Clear Sky Science · sv
EchoNet++: En flerspråkig dataset för ljudkommentarer av fotbollsmatcher
Varför fotbollsljud spelar roll
Alla som sett en stor match vet att publikens dån och kommentatorns röstläge är lika mycket en del av dramatiken som målen själva. Ändå fokuserar nästan all modern sportsteknik fortfarande på vad kamerorna ser, inte på vad mikrofonerna hör. Denna artikel introducerar EchoNet och EchoNet++, ett kombinerat system och dataset som förvandlar det kaotiska ljudet från professionella fotbollssändningar i många länder till ren, sökbar text som datorer kan analysera. Det gör det möjligt att studera taktik, känslor och berättande över ligor och språk i en skala som inget mänskligt översättarteam kan matcha.
Från bullriga arenor till ren signal
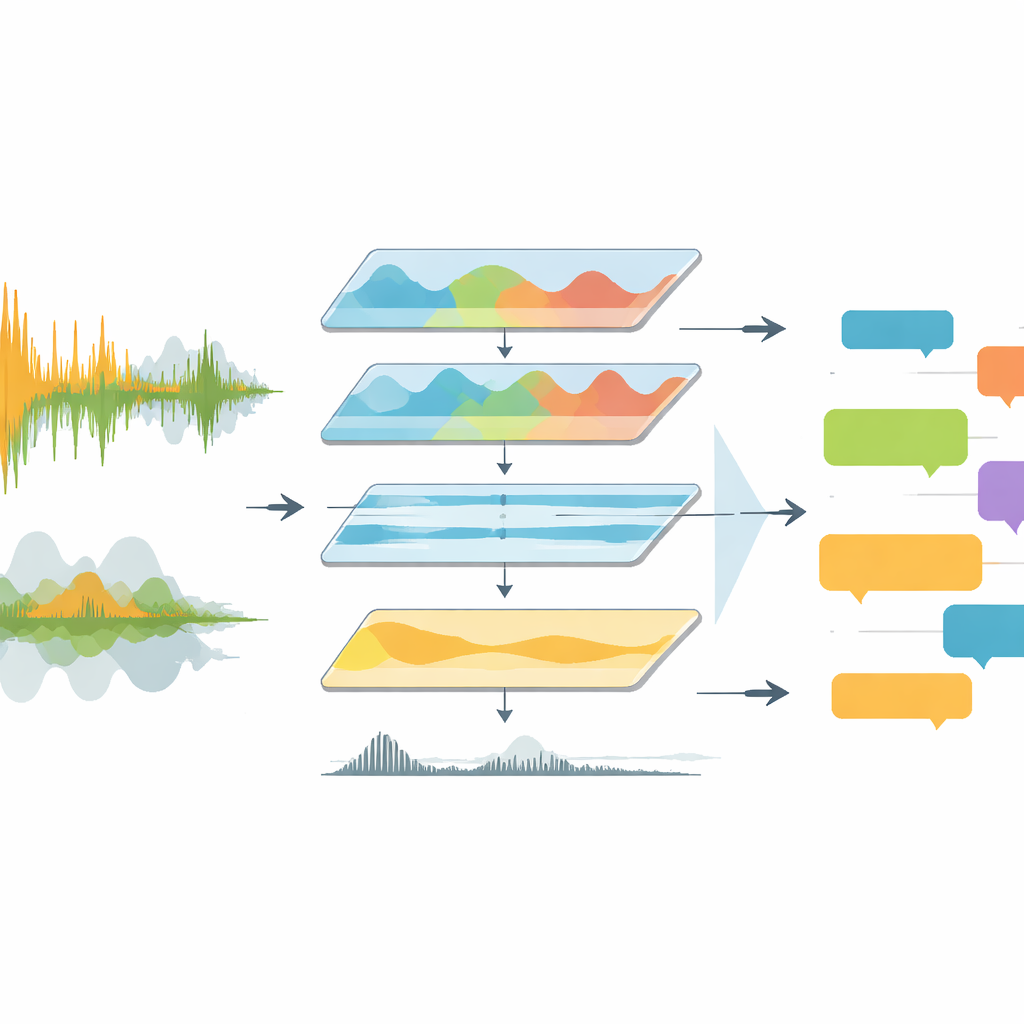
TV-sända matcher är akustiskt röriga. Kommentatorer talar över sjungande fans, arenamusik och plötsliga utbrott av jubel. Tidigare verktyg matade oftast detta råa brus direkt till taligenkänningsprogram, som hade svårt med överlappande röster, skiftande språk och dålig ljudkvalitet. EchoNet angriper problemet som en ingenjörspipeline snarare än en enda smart modell. Den börjar med att extrahera ljudspåret från helmatchvideor och konvertera det till ett standardiserat, högkvalitativt format. Systemet går sedan in i frekvensdomänen och fokuserar på det område där mänskligt tal lever, samtidigt som dunkla basgångar och skarpa artefakter dämpas. Ett djupinlärningsverktyg kallat Demucs separerar vidare tal-liknande ljud från resten, vilket lämnar ett mycket klarare spår för senare steg att tolka.

Att lära maskiner att skilja röster från brus
När ljudet väl är rengjort måste EchoNet avgöra när någon faktiskt talar och om rösten tillhör en kommentator eller publiken. För detta använder författarna en neural röstaktivitetsdetektor som skannar ljudet i korta fönster och märker varje ögonblick som tal eller icke-tal. Upptäckta talsegment granskas sedan närmare. Segment som visar det stadiga rytmiska mönstret och strukturen i talat språk taggas som kommentar, medan de som ser ut som utbrott av kaotisk energi taggas som åskådare. Denna separation spelar roll: kommentatorns meningar bär taktisk och narrativ betydelse, medan publikreaktioner främst signalerar emotionella toppar som mål eller nära missar. Genom att dela upp dessa källor kan systemet behandla dem olika i senare analyser.
Att göra många språk till en berättelse
EchoNet matar varje kommentarsegment till flera versioner av Whisper-modellen för automatisk taligenkänning, inklusive både standard- och hastighetsoptimerade varianter. Dessa modeller är tränade på hundratusentals timmar av flerspråkigt ljud, vilket gör dem väl lämpade för Europas stora ligor, där sändningar växlar mellan engelska, tyska, spanska, italienska, franska och andra språk. Systemet registrerar varje segments tidpunkt, språk och utskrift i strukturerade JSON-filer kopplade till matchhalvorna. För klipp på andra språk transkriberar EchoNet först på originalspråket och skickar sedan texten till en översättningsmotor för att få engelska versioner. Denna tvåstegslösning håller transkriptions- och översättningsfel åtskilda, vilket hjälper forskare att felsöka fel och jämföra språksspecifikt beteende.
Att mäta hur väl det fungerar
Eftersom en pipeline bara är så stark som sin svagaste länk utvärderar författarna EchoNet ur flera vinklar. De introducerar ett nytt ”Report Accuracy”-mått som omvandlar traditionella ordfelstal till en mer intuitiv procentsats av praktiskt korrekt innehåll. Över tre dataset—including deras nyutgivna EchoNet++-samling med 20 fulla matcher—minskar förbearbetning med EchoNet konsekvent transkriptionsfel och ökar Report Accuracy med flera procentenheter för varje testad Whisper-modell. Mått på signalens kvalitet, som uppskattar hur begripligt talet skulle låta för en mänsklig lyssnare, förbättras också markant efter filtrering, brusreducering och normalisering. Ablationsstudier, där individuella komponenter som bandpassfiltret eller röstdetektorn tas bort, visar att varje steg bidrar meningsfullt till både tydlighet och korrekthet.
Vad detta betyder för fans och analytiker
I vardagliga termer ger EchoNet och EchoNet++ ett pålitligt sätt att förvandla timmar av bullrig, flerspråkig matchkommentar till ren, tidsanpassad text och publikindikatorer. Med denna grund kan utvecklare automatiskt upptäcka nyckelhändelser från kommentatorns ton och ord, koppla dessa ögonblick till toppar i publikreaktioner och bygga detaljerade sammanfattningar eller höjdpunktsklipp utan manuell loggning. Avgörande är att datasetet och koden släpps för forskningsbruk, vilket ger communityn en gemensam, reproducerbar plattform för att studera fotboll genom ljud. För både fans och analytiker skjuter detta arbete sportbevakningen mot en framtid där matchens ljudspår blir lika sökbart och analyserbart som bilden själv.
Citering: Majeed, F., Nazir, M., Agus, M. et al. EchoNet++: A multilingual soccer match audio commentary dataset. Sci Rep 16, 8884 (2026). https://doi.org/10.1038/s41598-026-39884-8
Nyckelord: fotbollsanalys, sportsljud, taligenkänning, flerspråkig kommentar, sändningsanalys