Clear Sky Science · sv
Automatiserad detektion av konfotoreceptorer med syntetiska data och djupinlärning i konfokal adaptiv optik scannande laser oftalmoskopibilder
Skarpare vyer av det levande ögat
Att kunna se ögats ljusupptagande celler en och en kan förändra hur läkare upptäcker och följer bländande sjukdomar. I dag måste experter fortfarande märka ut dessa celler för hand i starkt förstorade bilder av näthinnan — en process som är långsam, subjektiv och svår att skala upp till tusentals patienter. Denna studie visar hur datormodeller tränade på realistiska ”fejkade” ögonbilder kan lära sig att hitta dessa celler automatiskt, vilket banar väg för snabbare, mer tillförlitliga ögonundersökningar och bättre utvärdering av nya behandlingar.
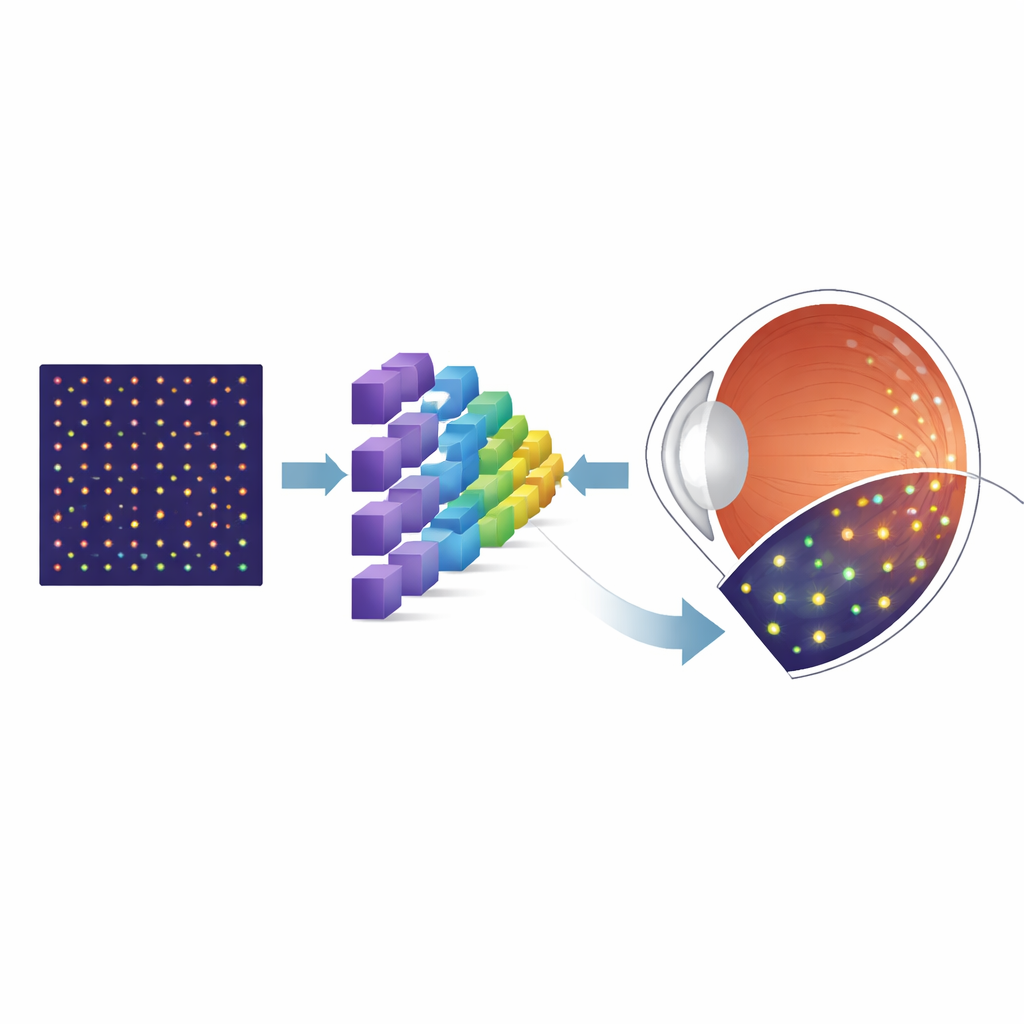
Varför små celler spelar roll
Bakre delen av ögat är täckt av fotoreceptorer — specialiserade celler som omvandlar ljus till de signaler som vår hjärna tolkar som syn. Konfotoreceptorerna är särskilt viktiga för skarp central syn och färguppfattning, och deras förlust är ett kännetecken för många retinala sjukdomar. En kraftfull avbildningsteknik som kallas adaptiv optik scannande laser oftalmoskopi (AOSLO) kan fånga detaljerade bilder av dessa celler hos levande personer. Men innan läkare och forskare kan mäta kontäthet eller följa förändringar över tid måste varje enskild kon först lokaliseras i bilden. Manuell märkning tar inte bara mycket tid utan kan också variera mellan personer, vilket begränsar användbarheten i rutinmässiga kliniker och stora studier.
Från handgjorda regler till inlärning från data
Tidigare datorprogram försökte automatisera kondetection genom fasta regler: till exempel att leta efter ljusa fläckar av en viss storlek eller med viss mellanrum. Dessa regelbaserade metoder fungerade bra på rena bilder från friska ögon, men stötte ofta på problem när bilder var brusiga, lätt oskarpa eller kom från patienter med sjukdom. Djupinlärning erbjuder en annan strategi. Istället för att handkonstruera regler lär sig ett neuralt nätverk mönster direkt från exempel. Haken är att dessa modeller vanligtvis kräver mycket stora mängder bilder som redan noggrant märkts upp av experter — just den typ av data som är sällsynt och dyrbar inom AOSLO-avbildning.
Bygga en virtuell träningsmiljö
För att kringgå bristen på märkta verkliga bilder vände sig forskarna till ett simuleringsverktyg kallat ERICA, som kan generera realistiska AOSLO-liknande bilder av konmosaik tillsammans med perfekt ”ground truth” om var varje kon ligger. De skapade stora uppsättningar av dessa syntetiska bilder som täcker många positioner i näthinnan, samtidigt som de systematiskt varierade viktiga brister som påverkar verkliga bilder, såsom slumpmässigt brus och subtil optisk oskärpa. Därefter tränade de en specialiserad neuralt nätverksarkitektur, känd som U-Net, att omvandla varje inmatningsbild till en sannolikhetskarta som visar var konerna sannolikt finns. Efter denna initiala träning på syntetiska data finjusterade teamet modellen med en mycket mindre samling verkliga AOSLO-bilder från en välkänd offentlig datamängd, och testade slutligen modellen på oberoende bilder från ett annat laboratorium för att se hur väl den generaliserade.

Hur väl datorn matchar mänskliga experter
Teamet jämförde sin automatiserade metod med noggrann manuell märkning och med två ledande kondetection-algoritmer. Med ett standardmått för överlappning mellan förutsagda och manuella konmarkeringar matchade eller kom U-Net nära prestandan hos både expertgranskare och de konkurrerande automatiska metoderna på den publika datamängden. Avgörande var att när modellen testades på en separat uppsättning bilder tagna på olika avstånd från syncentrum och insamlade med ett annat instrument, presterade den fortfarande mycket väl. Det tyder på att träning i stor utsträckning på syntetiska data som täcker ett brett spektrum av visuella förhållanden hjälpte nätverket att lära sig funktioner som överförs till verkliga bilder, snarare än att överanpassa sig till en specifik kamera eller patientgrupp.
Vad detta kan innebära för framtidens ögonvård
För icke-specialister är kärnbudskapet att ett datorprogram som till stor del tränats på ”virtuella” ögonbilder nu kan hitta verkliga konceller i högupplösta näthinneavbildningar ungefär lika pålitligt som mänskliga experter. Genom att göra kondetection snabbare, mer objektiv och enklare att tillämpa över olika skannrar och kliniker kan detta förfarande hjälpa till att göra detaljerad näthinneavbildning till ett rutinverktyg för att följa sjukdomar på cellnivå. På längre sikt kan liknande metoder drivna av syntetiska data utvidgas för att upptäcka andra celltyper och modellera sjukdomsrelaterad cellförlust, vilket stöder tidigare diagnos, bättre övervakning av progress och mer precis utvärdering av nya behandlingar som syftar till att bevara synen.
Citering: Shah, M., Young, L.K., Downes, S.M. et al. Automated cone photoreceptor detection using synthetic data and deep learning in confocal adaptive optics scanning laser ophthalmoscope images. Sci Rep 16, 8313 (2026). https://doi.org/10.1038/s41598-026-39570-9
Nyckelord: näthinneavbildning, konfotoreceptorer, djupinlärning, syntetiska data, adaptiv optik