Clear Sky Science · sv
En ny integration av tvärvariabeltransformer och signaldekomponering för realtidsprognoser av flodvattennivå: en implikation för hållbar förvaltning av vattenresurser
Att bevaka floderna som skyddar kuststäder
För miljontals människor som bor vid floddeltan kan en plötslig vattennivåhöjning innebära översvämmade hem, förstörda grödor och störda städer. Många av de floder som löper störst risk, särskilt i fattigare eller avlägsna områden, saknar ändå de detaljerade väder- och flottmätningar som dagens prognosverktyg vanligtvis kräver. Denna studie introducerar ett nytt sätt att förutsäga dagliga flodvattennivåer med hjälp av endast tidigare vattennivåmätningar, vilket erbjuder en lovande väg mot bättre översvämningsberedskap i datafattiga regioner.
Varför enkla flodregister inte är så enkla
Flodvattennivåer stiger och faller under tidvattnets, regnens, uppströmsdammars och till och med avlägsna klimatmönsters påverkan. Dessa upp- och nedgångar skapar tidsserier som ser brusiga och oregelbundna ut, med plötsliga toppar under stormar eller högvatten. Traditionella datamodeller förväntar sig ofta många olika ingångar—regn, temperatur, avdunstning med mera—och har svårt när endast vattennivåregister finns tillgängliga. I Bangladeshs Rupsa-Pasur-flod, som passerar kuststäderna Khulna och Mongla, är detta exakt situationen: hög översvämningsrisk men begränsad kompletterande data. Författarna ställde sig en praktisk fråga: kan vi ändå göra mycket precisa realtidsprognoser för dagliga vattennivåer när allt vi har är en enda, skakig tidsserie av tidigare mätningar?
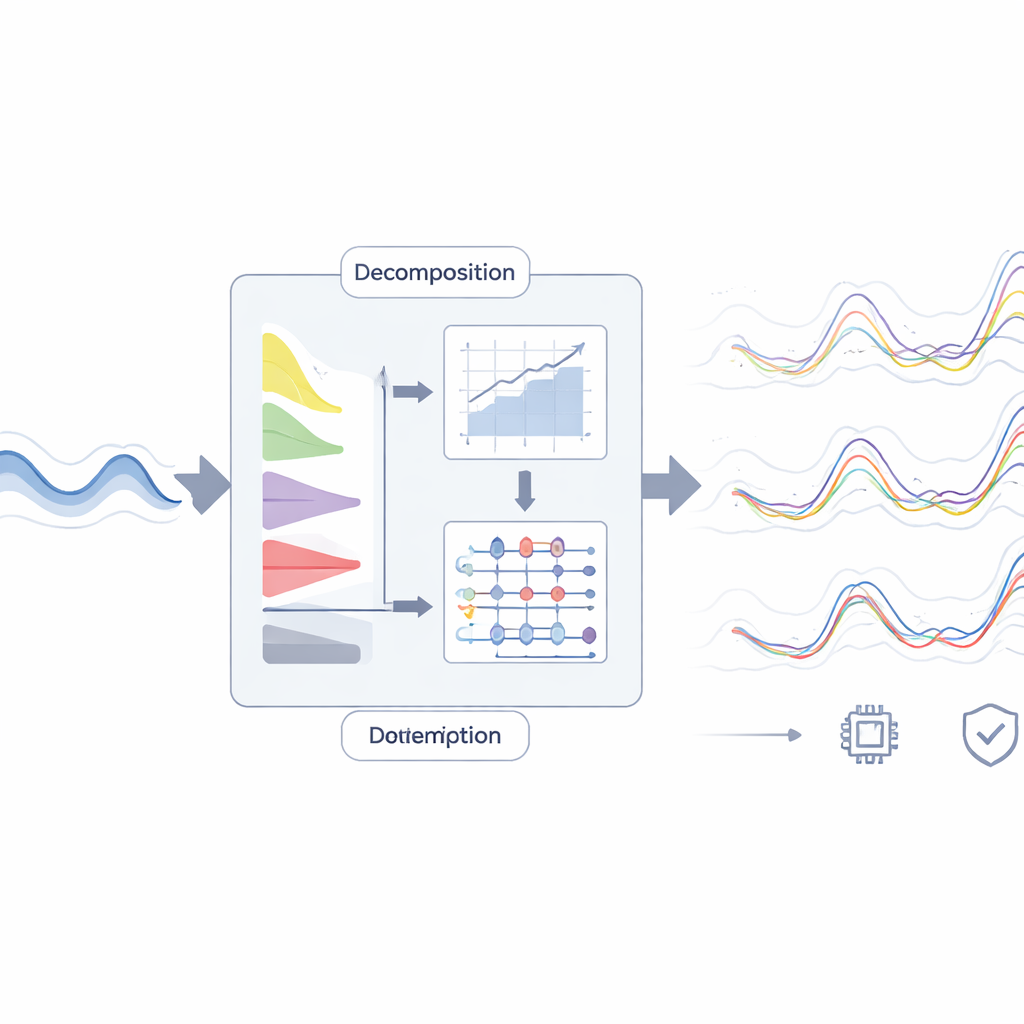
Att bryta en komplex signal i hanterbara delar
Forskarlaget angriper utmaningen genom att först "lyssna" noggrannare på flodens historia. Istället för att mata den råa vattennivåkurvan direkt till en prognosmodell tillämpar de avancerade signaldekomponeringsmetoder. Dessa metoder delar upp det ursprungliga registret i flera jämnare delsignaler, där varje del fångar mönster på olika tidsskala—från snabba dagliga svängningar till långsammare säsongsvariationer—plus ett återstående residual. Fem sådana tekniker testas, inklusive en nyare metod kallad successive variational mode decomposition, som är utformad för att lyfta fram tydliga komponenter även när data är brusiga. Dessa dekomponerade delar fungerar som en rikare uppsättning ledtrådar skapade från den enda tillgängliga variabeln.
En ny inlärningsmotor för flodbeteende
För att lära av dessa ledtrådar använder teamet en modern prognosmodell kallad CLIENT, som kombinerar två idéer. Den ena delen är en enkel, snabb linjär modell som följer breda trender i vattennivån. Den andra delen är en transformer-modul—en typ av djupinlärningsarkitektur som ofta används i språkmodeller—som utmärker sig i att upptäcka subtila relationer mellan indataegenskaper. Innan inlärningen börjar jämnas skiften i tidsseriens övergripande nivå ut genom ett reversibelt normaliseringssteg som sedan återställs i slutet, vilket hjälper modellen att förbli stabil över tid. Genom att mata CLIENT både nyligen uppmätta dagliga nivåer och de dekomponerade delsignalerna bygger författarna sex versioner av modellen och jämför dem med mer bekanta verktyg som neurala nätverk, long short-term memory-nätverk och beslutsträd.
Hur väl kan vi förutsäga nästa dags flodnivå?
Testat vid Khulna- och Mongla-stationerna presterar den hybrida metoden anmärkningsvärt bra. Alla de klientvarianter som förbättrats med dekomponering minskar prognosfelen jämfört med modeller som endast använder de senaste dagliga nivåerna. Stjärnmodellen är kombinationen som använder successive variational mode decomposition, benämnd C6 i studien. Vid båda stationerna återger denna modell nästan alla observerade dag-till-dag-svängningar och fångar extrema högvattenhändelser med anmärkningsvärd precision, och uppnår nästan perfekta färdighetsmått samtidigt som beräkningstiden hålls måttlig. Författarna genomför därefter stresstester av samma modell på tre mycket olika floder i Bangladesh och USA, över flera tränings-testuppdelningar, och finner att den fortfarande förutsäger pålitligt även när datamängderna är relativt korta eller starkt varierande.
Från forskningskod till praktiska översvämningsvarningar
För att gå från teori till praktik paketerar teamet sin bästa modell i ett interaktivt datorgränssnitt. Användare kan ladda upp ett enkelt kalkylblad med tidigare dagliga vattennivåer och få nästa dags prognoser, med det tunga matematiska arbetet dolt i bakgrunden. Eftersom metoden endast är beroende av vattennivåregister—ofta de mest lättillgängliga hydrologiska uppgifterna—öppnar den dörren för fler samhällen, särskilt i utvecklingsländer i kustområden, att få tillgång till tidsanpassade flodprognoser. Enkelt uttryckt visar studien att genom att smart omforma och lära av en enda mätström kan vi bygga snabba och precisa verktyg som hjälper planerare, ingenjörer och invånare att upptäcka farliga vattennivåer lite tidigare och agera innan översvämningar inträffar.
Citering: Ratul, M., Akter, U., Mollick, T. et al. A novel integration of cross variable transformer and signal decomposition for real-time prediction of river water level: an implication for sustainable water resources management. Sci Rep 16, 9366 (2026). https://doi.org/10.1038/s41598-026-39591-4
Nyckelord: prognoser för flodvattennivå, översvämningsrisk, maskininlärning, tidsseriedekomponering, kustnära Bangladesh