Clear Sky Science · sv
Maskininlärning för att förutsäga CKD‑stadier hos patienter med autosomal dominant polycystisk njursjukdom: en landsomfattande kohortstudie i Japan
Varför detta är viktigt för vardagshälsan
Njursjukdom smyger ofta på utan märkbara symtom, och när tecken väl uppträder kan skador vara svåra att vända. För personer födda med autosomal dominant polycystisk njursjukdom (ADPKD) — ett tillstånd där vätskefyllda blåsor gradvis tränger ut normal njurvävnad — kan kunskap om hur snabbt njurarna kan försämras påverka stora livsbeslut. Denna studie undersöker om moderna datormetoder, kända som maskininlärning, kan använda rutinmässiga hälsokontrolluppgifter för att förutsäga hur en persons njurfunktion kommer att förändras under de kommande tre åren, utan att förlita sig på kostsamma genetiska tester eller avancerade skanningar.
En vanlig sjukdom med osäker framtid
ADPKD är en av de vanligaste ärftliga njursjukdomarna och en ledande orsak till kronisk njursjukdom (CKD). Många drabbade behöver så småningom dialys eller transplantation, men försämringstakten varierar stort. Vissa utvecklas långsamt och behåller rimlig njurfunktion upp i hög ålder; andra når njursvikt i 40‑ eller 50‑årsåldern. Läkare vill tidigt kunna sortera patienter i riskgrupper så att behandling och uppföljning kan anpassas. Befintliga prediktionsverktyg bygger ofta på detaljerade genetiska tester eller fullständiga MR‑undersökningar av njurarna, vilket inte finns tillgängligt rutinmässigt i många vårdsystem, inklusive Japans nationella försäkringsprogram. Denna lucka motiverade författarna att söka ett enklare, mer allmänt användbart sätt att bedöma framtida CKD‑stadium.
Att omvandla ett nationellt register till ett prediktionsverktyg
Forskarlaget använde ett nationellt japanskt register som dokumenterar information från personer med svårbehandlade sjukdomar som får statligt stöd. De fokuserade på 2 737 vuxna med ADPKD som först registrerades mellan 2015 och 2021. För varje person samlade teamet data från den initiala ansökan — inklusive blodprover, urinfynd, grundläggande kroppsmått, blodtryck och läkarens anteckning om njurstorlek — och tittade sedan på personens CKD‑stadium tre år senare. CKD‑stadiet, som huvudsakligen baseras på hur väl njurarna filtrerar blod, fungerar både som en markör för sjukdomens svårighetsgrad och som ett centralt kriterium för ekonomiskt stöd i Japan.
Hur datorerna lärde sig från patientdata
För att bygga sitt prediktionssystem testade forskarna tre vanliga maskininlärningsmetoder: random forest, support vector machine och naïve Bayes. Alla tre lär sig från exempel snarare än från fasta formler. Datamängden delades upp i en träningsdel, som användes för att finjustera varje modell, och en testdel, som användes för att kontrollera hur väl de slutliga modellerna presterade på oinspelade fall. Datorerna försökte förutsäga vilket av flera CKD‑stadier varje patient skulle nå efter tre år. Random forest‑metoden, som kombinerar många enkla beslutsträd till ett röstningskommitté, visade bäst prestanda och förutsade stadiet korrekt för ungefär 73 % av testpatienterna. Support vector machine, som i huvudsak antar linjära samband mellan faktorer och utfall, presterade sämre, medan den enkla naïve Bayes‑modellen befann sig däremellan.
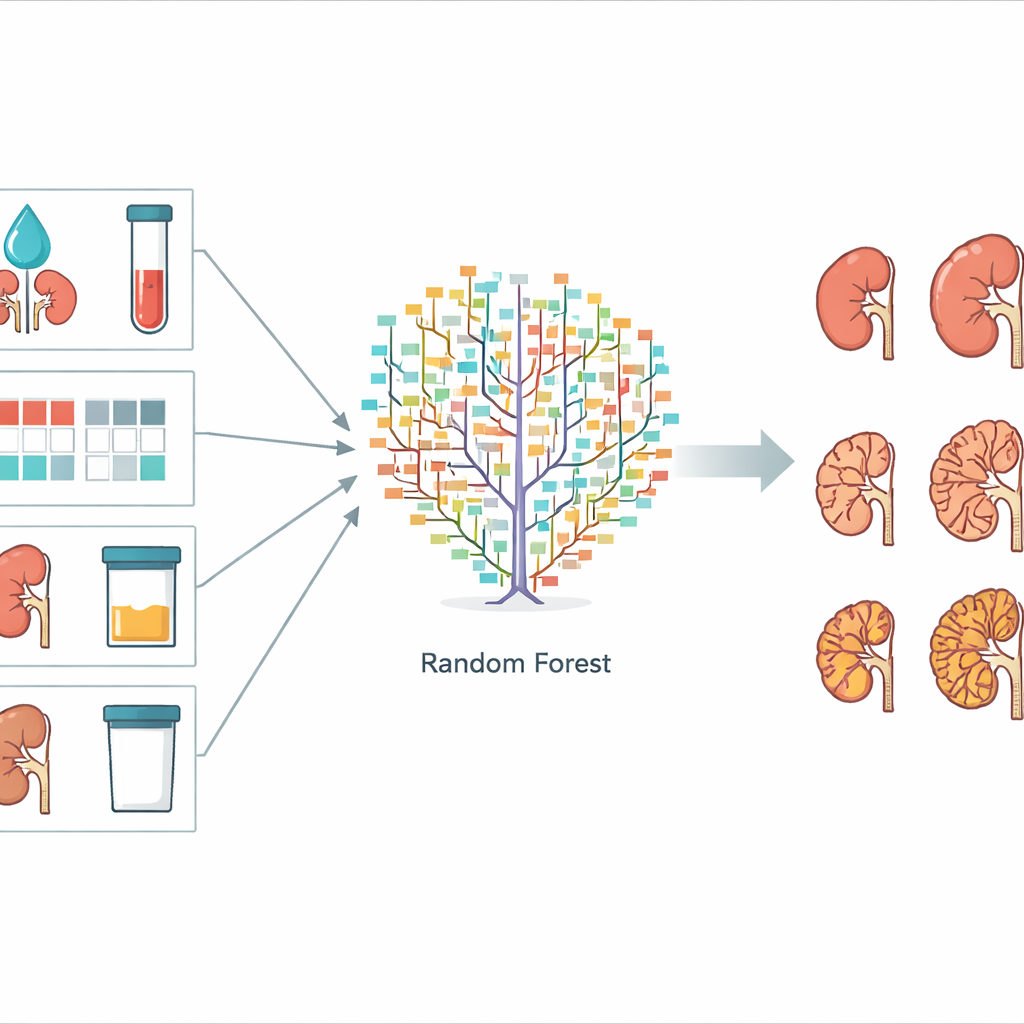
Vad som betydde mest för förutsägelsen
Teamet undersökte också vilka uppgifter som var mest användbara för random forest‑modellen. De mätte detta genom att på ett i taget slumpa om en faktor och se hur mycket prognoserna försämrades. Fem variabler stack ut som särskilt viktiga: den uppskattade filtreringshastigheten i njurarna (eGFR), kreatininnivån i blodet (en annan markör för njurfunktion), en färgkodas CKD‑"värmekarta" som kombinerar filtrering och urinproteinfynd, mängden protein i urinen och den totala volymen av båda njurarna. Dessa är alla mätningar som kan samlas in vid vanliga klinikbesök, utan specialiserade bildfiler eller genanalyser. Andra uppgifter, såsom det exakta antalet cystor som ses på skanningar, bidrog lite och tyder på att de inte är nödvändiga för ett praktiskt prediktionsverktyg.
Vad detta innebär för patienter och läkare
För personer som lever med ADPKD antyder studien att en noggrant tränad datormodell, matad med standardlaboratorietester och grundläggande bildsammanfattningar, kan ge en relativt korrekt prognos för njurhälsa tre år framåt. Eftersom den bäst presterande modellen kan fånga komplexa, icke‑linjära samband mellan faktorer kan den vara bättre lämpad än traditionella risktabeller för denna livslånga, varierande sjukdom. Arbetet är begränsat till japanska patienter och kan inte bevisa orsakssamband, men det pekar mot klinikvänliga verktyg som hjälper till att identifiera vilka som sannolikt försämras snabbt och vilka som kan ha en långsammare förlopp. Enkelt uttryckt drar artikeln slutsatsen att maskininlärning — särskilt random forest‑ansatsen — kan omvandla vardagliga medicinska data till individualiserade förhandsvisningar av njurarnas framtid, vilket stödjer mer personanpassad vård och bättre planering för patienter med ADPKD.
Citering: Shimada, Y., Kataoka, H., Nishio, S. et al. Machine learning for predicting CKD stages in patients with autosomal dominant polycystic kidney disease: a nationwide cohort study in Japan. Sci Rep 16, 8771 (2026). https://doi.org/10.1038/s41598-026-39885-7
Nyckelord: polycystisk njursjukdom, kronisk njursjukdom, maskininlärning, riskbedömning, personlig medicin