Clear Sky Science · sv
CGDFNet: ett dubbelgrensat realtidsnätverk för semantisk segmentering med kontextstyrd detaljfusion
Att lära bilar se hela gatan
Moderna bilar och robotar förlitar sig i allt större utsträckning på kameror för att förstå världen omkring dem—att i realtid upptäcka vägar, trottoarer, människor, fordon och skyltar. I den här artikeln presenteras CGDFNet, ett nytt datorvisionssystem utformat för att utföra denna typ av ”scenförståelse” snabbare och mer noggrant, särskilt i trafikerade stadsmiljöer. Genom att lära sig behålla både fina detaljer (som trafikljusstolpar eller cykelhjul) och den övergripande strukturen (som vägar och byggnader) samtidigt, syftar CGDFNet till att göra automatiserad körning och andra realtidsvisionsuppgifter säkrare och mer tillförlitliga.
Varför pixelnivåvision är så krävande
Vid semantisk segmentering tilldelar en dator en kategori till varje enskild pixel i en bild: väg, bil, fotgängare, himmel och så vidare. Detta är långt mer krävande än att bara rita en ruta runt en bil, eftersom systemet måste följa objektsgränser och små former med hög precision. Många metoder med hög noggrannhet finns, men de tenderar att vara långsamma och strömkrävande, vilket är olämpligt för realtidssystem i bilar, drönare eller bärbara enheter. Å andra sidan offrar lätta metoder som körs snabbt ofta detaljnivå eller förlorar överblicken, vilket gör dem svåra för små objekt, tunna strukturer eller trånga urbana miljöer.
Två vägar: en för detalj, en för kontext
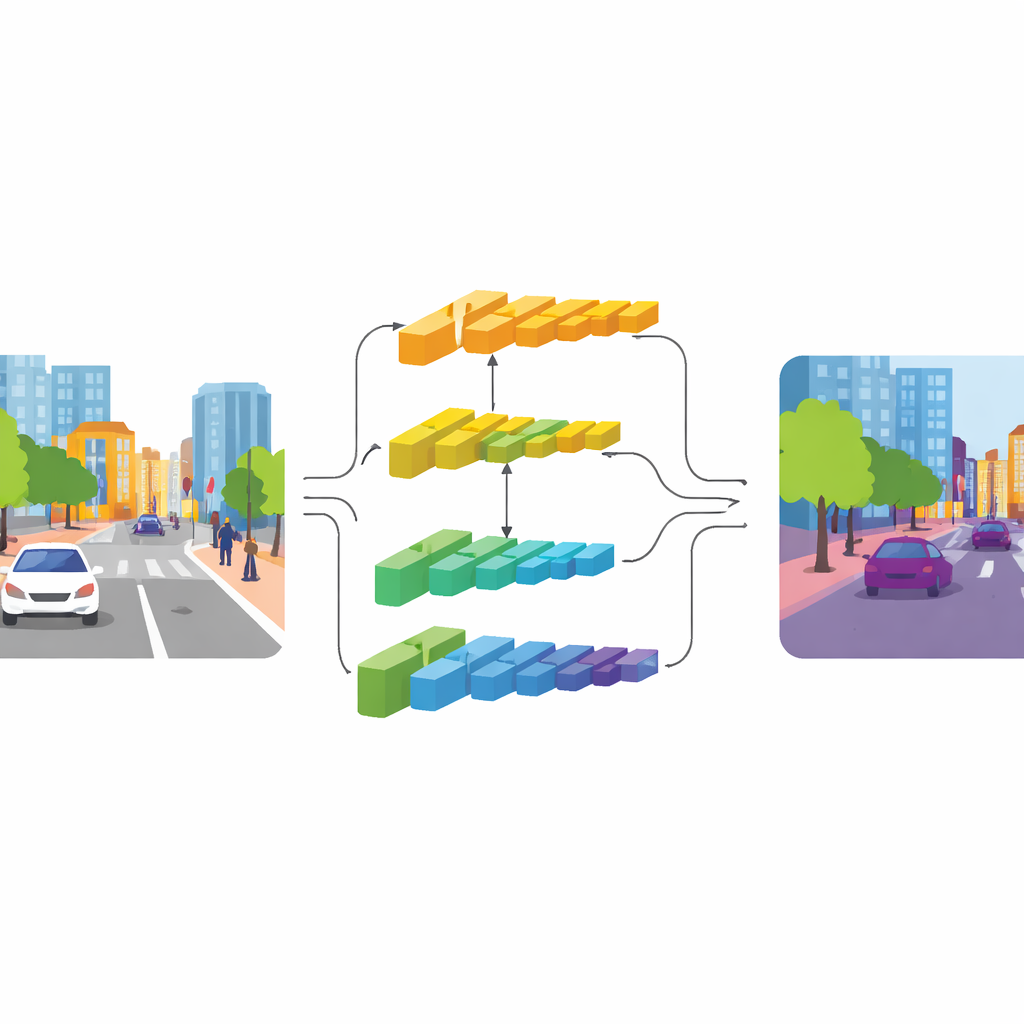
CGDFNet hanterar denna spänning med en dubbelgrensad design: en gren fokuserar på skarpa detaljer, medan den andra fångar bred kontext. Byggt på en effektiv backbone matar de lägre lagren in i en "detail branch" som bibehåller högre upplösning för att bevara kanter och texturer. Djupare lager matar en "context branch" som ser scenen i mer komprimerad form, bra för att förstå övergripande struktur och relationer mellan objekt. Till skillnad från tidigare tvågrensade designer som i stor utsträckning håller dessa strömmar åtskilda och sedan grovt summerar dem, uppmuntrar CGDFNet till kommunikation mellan dem under hela bearbetningen, så att fina detaljer ständigt kontrolleras mot vad nätverket vet om den övergripande scenen.
Vägleda detaljer med betydelse
Två nyckelkomponenter stärker denna interaktion. I kontextgrenen lär sig en Semantic Refinement Module att framhäva de mest informativa regionerna och kanalerna i sina funktionskartor. Den gör detta genom att kombinera lokala signaler (vilka delar av scenen som är aktiva nära varandra) med globala signaler (vad nätverket ser i hela bilden), så att representationen bär både grannskapsdetalj och scennivåbetydelse. I detaljgrenen använder en Context‑Guided Detail Module denna semantiska information för att styra uppmärksamheten mot kanter och fina strukturer som är viktiga, såsom en busskontur eller en cykels ram. Den förlitar sig på en speciell typ av konvolution som är mer känslig för förändringar mellan intilliggande pixlar, vilket naturligt betonar konturer och små objekt utan att lägga till många extra parametrar.
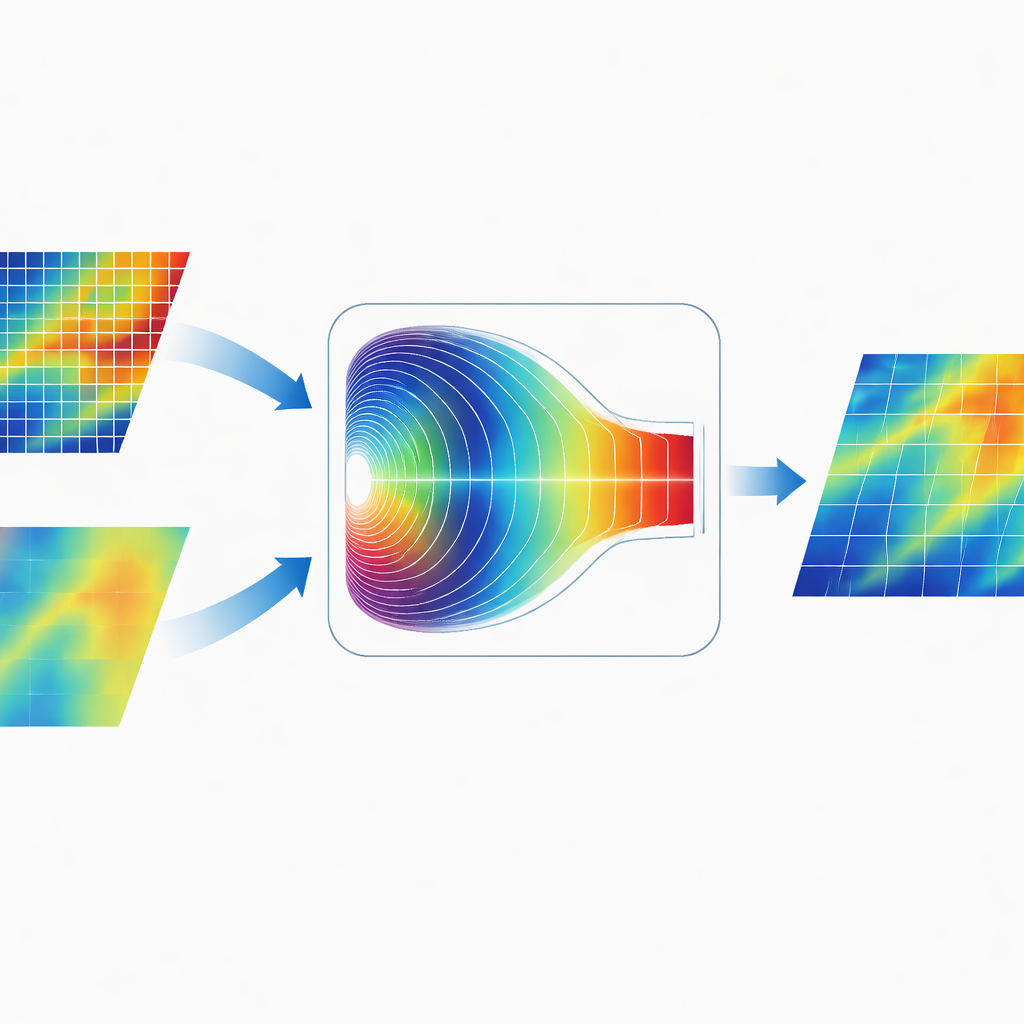
Blanda information i frekvensvärlden
Ett utmärkande drag hos CGDFNet är hur den slår samman de två grenarna. Istället för att enkelt addera deras kartor i bildrummet har författarna utformat en Fourier‑Domain Adaptive Fusion Module. Denna modul transformerar tillfälligt de kombinerade funktionerna till frekvensdomänen, där mönster representeras i termer av långsamma, breda variationer och snabba, skarpa förändringar. En adaptiv grindmekanism lär sig sedan vilka frekvenskomponenter som ska betonas från detaljgrenen och vilka som ska betonas från kontextgrenen. Efter denna viktning transformeras funktionerna tillbaka, vilket ger en representation som förenar skarpa kanter med koherent global struktur mer effektivt än traditionell enbart rumslig fusion.
Resultat på verkliga gator
Teamet testade CGDFNet på två välanvända benchmark-dataset för stadsdrivna scener: Cityscapes, insamlat från europeiska städer, och CamVid, fångat ur en förares perspektiv i Storbritannien. CGDFNet bearbetade stora bilder i realtidshastigheter—runt 88 bildrutor per sekund på Cityscapes och cirka 129 bildrutor per sekund på CamVid—samtidigt som den uppnådde segmenteringsnoggrannhet som matchar eller överträffar många toppmoderna system. Den presterade särskilt väl på kategorier som vanligtvis är svåra att segmentera, såsom staket, trafikskyltar, bussar och cyklar, där bevarandet av precisa gränser och små strukturer är avgörande.
Vad detta betyder för vardaglig teknik
I praktiska termer visar CGDFNet att det är möjligt att bygga visionssystem som är både tillräckligt snabba för realtidsanvändning och noggranna nog att respektera små, säkerhetskritiska detaljer i komplexa stadsscener. Genom att kombinera en detaljorienterad gren, en kontextorienterad gren och ett smart fusionssteg i frekvensdomänen behåller nätverket en balanserad bild av gatan: det vet var allt är och var varje objekt börjar och slutar. Även om utmaningar kvarstår—som tätt packade folksamlingar eller dåligt väder—erbjuder tillvägagångssättet en lovande mall för framtida on‑device‑vision, från självkörande bilar till smarta trafik‑kameror och assistiva robotar.
Citering: Zhao, S., Fu, W., Gao, J. et al. CGDFNet: a dual-branch real-time semantic segmentation network with context-guided detail fusion. Sci Rep 16, 9191 (2026). https://doi.org/10.1038/s41598-026-39370-1
Nyckelord: semantisk segmentering i realtid, visionssystem för autonom körning, tvågrensat neuralt nätverk, Fourier‑baserad funktionsfusion, förståelse av stadslandskap