Clear Sky Science · sv
Jämförande utvärdering av video‑stora språkmodeller för kvalitetsbedömning av populärvetenskapliga videor om torra ögon
Varför detta spelar roll för vanliga tittare
Kortvideotjänster blir snabbt många människors första stopp för hälsoråd, även för ögonproblem som torra ögon, vilket påverkar hundratals miljoner världen över. Men bredvid användbara klipp är det lätt att hitta lågkvalitativa eller vilseledande videor som är svåra för läkare att hålla efter. Denna studie undersöker om nya AI‑system som kan "titta" på videor skulle kunna hjälpa till att automatiskt kontrollera kvaliteten på dessa hälsoklipp, och visar varför sådana verktyg för närvarande inte är redo att ersätta expertbedömning.
Torra ögon och hälsovideors uppsving
Torra ögon är mer än en mindre irritation; det kan sudda synen, orsaka smärta och störa arbete och vardagsliv. När tillståndet blir vanligare, särskilt bland äldre och personer som använder skärmar mycket, söker många förklaringar och egenvårdstips online. Plattformar som TikTok hyser otaliga korta videor om torra ögon, men deras öppna natur innebär att vem som helst kan lägga upp innehåll, oavsett medicinsk utbildning. Bristfälliga eller överdrivna råd kan fördröja riktig behandling eller uppmuntra osäkra huskurer, så pålitliga sätt att granska videokvalitet i skala behövs akut.
Hur forskarna testade AI‑granskare av videor
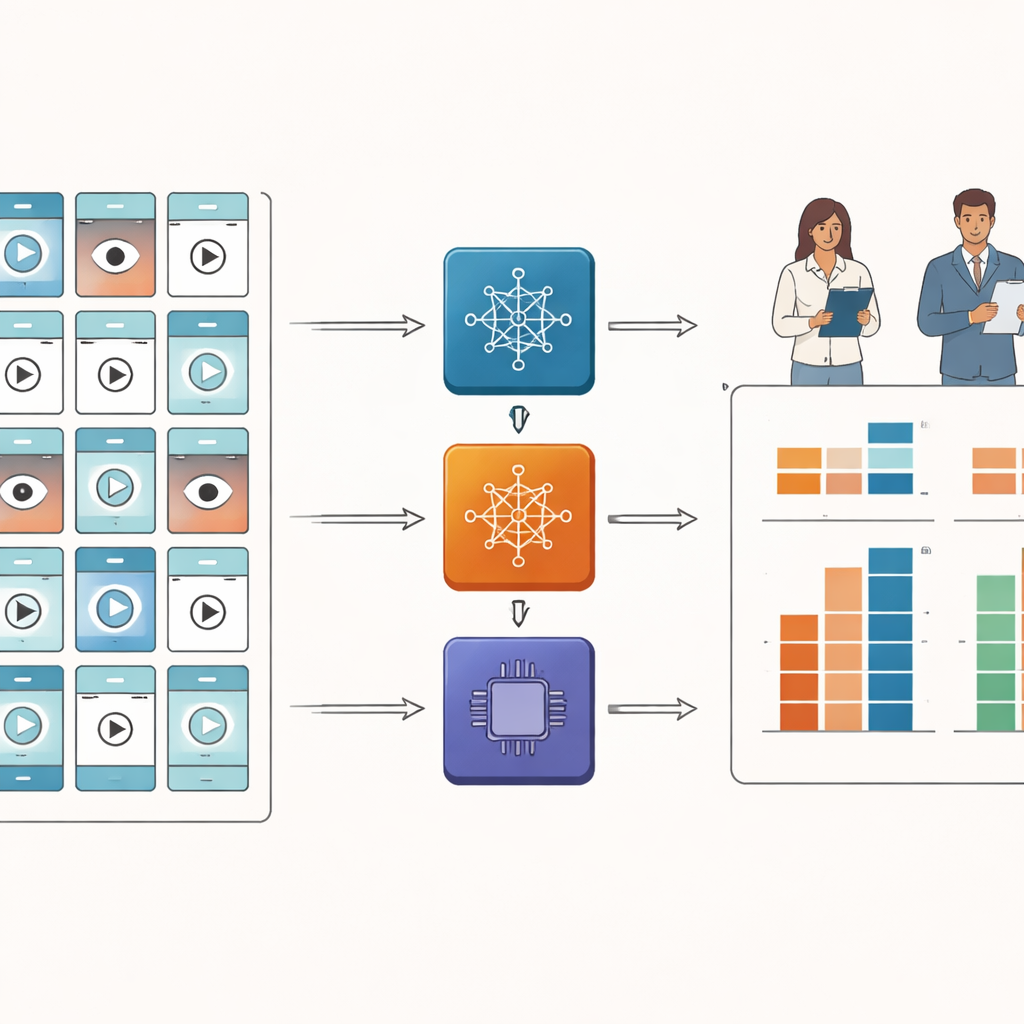
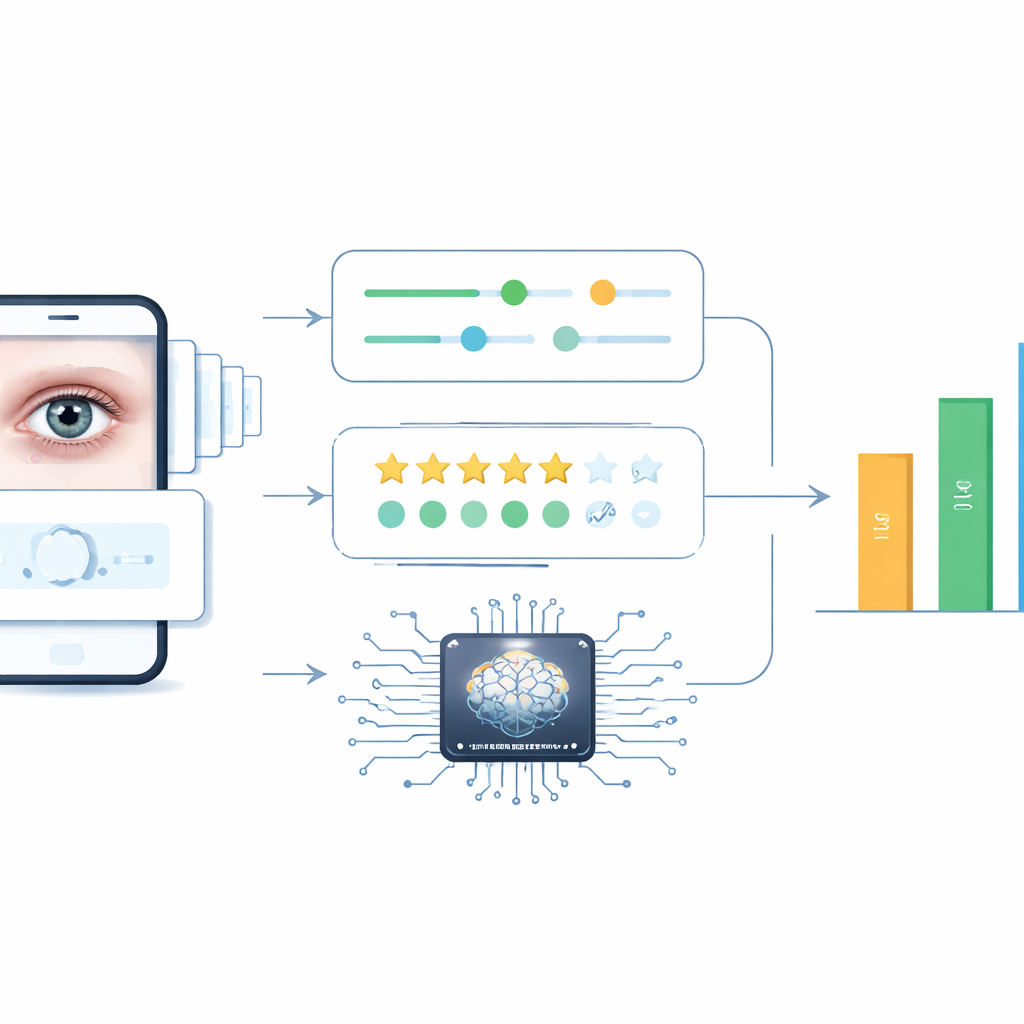
Forskarteamet samlade 185 kineskspråkiga TikTok‑videor om torra ögon med ett nytt, neutralt konto och strikta regler för att bara behålla originala, utbildande klipp. Två ögonspecialister poängsatte sedan varje video med tre etablerade verktyg som ofta används i medicinsk utbildningsforskning. Ett verktyg bedömde hur lättförståeliga videorna var och hur tydligt de föreslog konkreta åtgärder tittarna kunde vidta. Ett andra gav ett övergripande kvalitetsbetyg från dåligt till utmärkt. Det tredje bröt ner kvaliteten i aspekter såsom hur smidigt informationen presenterades, hur korrekt den var, hur väl extra element som animationer användes och hur väl innehållet matchade videons titel.
Sätta videokunniga AI‑modeller på prov
Därefter matade forskarna in samma videor i tre avancerade "video‑stora språkmodeller", AI‑system utformade för att tolka visuella bilder bildruta för bildruta och svara på frågor om vad de ser. De formulerade detaljerade instruktioner så att varje modell skulle efterlikna läkares poängsättningsverktyg så nära som möjligt. Den avgörande frågan var om AI:n och de mänskliga experterna skulle ge liknande poäng. För att mäta detta använde teamet en standardiserad reliabilitetsstatistik som fångar hur nära två olika "bedömare" överensstämmer, inte bara i trender utan i faktiska siffror.
Vad AI:n fick rätt — och fel
Mänskliga bedömare höll i stort sett med varandra, vilket tyder på att deras poäng var stabila och pålitliga. Däremot visade de tre AI‑systemen svag överensstämmelse med experterna i de flesta områden. Ingen av modellerna kunde pålitligt matcha läkarna när det gällde den övergripande videokvaliteten eller detaljerade egenskaper såsom hur väl titlarna speglade innehållet. En modell tenderade att ge högre poäng än experterna, en annan skuggade lägre poäng, och endast en hamnade ibland däremellan. Den enda relativa ljusglimten var "handlingsbarhet" — hur tydligt videorna berättade för tittare vad de skulle göra — där två modeller nådde en medelnivå av överenskommelse, men fortfarande inte uppnådde vad som krävs för verkliga beslutsstöd.
Varför dagens AI inte räcker till
Författarna pekar på flera orsaker till denna klyfta. De testade AI‑systemen var huvudsakligen tränade på vardagsscener och generiska videotasker, inte på noggrant strukturerad hälsoinformation. Många populärvetenskapliga videor förlitar sig tungt på talade förklaringar, undertexter, diagram och metaforer snarare än dramatiska rörliga bilder, men modellerna i denna studie analyserade endast de visuella bildrutorna och lyssnade inte på ljudet eller läste titlar och annan beskrivande information som människor använder för att bedöma relevans och korrekthet. Som en följd nådde stora delar av betydelsen aldrig fram till AI:n, särskilt när viktiga detaljer var uttalade snarare än visade. Bildligt språk, vanligt i kinesisk hälsoinformation, kan också förvirra system som tolkar uttalanden bokstavligt.
Vad detta innebär för patienter och plattformar
Detta arbete ger en tidig färdplan, inte ett färdigt säkerhetsnät. Det visar att välkända kvalitetschecklistor för hälsosam information i princip kan översättas till instruktioner för AI‑modeller som tittar på videor. Det klargör också att nuvarande allmänna system ännu inte är tillförlitliga nog att bedöma medicinska videor eller polisra felinformation utan mänsklig övervakning. Genom att publicera sitt utvärderingsramverk och annoterade videodatamaterial hoppas författarna driva fram bättre, mer specialiserade modeller som kan kombinera visuellt innehåll, ljud och ytterligare kontext, och som kan fungera över sjukdomar och språk. För nu bör tittare fortsätta se korta hälsovideor som utgångspunkter, inte medicinska råd, och plattformar bör inte lita enbart på AI för att garantera trovärdig information.
Citering: Zhou, S., Huang, M., Wei, J. et al. Benchmark evaluation of video large language models in quality assessment of science popularization videos for dry eye. Sci Rep 16, 8756 (2026). https://doi.org/10.1038/s41598-026-39444-0
Nyckelord: torra ögon, hälsovideor, artificiell intelligens, felinformation, TikTok