Clear Sky Science · sv
En adaptiv ram för ombalansering av data för realtidsprognoser av trafikrisk
Varför det spelar roll att balansera trafikdata för säkerheten
Motorvägsolyckor är sällsynta händelser jämfört med den stora mängd vanlig, händelselös körning. Det är goda nyheter för säkerheten, men det skapar ett dolt problem för datorer som försöker förutsäga när och var olyckor kan inträffa i realtid. När data domineras av säkra situationer kan algoritmer bli mycket bra på att förutsäga ”inget händer” och ändå se korrekta ut på papperet — samtidigt som de tyst missar de verkligt farliga ögonblicken. Denna studie tar itu med den obalansen direkt och föreslår ett adaptivt sätt att ”ombalansera” trafikdata så att varningssystem bättre kan känna igen sällsynta men viktiga riskförhållanden utan att bli för långsamma för verklig användning.
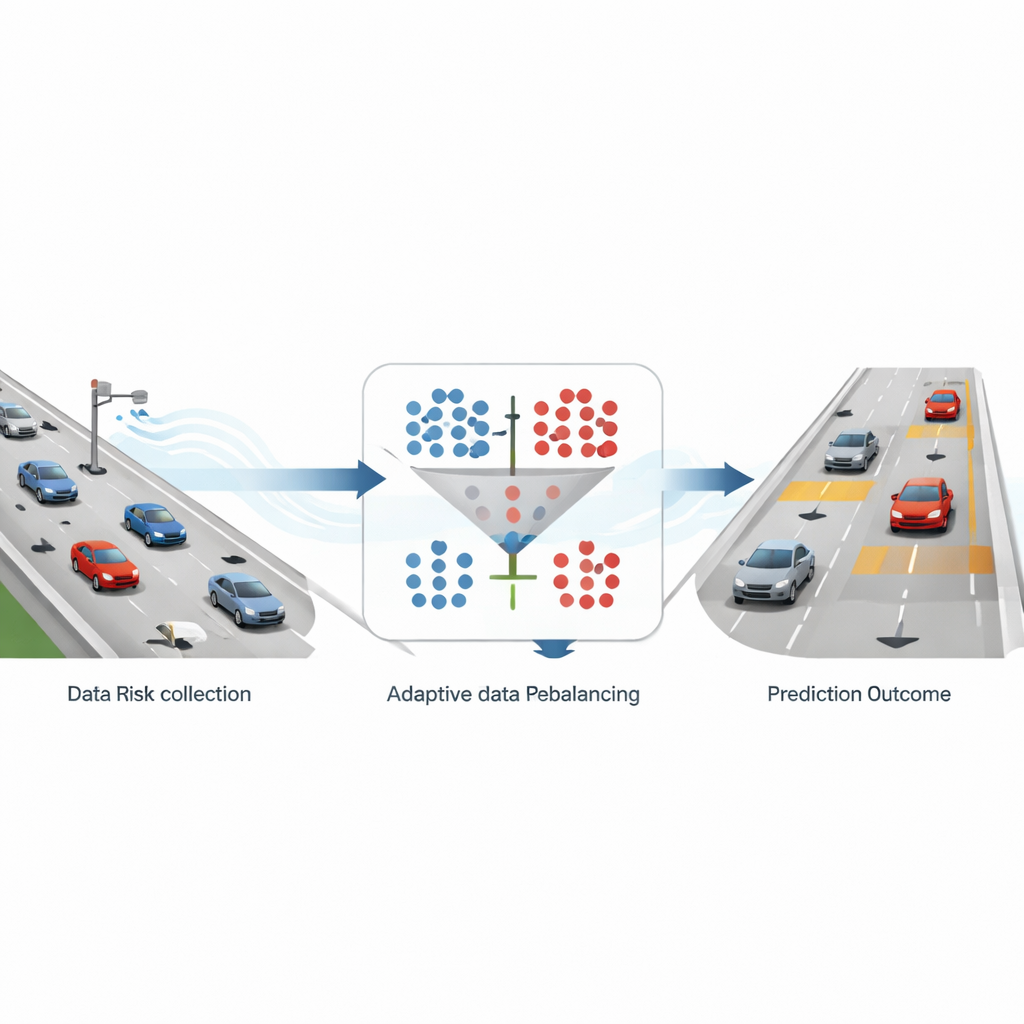
Hur verklig trafik görs om till varningssignaler
Forskarna bygger sin ram på detaljerade motorvägstrajektorier från en stor drönarbaserad datamängd inspelad över tyska motorvägar. Varje fordons position och hastighet spåras många gånger per sekund längs sexfiliga vägavsnitt. Från denna rika rörelsedata beräknar teamet en vida använd säkerhetsindikator kallad time-to-collision, som uppskattar hur lång tid det skulle ta för en följande bil att köra in i bilen framför om båda fortsatte som de gör. När denna tid sjunker under tre sekunder märks situationen som ”hög risk”; annars behandlas den som ”icke-risk”. Efter att ha aggregerat dessa mått i 10-sekundersskivor och fokuserat på sexfiliga vägar landar de i ungefär nio säkra prover för varje riskfyllt, en starkt snedfördelad datamängd som speglar verkliga motorvägsförhållanden.
Åtgärda skevheten utan att tappa det väsentliga
För att hantera denna skevhet jämför studien två vanliga strategier. Den ena, kallad översampling, lägger till fler exempel på sällsynta riskfyllda situationer genom att skapa syntetiska prover som liknar verkliga hög-risksfall. Den andra, undersampling, minskar antalet säkra fall genom att slumpmässigt kasta bort några av dem. Författarna använder en populär översamplingsmetod (SMOTE) och en enkel slumpmässig undersamplingsmetod, och tillämpar dem vid flera fasta proportioner mellan säkra och riskfyllda prover — 1:1, 2:1, 3:1 och 4:1. De matar sedan både de ursprungliga och de ändrade datamängderna in i fyra prediktionsmodeller: två traditionella maskininlärningsmetoder och två djupinlärningsmodeller som är specialiserade på att hantera tidsserier. Genom att testa alla dessa kombinationer kan de se hur olika sätt att balansera data påverkar systemets förmåga att upptäcka risk samtidigt som det känner igen säkra förhållanden.
Låta en algoritm söka efter den gyllene balansen
I stället för att anta att exakt lika många säkra och riskfyllda prover är bäst låter forskarna en genetisk algoritm — en sökmetod inspirerad av evolution — jaga den mest effektiva balansen. Denna optimerare justerar förhållandet mellan säkra och riskfyllda prover inom ett realistiskt intervall från 1:1 till 4:1, genererar upprepade gånger kandidatförhållanden, utvärderar dem och förfinar dem över hundratals iterationer. Viktigt är att den inte bara tittar på förutsägelseprecision: den beaktar också hur lång tid modellen tar att träna och göra förutsägelser, vilket speglar realtidskraven i trafikstyrningscentraler. För att säkerställa att noggrannhet och beräkningstid kan kombineras rättvist normaliseras alla mått innan de blandas till ett enskilt "fitness"-poängtal som algoritmen försöker minimera.
Vad modellerna lär sig om risk på vägen
Över de många experimenten framträder ett mönster. Att balansera data förbättrar riskprognosen jämfört med att lämna den ursprungliga skevheten orörd, och översampling med syntetiska riskfall tenderar att fungera bättre än att kasta bort säkra. Ett 2:1-förhållande mellan säkra och riskfyllda prover ger bäst prestanda bland de fasta inställningarna och överträffar det ofta använda 1:1-valet. När den genetiska algoritmen får justera detta förhållande landar den på något ojämna men optimala värden — cirka 2,3:1 för översampling och 2,7:1 för undersampling. Bland prediktionsmodellerna levererar en särskild typ av rekurrent neuralt nätverk, känt som gated recurrent unit, konsekvent de starkaste resultaten, särskilt i kombination med översampling och optimering. Modellerna visar också att genomsnittliga fordonshastigheter uppströms och nedströms från en punkt på motorvägen är mer informativa för risk än enkla fordonräkningar.
Kontrollera stabilitet och förberedelse för verkligheten
Eftersom optimeringsmetoder ibland kan fastna i missvisande lösningar undersöker författarna hur deras sökning beter sig över tid. De visar att fitness-poängen stadigt sjunker och så småningom planar ut, vilket tyder på att algoritmen konvergerar mot stabila, högkvalitativa förhållanden snarare än att hoppa omkring. De skruvar sedan lätt på de valda förhållandena upp och ner med några procent för att se om prestandan kollapsar. I praktiken sjunker noggrannheten endast marginellt vid små förändringar, vilket indikerar att systemet är robust och inte överdrivet anpassat till en enda, skör inställning. Däremot, när den del av data som reserverats för testning blir mycket stor, blir modellerna mer känsliga, vilket lyfter fram behovet av tillräckligt rikligt träningsdata.
Vad detta betyder för säkrare, smartare motorvägar
I vardagliga termer visar studien att det inte räcker med smarta modeller för att lära datorer att känna igen fara på vägen; det handlar också om att förse dessa modeller med en rättvis bild av sällsynta men kritiska händelser. Genom att noggrant justera hur många säkra och riskfyllda exempel som används i träningen — och genom att låta en adaptiv algoritm finna den bästa kompromissen mellan noggrannhet och hastighet — gör den föreslagna ramen realtidsprognoser av motorvägsrisk mer tillförlitliga och mer praktiska. Trafikmyndigheter skulle kunna integrera detta tillvägagångssätt i system som övervakar trafikdetektordata och utfärdar tidiga varningar om sannolika påkörningsolyckor bakifrån, vilket kan hjälpa till att styra förarvarningar, patrullinsatser eller automatiska nödbromssystem. Medan arbetet demonstreras på tyska motorvägar under gott väder erbjuder den underliggande idén med adaptiv databalansering ett allmänt recept för att förbättra säkerhetsprognoser där farliga händelser är sällsynta men för viktiga för att förbises.
Citering: Chen, S., Cui, B. & Chang, A. An adaptive data rebalancing framework for real-time traffic risk prediction. Sci Rep 16, 8882 (2026). https://doi.org/10.1038/s41598-026-39539-8
Nyckelord: trafiksäkerhet, olycksrisksprognos, obalanserade data, maskininlärning, motorvägstrajektorier