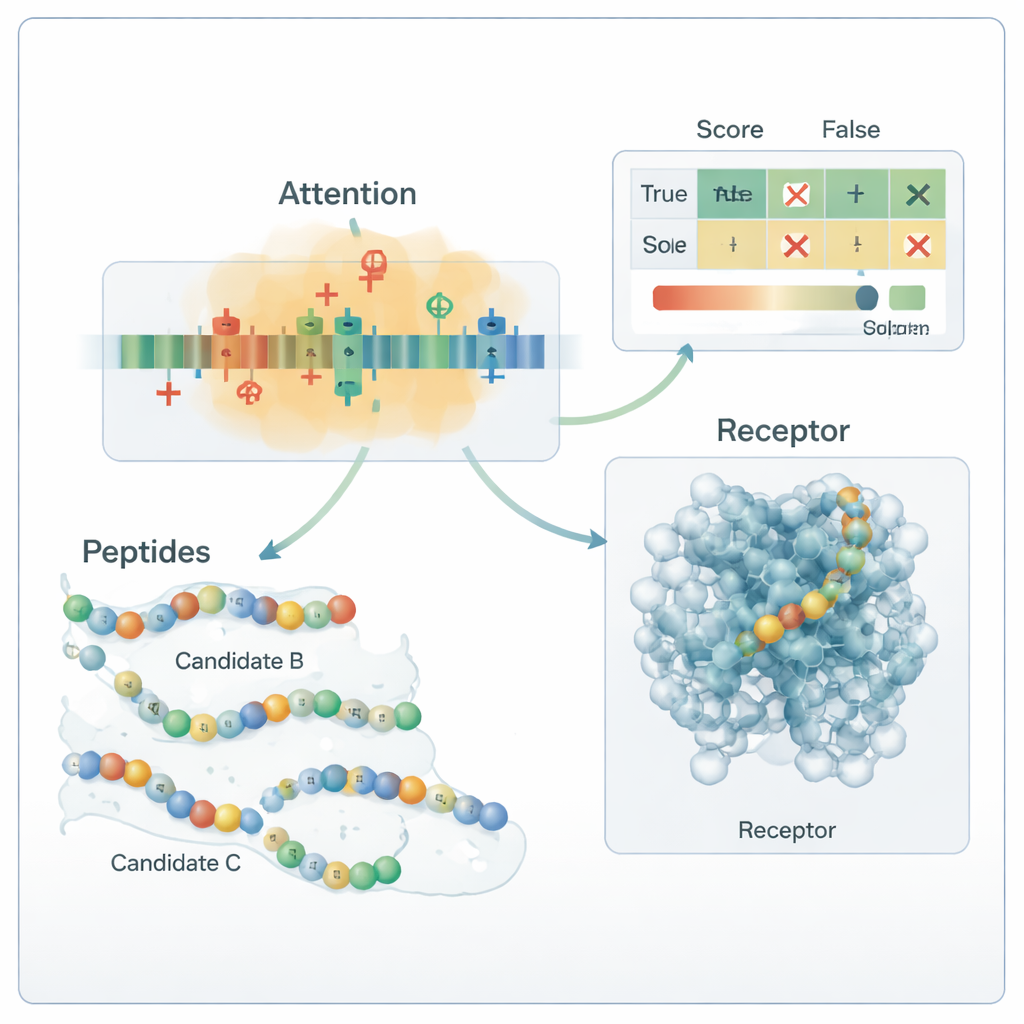
Kärnan i pipelinen är en hybrid djupinlärningsmodell. Ett konvolutionellt neuralt nätverk (CNN) skannar längs peptiden och letar efter korta motiv som tenderar att förekomma i aktiva peptider, likt filter i ett bildigenkänningssystem. Utöver det lär ett attention-lager vilka positioner i sekvensen som betyder mest, och fångar långdistansrelationer mellan avlägsna rester. Output från denna sekvensmotor fusioneras med de globala kemiska beskrivarna och skickas till flera standardmaskininlärningsklassificerare—support vector machines, besluts-träd, k-närmaste grannar och gradientförstärkta träd. En specialiserad optimeringsmetod, kallad OptimizedTPE, finjusterar automatiskt deras inställningar och avväger noggrannhet mot risken för överanpassning. Attention-mekanismen ger också restnivå "viktskartor" som hjälper forskare att se vilka delar av varje peptid som driver modellens beslut.
Skapa nya kandidater samtidigt som dataläckage undviks
För att övervinna det begränsade antalet kända anti-diabetiska peptider lade teamet till ett generatorskede som endast matar träningsprocessen. De använde en blandning av strategier—styrda mutationer, motivationsrekommendation (motif recombination) och en variational autoencoder—för att föreslå nya sekvenser som liknar, men inte kopierar, kända aktiva peptider. Dessa kandidater genomsöktes sedan genom strikta "deskriptorgates" som säkerställer realistisk laddning, storlek och bindningstendens, plus externa verktyg som poängsätter likhet med kända bioaktiva peptider. Endast sekvenser som passerade dessa filter och förblev tydligt skilda från alla testpeptider behölls som svagt etiketterade positiva för träning; ingen användes någonsin för att utvärdera modellen. Detta tillvägagångssätt utvidgade träningsmängden samtidigt som en ren, opartisk testmiljö bevarades.
Hur väl systemet fungerar och vad det innebär
När systemet utmanades med en helt oberoende panel om 180 experimentellt studerade peptider insamlade från nyare litteratur, klassificerade ramverket korrekt ungefär 99 av 100 sekvenser, med både precision och recall nära 0,99. I praktiska termer betyder det att det sällan missar en riktig anti-diabetisk peptid och sällan kallar en inaktiv peptid lovande. Analys av attention-kartor och mutationstester visade att modellen lärt sig kemiskt rimliga regler: den förlitar sig tungt på positivt laddade och vissa hydrofoba rester som är kända för att vara viktiga för bindning till diabetesrelaterade mål. Molekylära dockningssimuleringar antydde vidare att några av de nygenererade peptiderna kan skapa trovärdiga kontakter med den humana GLP-1-receptorn. Även om dessa förutsägelser fortfarande kräver laboratoriebekräftelse, visar studien ett reproducerbart, biologiskt grundat sätt att utforska det enorma rummet av möjliga peptidläkemedel och prioritera de få som mest sannolikt kan hjälpa till att hantera diabetes.
Citering: Asl, Z.R., Rezaee, K., Ansari, M. et al. De novo generation and in silico screening of anti-diabetic peptide candidates via a deep learning–attention framework with physicochemical feature fusion. Sci Rep 16, 6580 (2026). https://doi.org/10.1038/s41598-026-39985-4
Nyckelord: anti-diabetiska peptider, djupinlärning, Läkemedelsupptäckt, peptiddesign, GLP-1-receptorn