Clear Sky Science · sv
Genstyrd analytisk inlärningsmodell för exakt bröstcancerdiagnos
Varför denna forskning är viktig för patienter och familjer
Bröstcancer är nu den vanligast diagnostiserade cancern hos kvinnor globalt, och patienter som på pappret ser ut att ha samma sjukdom kan få mycket olika utfall. Denna studie visar hur mönster i tusentals gener, kombinerat med ett omsorgsfullt utformat artificiellt intelligenssystem, kan hjälpa läkare att med större säkerhet avgöra vem som har cancer och hur allvarlig den kan vara — med endast verkliga patientdata och en kompakt uppsättning nyckelgener.
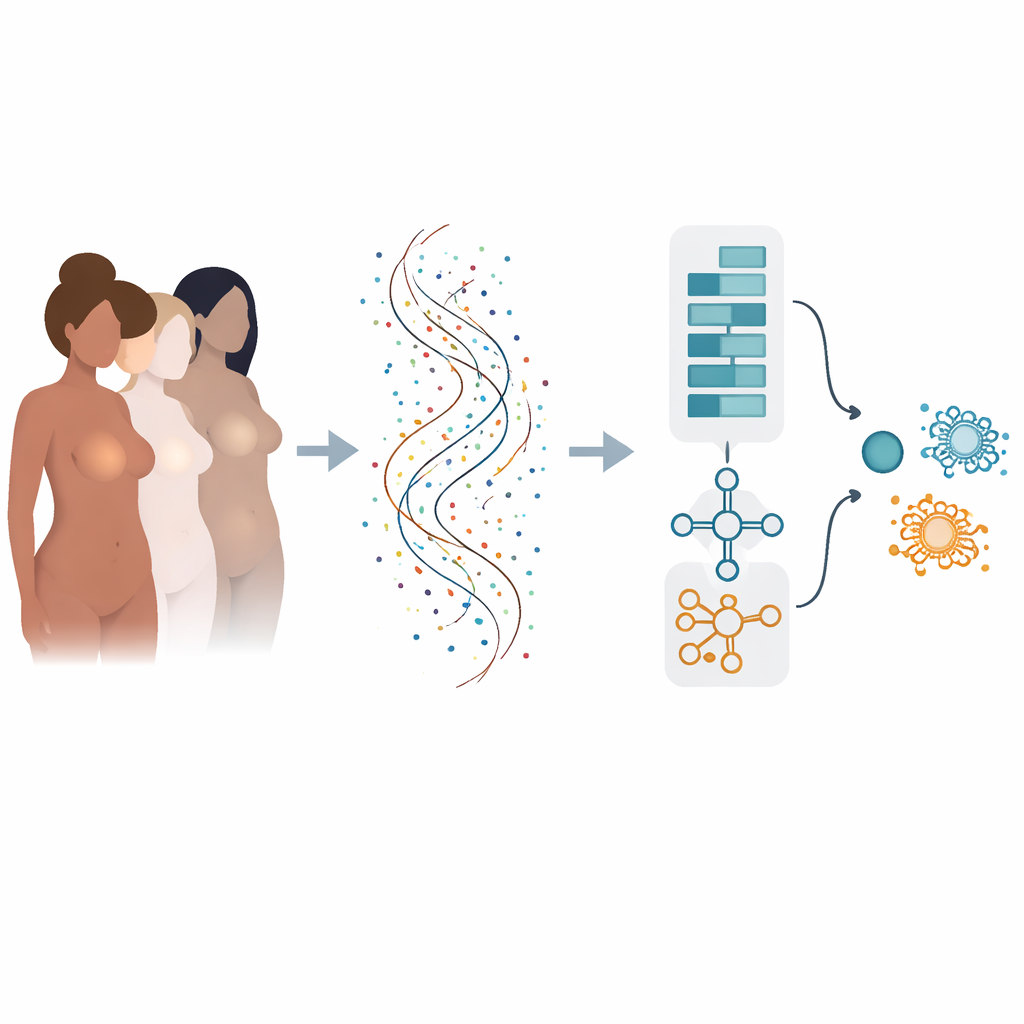
Från många riskfaktorer till geners språk
Risken för bröstcancer formas av många faktorer: ärftliga genetiska förändringar, hormoner, kroppsvikt, livsstil och mer. När cancer väl uppstår styrs dess beteende av vilka gener som är på- eller avstängda i varje tumör. Modern sekvensering kan mäta aktiviteten i tiotusentals gener samtidigt, men att omvandla detta hav av siffror till tydliga ja- eller nej-svar för diagnos och prognos är svårt. Traditionella datormetoder betraktar ofta gener en och en och kan missa hur grupper av gener samverkar, eller så presterar de bra bara på en datamängd och misslyckas när de testas på andra.
Att lära en tvåhjärnig modell att läsa genmönster
Författarna byggde en ”hybrid” djuplärande modell som fungerar lite som två specialiserade hjärnor som arbetar tillsammans. En del, inspirerad av bildanalys, skannar en ordnad lista av gener för att upptäcka lokala mönster — kluster av gener vars gemensamma aktivitet signalerar cancer. Den andra delen behandlar samma gener som en sekvens och lär sig hur tidiga ”driver”-gener och senare ”downstream”-gener påverkar varandra över listan. Genom att kombinera dessa två perspektiv kan modellen fånga både kort- och långdistansrelationer inom tumörens genetiska fingeravtryck.
Att hitta en stabil kärna av signalgener
I stället för att mata in alla 17 815 mätta gener i modellen designade teamet en strikt, ”läckagefri” pipeline för att välja endast de mest informativa. Med hjälp av en standardiserad korrelationsmått inom upprepade korsvalideringsloopar rankade de generna flera gånger efter hur starkt deras aktivitet följde cancerns status. De behöll sedan bara de gener som konsekvent hamnade i toppen över alla träningsdelningar, vilket resulterade i en stabil signatur på 236 gener. Forskarna kartlade också hur dessa gener interagerar med varandra och visade att många bildar tätt sammankopplade nätverk relaterade till tumörtillväxt, metabolism, immunitet och den omgivande vävnadsmiljön — bevis på att den valda uppsättningen speglar verklig biologi, inte slumpmässigt brus.
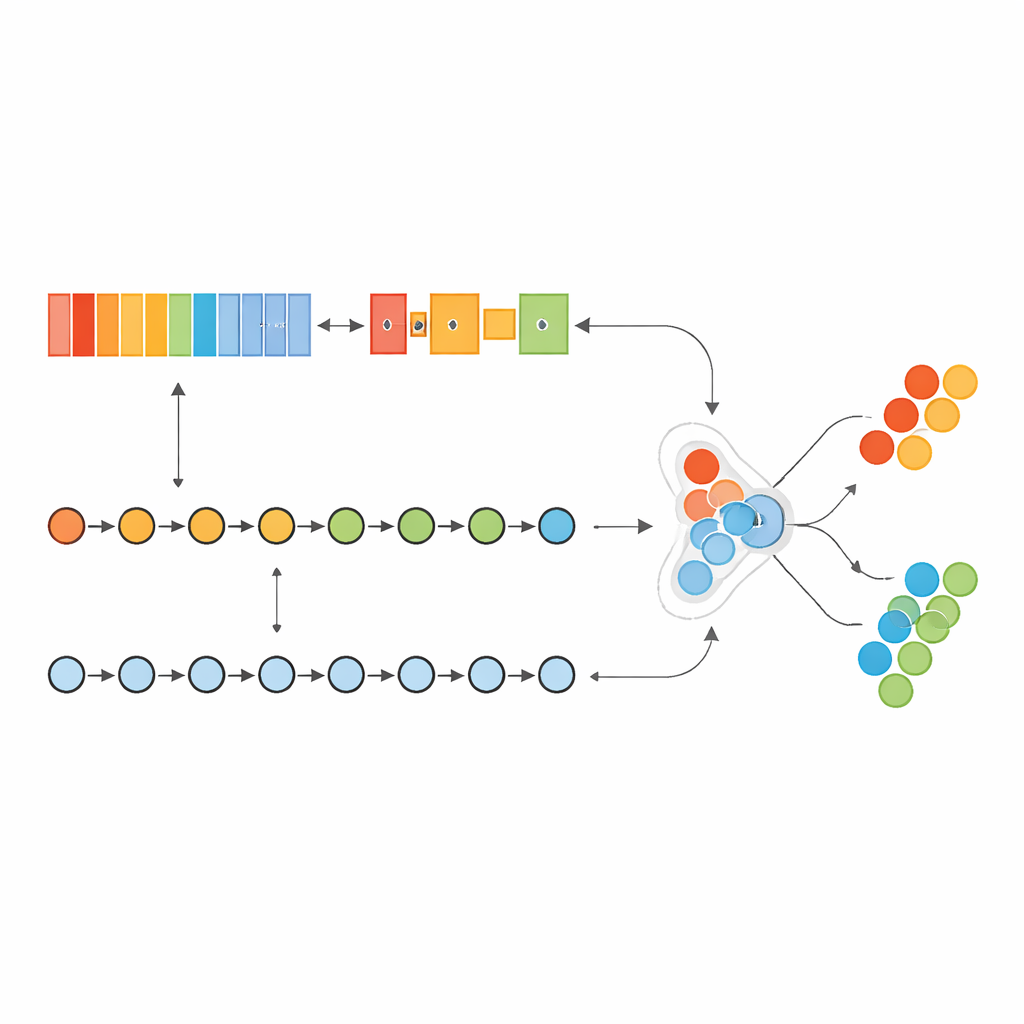
Att sätta modellen på prov
Hybridsystemet tränades och finjusterades på bröstcancerprov från The Cancer Genome Atlas och utmanades sedan med en helt separat datamängd känd som METABRIC. För att hantera att cancerproven var betydligt fler än normala prov skapade författarna inte artificiella data; i stället justerade de hur mycket modellen ”bryr sig” om fel på den sällsynta klassen. Efter en automatisk sökning efter bästa inställningar uppnådde modellen nästan perfekta poäng på sin huvuddataset, och flaggade korrekt nästan alla cancerfall samtidigt som den i praktiken gav väldigt få falsklarm. Viktigt är att prestandan förblev extremt hög och mycket stabil även när modellen applicerades på den externa METABRIC-kohorten, vilket tyder på att angreppssättet kan generalisera bortom en studie eller ett sjukhus.
Vad detta betyder för framtida vård
Enkelt uttryckt levererar detta arbete en finjusterad, tvådelad AI som läser en kompakt 236-gens kod för att skilja cancerösa från icke-cancerösa bröstprover med anmärkningsvärd noggrannhet och konsekvens, även under brusiga förhållanden. Medan den aktuella studien enbart undersöker genaktivitet och använder historiska patientdata lägger dess metoder grunden för framtida verktyg som kan kombinera flera datatyper — såsom vävnadsbilder och ytterligare molekylära lager — och ge tydliga förklaringar om vilka gener som driver varje prediktion. Med vidare validering i prospektiva kliniska studier skulle ett sådant system kunna bli en universell ryggrad för precisionsdiagnostik av bröstcancer och hjälpa läkare att skräddarsy behandlingar utifrån varje patients tumörs genetiska ”signatur”.
Citering: Hesham, F., Abbassy, M.M. & Abdalla, M. Gene driven analytical learning model for accurate breast cancer diagnosis. Sci Rep 16, 8155 (2026). https://doi.org/10.1038/s41598-026-39430-6
Nyckelord: bröstcancerdiagnos, genuttryck, djuplärande, CNN-BiLSTM, precision-onkologi