Clear Sky Science · sv
En dataeffektiv 3D-medical vision-language-modell som endast använder en 2D-encoder
Smartare stöd från 3D‑skanningar
När läkare tolkar CT‑ eller MR‑skanningar tittar de inte bara på enstaka bilder — de sätter mentalt ihop hundratals skivor för att förstå problemet i tre dimensioner. Att lära datorer göra samma sak kan ge snabbare, mer konsekventa diagnoser och tydligare rapporter för patienter. Men dagens artificiella intelligenssystem som hanterar 3D‑skanningar är extremt "data‑hungriga" och kräver stora, noggrant etiketterade datamängder som många sjukhus helt enkelt inte har. Denna artikel presenterar ett sätt att få 3D‑nivåförståelse med befintlig 2D‑bildteknik, vilket lovar kraftfulla verktyg som är enklare och billigare att bygga och använda.
Varför 3D‑skanningar är svåra för AI
Moderna "vision–language"‑system kan redan tolka en 2D‑medicinsk bild och svara på frågor eller utforma en rapport i klartext. Att utvidga den förmågan till 3D‑volymer skulle låta AI resonera om hela organ och subtila lesioner som först blir tydliga när många skivor ses tillsammans. Problemet är att de flesta nuvarande 3D‑system förlitar sig på speciella 3D‑encodrar som tränas från grunden på enorma samlingar av etiketterade skanningar. Sådana datasätt är sällsynta, dyra att annotera och ofta knutna till välfinansierade centra, vilket begränsar vem som kan dra nytta av tekniken. Samtidigt förlorar man den naturliga kontinuiteten mellan skivor — och överbelastar modellen med repetitiv information — om man bara behandlar varje skiva som en separat 2D‑bild.
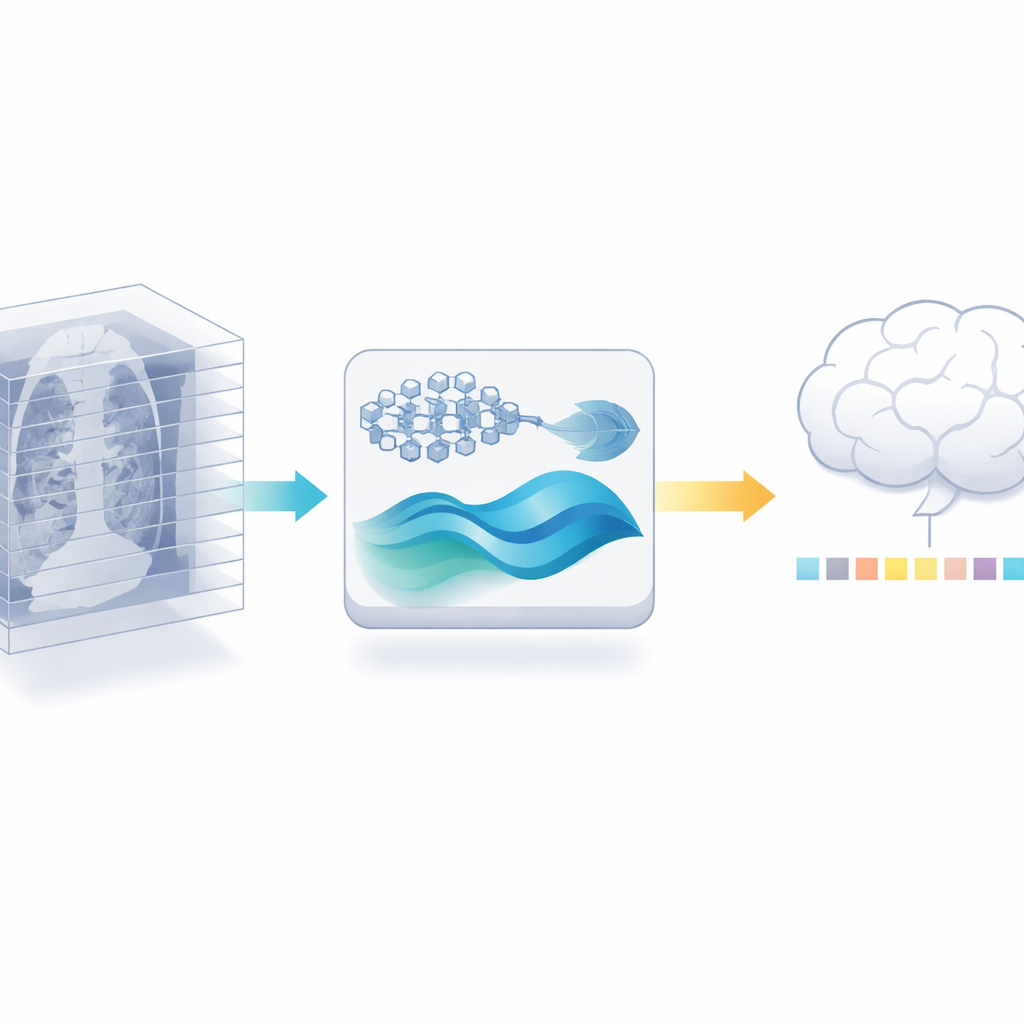
Återanvända en 2D‑expert för 3D‑arbete
Författarna föreslår en annan väg: i stället för att träna en ny 3D‑encoder återanvänder de en kraftfull 2D‑modell för medicinska bilder som redan tränats på miljontals etiketterade bilder från medicinsk litteratur. De delar först varje 3D‑skanning i enskilda skivor och låter denna 2D‑modell extrahera detaljerade egenskaper från varje skiva. Därefter skär de försiktigt bort redundans: eftersom intilliggande skivor i en skanning ofta ser nästan likadana ut kan en likhetskontroll kasta många nästan‑dubbletter och samtidigt behålla de mest informativa vyerna. Detta steg minskar i sig mängden data som senare steg behöver hantera, utan att kräva fler etiketterade skanningar.
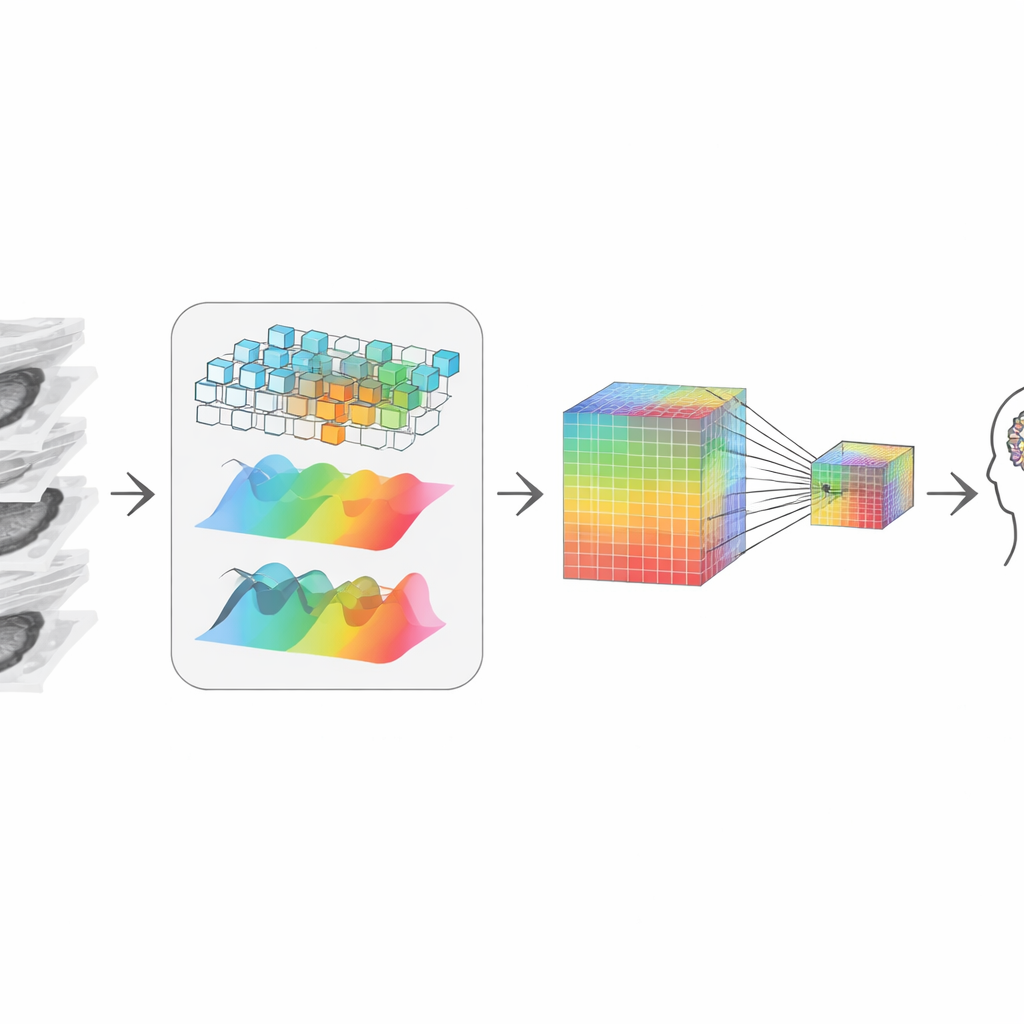
Återskapa 3D‑berättelsen från bitar
Efter trimningen måste systemet "återstifta" de kvarvarande skivorna till en koherent 3D‑bild. Författarna gör detta genom att kombinera två kompletterande vyer av datan. Den ena vägen fokuserar på lokala former och kanter, som ett förstoringsglas som rör sig genom volymen och är känsligt för skarpa gränser och texturer. Den andra vägen transformerar datan till en frekvensvy, vilket bättre fångar breda mönster och långdistansstruktur över skivorna — hur en tumör sträcker sig eller hur ett organs form ser ut överlag. Ett adaptivt fusionssteg lär sig hur mycket varje vy ska litas på i varje punkt, vilket ger en representation som respekterar både fin detaljer och global kontext, trots att den började från 2D‑skivor.
Behålla små ledtrådar samtidigt som man komprimerar
För att kommunicera med en stor språkmodell — den del som svarar på frågor och skriver rapporter — måste visuell information komprimeras till ett måttligt antal tokens, eller "visuella ord." Enkel förminskning skulle sudda ut små men viktiga signaler, som små kalkavlagringar eller subtila texturförändringar som betyder mycket för diagnostiken. För att undvika detta skapar författarna en tvåspårsrepresentation: den ena behåller en högupplöst version rik på detaljer och den andra är en mindre, billigare version. En uppmärksamhetsmekanism låter varje punkt i den mindre versionen selektivt "titta tillbaka" på den större versionen och hämta de skarpaste detaljerna. Resultatet är en kompakt visuell sammanfattning som ändå bär de ledtrådar en radiolog skulle bry sig om, vilken sedan skickas till språkmodellen för resonemang.
Bevis på verkliga medicinska uppgifter
För att testa sin design utvärderade forskarna den på offentliga 3D‑benchmarkar som ställer två huvudfrågor: kan systemet skriva korrekta radiologiliknande beskrivningar av 3D‑skanningar, och kan det svara på frågor om vad som syns i dem? Deras angreppssätt, trots att de aldrig tränade en 3D‑specifik encoder, överträffade flera starka 3D‑baserade modeller i båda uppgifterna. Det producerade mer precisa, kliniskt rika rapporter och svarade mer exakt på frågor, inklusive svåra sådana om exakt organ, avvikelse eller plats. Det kördes också snabbare, krävde mycket mindre 3D‑träningsdata och generaliserade väl till olika skanningstyper såsom MR och PET.
Vad detta betyder för framtida vård
I praktiska termer visar detta arbete att vi inte behöver börja från noll med data‑hungriga 3D‑modeller för att få högkvalitativt AI‑stöd för volymetriska skanningar. Genom att smart återanvända en stark 2D‑expert, noggrant välja informativa skivor och återskapa 3D‑bilden samtidigt som små detaljer bevaras, når författarna toppresultat med mycket mindre data och beräkning. Om detta tillvägagångssätt antas i stor skala kan det göra avancerat AI‑stöd — såsom bättre rapporter, tydligare förklaringar och mer pålitlig triage — tillgängligt för sjukhus och kliniker som saknar massiva dataresurser, och därigenom föra sofistikerad bildanalys närmare rutinmässig klinisk praxis.
Citering: Lian, Y., Xie, Y., Jiang, Y. et al. A data-efficient 3D medical vision-language model using only a 2D encoder. Sci Rep 16, 8809 (2026). https://doi.org/10.1038/s41598-026-39526-z
Nyckelord: 3D medicinsk bildbehandling, vision-language-modeller, radiologi AI, dataeffektivt lärande, CT och MR‑analys