Clear Sky Science · sv
Patientadressanalys via KG-medveten kontrastiv inlärning och begränsad lokal LLM-inferens
Varför ordnade patientadresser är viktiga
Bakom varje sjukhusbesök finns en enkel textrad: patientens hemadress. Långt ifrån en administrativ petitess driver dessa adresser kartläggning av sjukdomar, planering för nödsituationer och beslut om var kliniker och ambulanser ska placeras. I många journalsystem sparas adresser dock som rörig, inkonsekvent text full av förkortningar, stavfel och saknade uppgifter. Denna artikel presenterar AddrKG‑LLM, en ny metod som förvandlar sådan svårhanterlig adressdata till rena, tillförlitliga poster samtidigt som känsliga uppgifter hålls privata.
Problemet med röriga hemadresser
När adresser skrivs fritt utelämnar människor ofta stadsdelar, byter ordning på ord eller använder lokala smeknamn som officiella kartor inte känner igen. Äldre datormetoder jämför strängar tecken för tecken eller som enkla ordlistor, vilket bara fungerar när indata redan är prydliga och fullständiga. Nyare djupinlärningssystem läser kontext smartare, men de kan fortfarande snubblas av ovanlig formulering och kräver stor beräkningskapacitet. På senare tid har stora språkmodeller visat en imponerande förmåga att förstå och generera text. Men när de tillåts svara fritt tenderar de också att ”hallucinera” detaljer som inte finns i datan — en oacceptabel risk inom vården, där journaler måste vara precisa och granskbara.
En tvåstegsresa från kaos till ordning
Forskarna utformade AddrKG‑LLM som ett tvåstegspipeline som lägger till struktur och skydd kring språkmodellen istället för att låta den verka ensam. Först rensas inkommande patientadresser för att ta bort starkt identifierande detaljer som byggnads- och rumsnummer samt telefonkontakter, vilket bidrar till att skydda integriteten. Den återstående texten omvandlas till en tät numerisk representation som fångar dess betydelse. Samtidigt bygger teamet en kunskapsgraf — ett karta-liknande nätverk som kodar de officiella relationerna mellan städer, stadsdelar, gator och bostadsområden. Genom en teknik kallad kontrastiv inlärning tränas systemet så att adresser som avser samma verkliga område lägger sig nära varandra i detta delade rum, medan orelaterade platser skjuts längre bort. Det gör att systemet snabbt kan hämta en kort lista med sannolika adresskandidater för varje nytt patientärende.
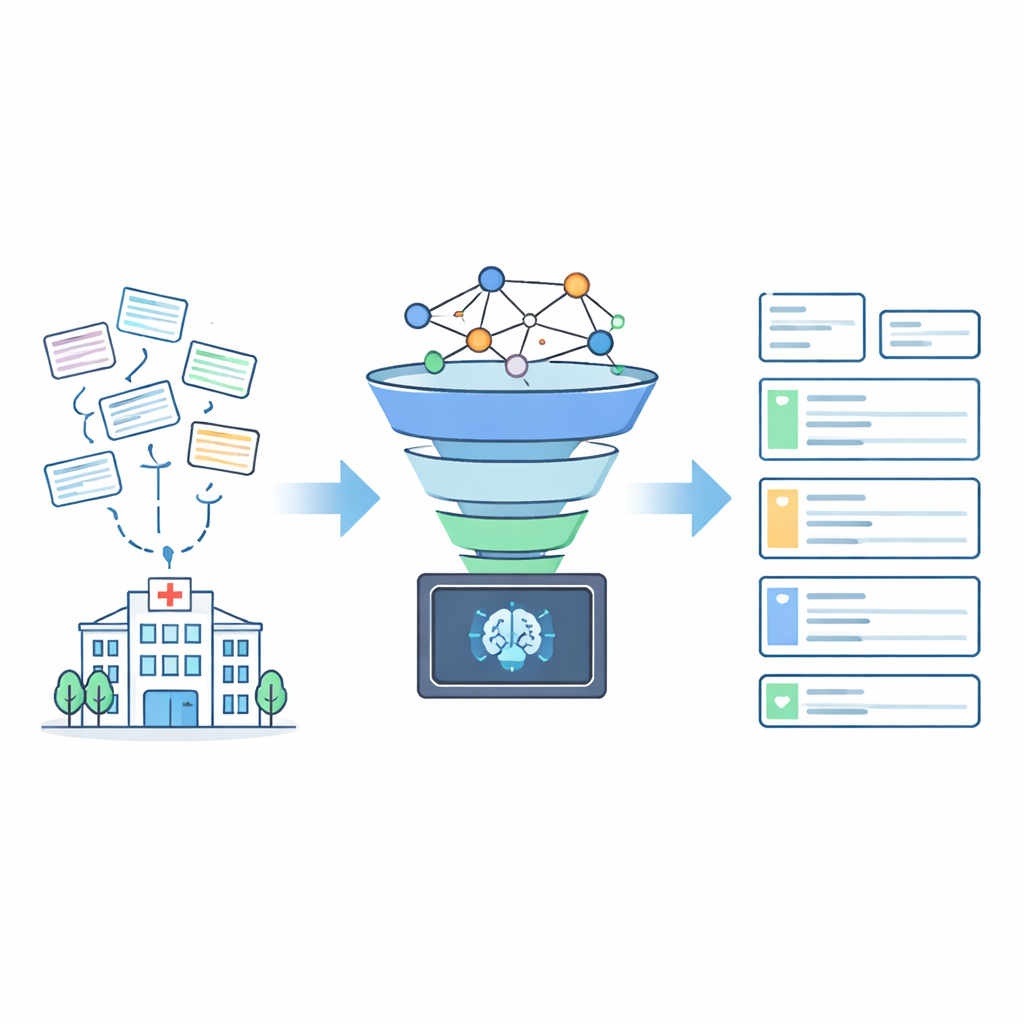
Hålla AI:n i kort koppel
I det andra steget arbetar den stora språkmodellen inom ett omsorgsfullt avgränsat sökutrymme. Istället för att hitta på en adress från grunden får modellen den ursprungliga rensade texten plus den lilla uppsättning kandidatområden som föreslagits av kunskapsgrafen. Prompten instruerar uttryckligen modellen att bara välja bland dessa kandidater och att returnera resultat i en fast JSON-struktur med separata fält för stad, stadsdel, gata eller församling och bostadsområde. Om ingen av kandidaterna passar — till exempel när det verkliga området aldrig hämtades — ska modellen lämna fälten tomma i stället för att gissa. Detta ”avvisnings-först”-beteende minskar kraftigt risken att trovärdigt klingande men felaktiga poster smyger sig in i sjukhusjournaler.
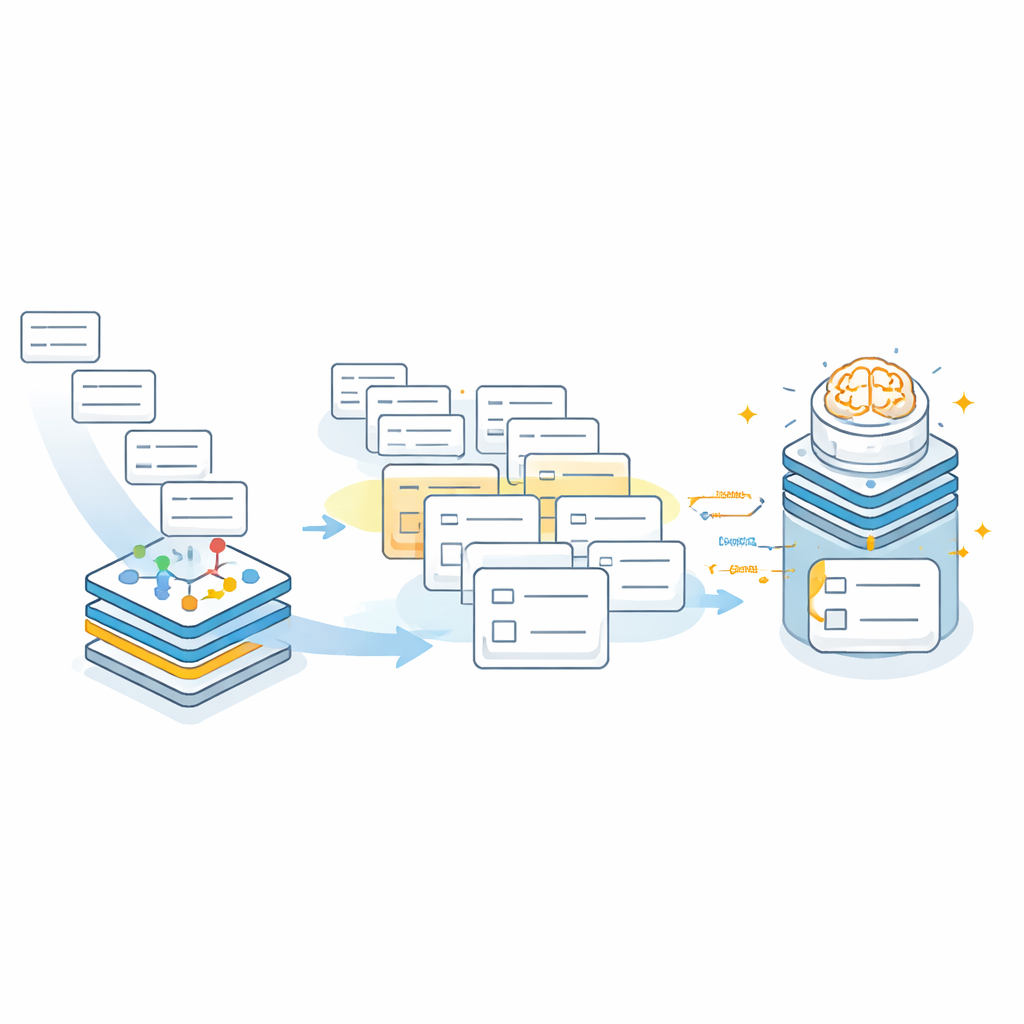
Hur väl fungerar det i praktiken?
Teamet testade AddrKG‑LLM på tiotusen avidentifierade riktiga sjukhusadresser som speglar verklig brusighet: förkortningar, saknade stadsdelar, stavningsvarianter och till och med helt ogiltiga poster. De jämförde sitt system med klassiska sträng-matchningsverktyg, djupinlärningsmodeller för sekvensmärkning, allmänna språkmodeller använda i fri form och en kommersiell tjänst för adressstandardisering. På strikta mått som kräver att varje fält i en adress är korrekt samtidigt överträffade AddrKG‑LLM alla dessa baslinjer och höjde total noggrannhet med mer än tolv procentenheter jämfört med en stark BERT-baserad modell. Vinsterna var särskilt tydliga för förkortade och delvis saknade adresser, där kunskapsgrafens inbyggda hierarki hjälper till att fylla luckor. Författarna undersökte också hur prestandan förändras med olika språkmodellstorlekar och med olika antal hämtade kandidater, vilket visar hur sjukhus kan balansera snabbhet och noggrannhet efter sina behov.
Vad detta betyder för vardaglig vård
För icke-specialister är huvudbudskapet att AddrKG‑LLM erbjuder ett sätt att städa upp viktiga men röriga patientadressdata samtidigt som kontrollen kvarstår hos människor. Genom att koppla en karta-liknande kunskapsgraf till en begränsad språkmodell som körs helt på sjukhusets egna servrar levererar ramverket mer precisa, konsekventa adresser utan att skicka känsliga uppgifter till externa molntjänster eller låta AI:n improvisera. Resultatet är ett praktiskt verktyg som kan stärka smittspårning, förbättra resursplanering och stödja säkrare, mer effektiva sjukhusoperationer — helt enkelt genom att se till att varje patient pålitligt hamnar på kartan.
Citering: Li, J., Pan, X. & Jia, Y. Patient address parsing via KG-aware contrastive learning and constrained on-prem LLM inference. Sci Rep 16, 8003 (2026). https://doi.org/10.1038/s41598-026-39348-z
Nyckelord: patientadressanalys, hälsodata kvalitet, kunskapsgraf, stor språkmodell, medicinsk informatik