Clear Sky Science · sv
Biometrisk åtskillnad av enäggstvillingar baserad på ansiktsmärken med dynamisk funktionsförstärkning
Varför små huddetaljer spelar roll
De flesta antar att enäggstvillingar är, ja, identiska — så lika att även högteknologiska kameror och DNA‑tester har svårt att skilja dem åt. Den likheten skapar stora problem i verkliga situationer, från att lösa brott till att säkra gränser. Den här studien visar att lösningen kan ligga i något vi sällan lägger märke till: de små, stabila märken och fläckar som finns utspridda över våra ansikten. Genom att behandla dessa födelsemärken, fläckar och porer som en slags ”hudkarta” byggde forskarna ett automatiserat system som pålitligt kan skilja enäggstvillingar åt, vilket pekar mot mer precisa och förklarliga biometriska verktyg.
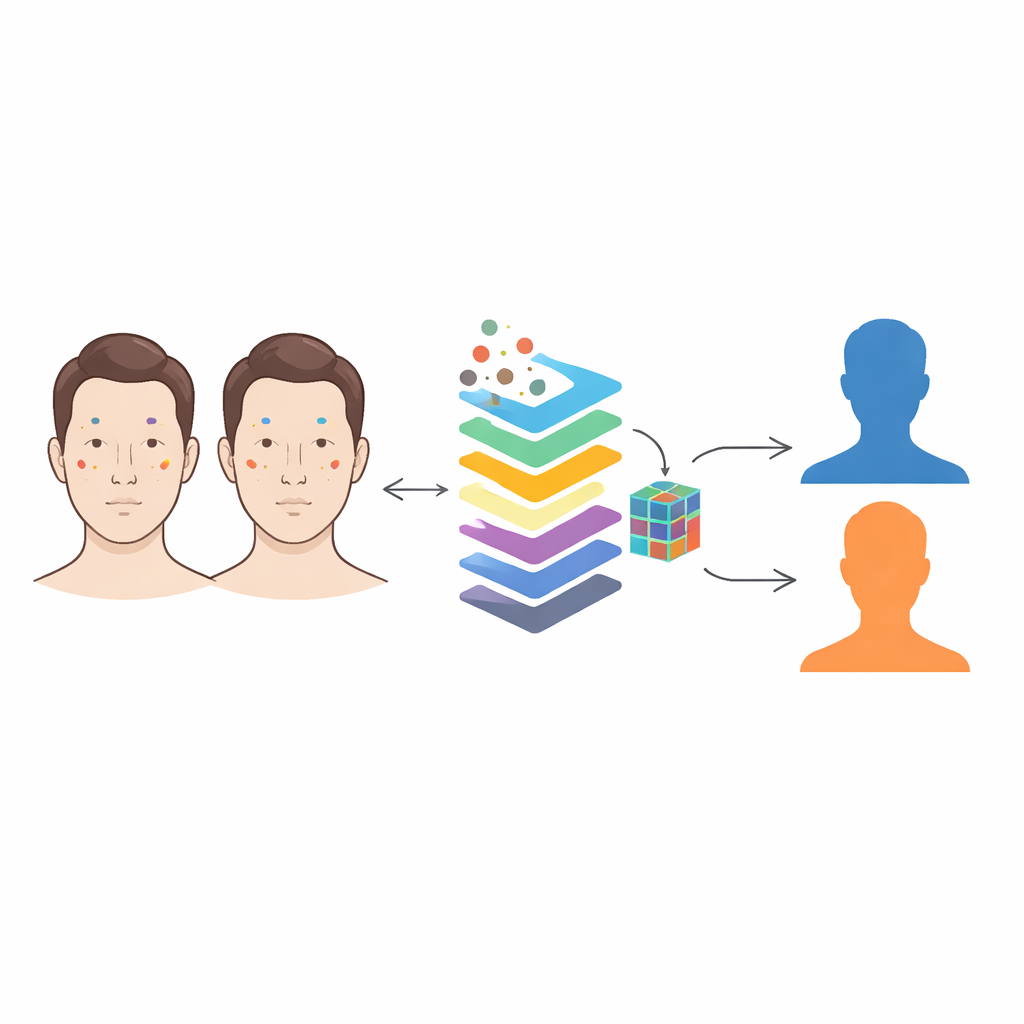
Från förvillande ansikten till tydliga hudkartor
Traditionella ansiktsigenkänningssystem fokuserar på den övergripande ansiktsstrukturen — avståndet mellan ögonen, näsans form, käklinjen. För enäggstvillingar är dessa drag nästan kopior, vilket är anledningen till att även avancerade algoritmer och DNA‑profilering ofta misslyckas med att säga vem som är vem. Författarna koncentrerar sig istället på de små, i stort sett beständiga detaljerna i ansiktshuden: akneärr, mörka fläckar, porer och rynkor. Dessa märken tenderar att bilda unika mönster över en persons livstid, även hos människor som delar nästan alla sina gener. Kärnidéen är enkel men kraftfull: medan tvillingansikten kan se lika ut vid en snabb blick, gör deras konstellationer av hudmärken det inte.
Hur systemet ser det vi missar
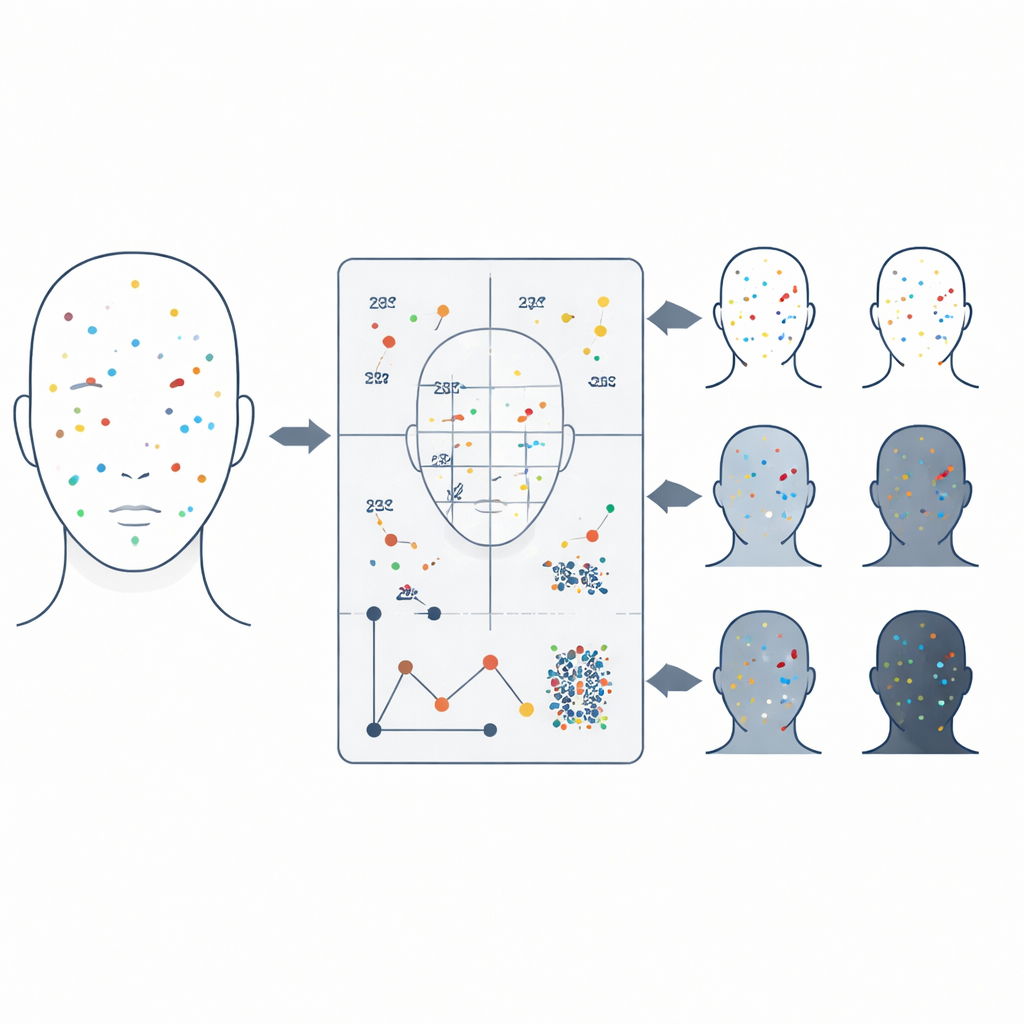
Teamet arbetade med 319 ansiktsfoton från 74 tvillingpar i en välkänd forskningssamling. Först använde de en förtränad datorvisionsmodell för att skanna varje ansikte och upptäcka olika typer av huddrag — såsom akne, mörka ringar eller porer — och ritade osynliga rutor runt varje upptäckt. Viktigt är att detektorn ställdes in för att vara mycket känslig, villig att plocka upp även svaga märken på bekostnad av att också fånga en del brus. Istället för att lita på varje upptäckt för sig sammanfattade de alla märken i en rik profil för varje person: hur många märken av varje typ som förekommer, hur tätt de klustrar, hur de är fördelade över ansiktet och hur stora de i genomsnitt är.
Att omvandla hudmönster till tvillingbeslut
Nästa steg var att jämföra dessa hudprofiler mellan bildpar — ibland riktiga tvillingpar, ibland orelaterade personer — för att mäta hur lika eller olika de var. De kombinerade flera intuitiva jämförelsesteg: hur väl blandningen av märken matchar, hur lika de genomsnittliga storlekarna är, hur jämnt märkena delas mellan vänster och höger eller övre och nedre delen av ansiktet, och hur märkena är ordnade i rummet, inklusive hur långt de sitter från ansiktets centrum och hur starkt de klustrar. Dessa likhetspoäng matades sedan in i en maskininlärningsmodell som lärde sig att svara på en ja‑/nej‑fråga: tillhör dessa två ansikten samma tvillingpar eller inte?
Smart finjustering utan att slösa tid
Att bygga en sådan klassificerare handlar inte bara om vilken information du ger den, utan också om hur du ställer in dess många interna ”vridreglage”, såsom hur komplex modellen får bli. Studien jämförde systematiskt fyra olika strategier för att söka efter de bästa inställningarna, från ett uttömmande rutnät av möjligheter till mer explorativa metoder inspirerade av slumpmässigt provtagning och svärm‑beteende i naturen. Medan en svärmbaserad metod gav något bättre rånoggrannhet under testning, levererade en enklare slumpmässig sökning i stort sett samma prestanda på en bråkdel av tiden. Denna balans är viktig i praktiken: ett system som är både exakt och effektivt har mycket större sannolikhet att användas i verkligheten i polislaboratorier, vid gränskontroller eller i medicinsk forskning.
Vad huden säger om identitet
Sammanfattningsvis nådde ramverket cirka 96,6 % noggrannhet i korsvalidering och ett starkt resultat i tester som mäter hur väl det skiljer tvillingar från icke‑tvillingar, med minimala tecken på överanpassning. Det mest avgörande signalen var inte vilka typer av märken folk hade, utan var dessa märken dök upp i ansiktet — det rumsliga mönstret fungerade som en unik signatur. Antalet märken per typ, skillnader mellan ansiktsregioner och subtila klusterbildningar gav extra tillförlitlighet. Viktigt är att systemets beslut kan visualiseras och förklaras, vilket tillåter utredare att se vilka aspekter av hudkartan som drev en matchning eller icke‑matchning. För en bred läsekrets är budskapet slående: även hos de mest lika människor vi känner, registrerar huden tyst tillräckligt med individuella detaljer för att maskiner ska kunna skilja dem åt — vilket öppnar dörren för rättvisare rättsprocesser, säkrare biometrik och nya sätt att studera hur vår omgivning formar vårt utseende över tid.
Citering: Brahmbhatt, K.J., Prakasha, K. & Sanil, G. Facial mark based biometric differentiation of identical twins using dynamic feature enhancement. Sci Rep 16, 9249 (2026). https://doi.org/10.1038/s41598-026-39470-y
Nyckelord: enäggstvillingar, ansiktsbiometri, hudmärken, forensisk identifiering, maskininlärning