Clear Sky Science · sv
R-GAT: klassificering av cancerartiklar som utnyttjar grafbaserat residualnätverk för scenarier med begränsade data
Varför det spelar roll att sortera cancerartiklar
Varje dag publicerar forskare hundratals nya studier om cancer, från tidig upptäckt till lovande läkemedel. Det mesta av detta arbete publiceras först som korta sammanfattningar kallade abstrakt. Läkare, forskare och beslutsfattare kan inte läsa allt, och att missa en viktig artikel kan göra att framsteg fördröjs. Denna studie tar sig an en enkel men kraftfull fråga: kan vi bygga ett snabbt, lättviktigt datorbaserat system som automatiskt sorterar cancerrelaterade abstrakt efter cancerns typ, även när endast en begränsad mängd märkta data och beräkningsresurser finns tillgängliga?
Ett smartare sätt att läsa cancerforskning
Författarna fokuserar på fyra typer av abstrakt som finns i PubMed-databasen: de om sköldkörtelcancer, tjocktarmscancer, lungcancer och mer allmänna biomedicinska ämnen. De skapade en noggrant kontrollerad samling på 1 875 nyare abstrakt, ungefär jämnt fördelade över de fyra grupperna. Denna balans hjälper till att undvika partiskhet mot någon enskild cancertyp. Innan modellering genomfördes rensades texterna: ord delades upp i token, stavning kontrollerades, relaterade ordformer slog samman och oinformativa termer togs bort. De rensade abstrakten konverterades sedan till numerisk form med flera standardmetoder så att olika typer av modeller kunde jämföras rättvist.
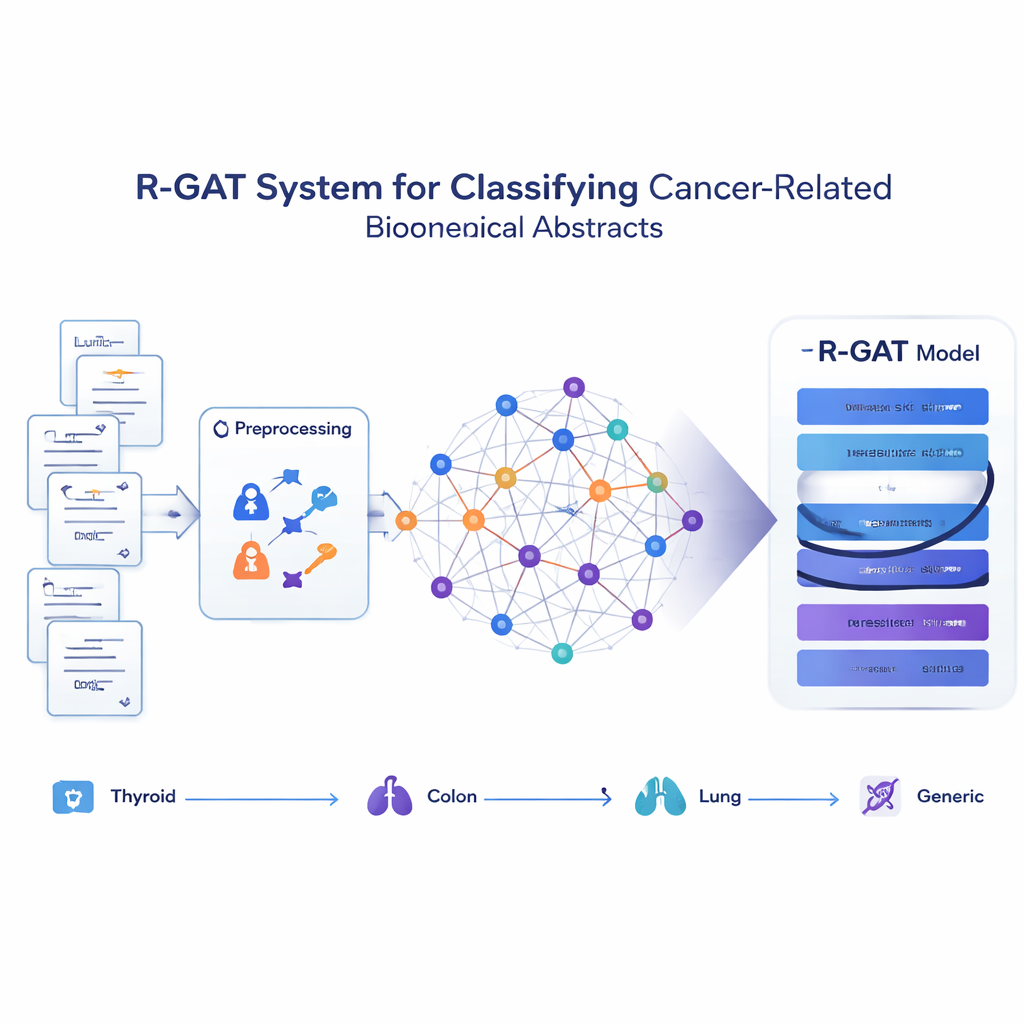
Att förvandla artiklar till ett nätverk av idéer
I stället för att behandla varje abstrakt som en isolerad ordsträng ser den föreslagna metoden, kallad R-GAT (Residual Graph Attention Network), hela samlingen som ett nätverk. I detta nätverk är varje abstrakt en nod, och förbindelserna representerar hur lika två abstrakt är i innehåll. Om två artiklar behandlar nära besläktade ämnen är länken mellan dem stark; om inte är den svag eller obefintlig. Detta låter modellen betrakta ett abstrakt i kontexten av dess grannar, vilket efterliknar hur en mänsklig läsare kan förstå en studie bättre genom att känna till vad närliggande arbete säger.
Hur den nya modellen lär av grannar
R-GAT bygger på två centrala idéer från modern artificiell intelligens: attention och residualkopplingar. Attention gör det möjligt för modellen att lägga mer vikt vid de mest relevanta angränsande abstrakten i nätverket, i stället för att behandla alla grannar lika. Flera attention‑"huvuden" letar efter olika typer av mönster samtidigt. Residualkopplingar fungerar som genvägar som för vidare information genom nätverkets djupare lager och hjälper modellen att undvika att viktiga signaler går förlorade under inlärningen. Efter att grafen processats genom flera attentionlager och dessa genvägar kondenserar systemet information från hela nätverket till en kompakt sammanfattning som matas till en slutgiltig klassificerare som förutspår vilken av de fyra kategorierna varje abstrakt tillhör.
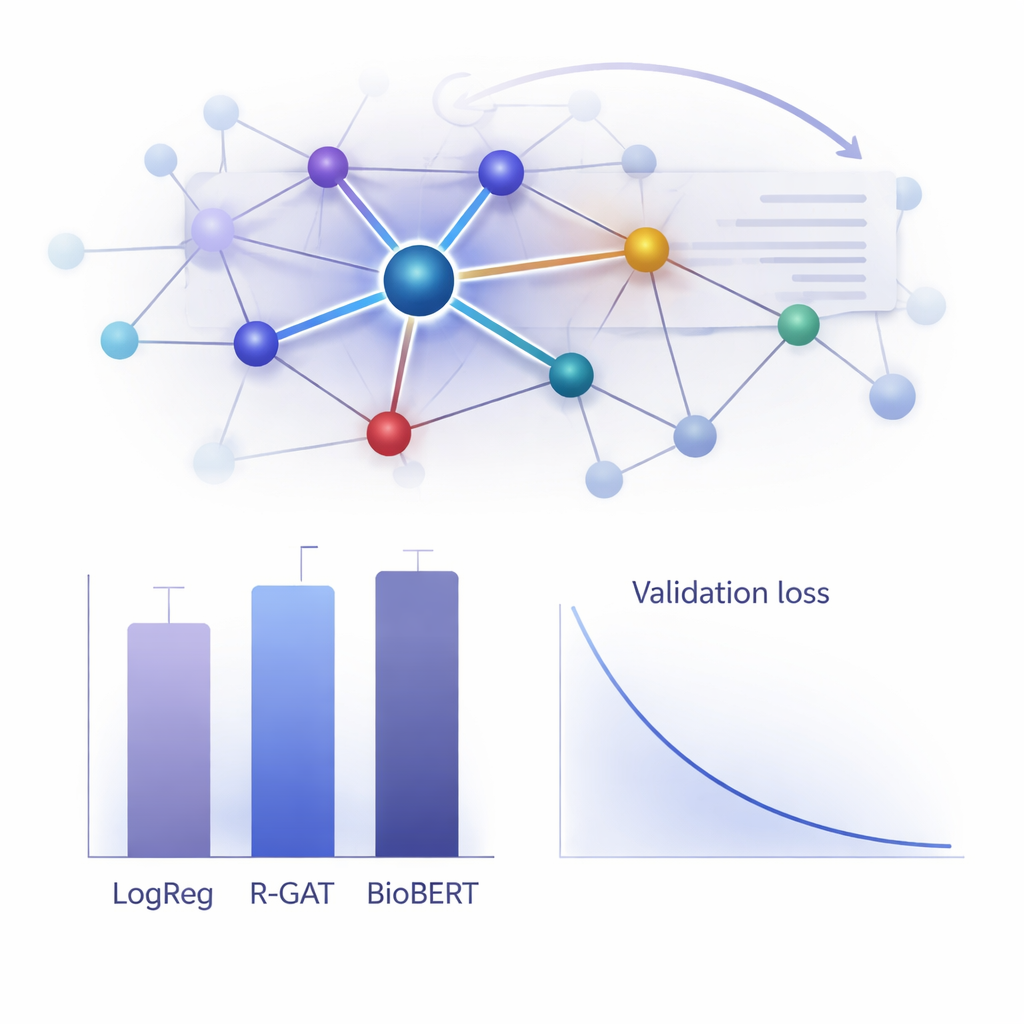
Hur bra fungerar det i praktiken?
För att bedöma värdet av R-GAT jämförde författarna det med ett brett spektrum av alternativ, från klassiska linjära modeller till toppmoderna transformermodeller som BioBERT, som är populära men beräkningsmässigt tunga. Förvånande nog uppnådde en enkel logistisk regressionsmodell som använde ord-räkningsfunktioner den högsta råa poängen på denna specifika dataset, och BioBERT presterade också mycket bra — men båda hade nackdelar, inklusive beroende av specifika funktionsval eller behovet av betydande beräkningsresurser. R-GAT nådde ett makro F1‑värde på cirka 0,96, nära de bästa modellerna, samtidigt som det visade mycket stabila resultat över olika tränings–test‑uppdelningar. Omsorgsfulla tester där attention eller residualkopplingar tagits bort visade tydliga prestandaförsämringar, vilket bekräftar att båda komponenterna är avgörande för modellens robusthet när datamängderna är begränsade.
Vad detta betyder för framtida cancerforskning
För en lekman är slutsatsen tydlig: R-GAT är ett praktiskt verktyg som hjälper till att sortera cancerforskningsartiklar efter cancertyp med hög och konsekvent noggrannhet, utan att kräva jättelika dataset eller dyr hårdvara. Det ersätter inte de kraftfullaste språkmodellerna på marknaden, men erbjuder en pålitlig mellanväg — särskilt användbar för sjukhus, forskargrupper eller folkhälsoteam som behöver tillförlitliga, reproducerbara resultat under knappa data‑ och budgetförhållanden. Genom att öppet publicera både sin modell och sin kuraterade dataset ger författarna också en gemensam referenspunkt som andra kan använda för att bygga och testa förbättrade system. På längre sikt kan sådana verktyg göra det mycket enklare för experter att hålla sig à jour med cancerlitteraturen och omsätta nya fynd i bättre vård.
Citering: Hossain, E., Nuzhat, T., Masum, S. et al. R-GAT: cancer document classification leveraging graph-based residual network for scenarios with limited data. Sci Rep 16, 6582 (2026). https://doi.org/10.1038/s41598-026-39894-6
Nyckelord: cancerinformatik, biomedicinsk textutvinning, dokumentklassificering, grafneuronätverk, inlärning med begränsade data