Clear Sky Science · sv
Skelett-rörelsetopologi-maskerad prediktion och kontrastinlärning för självövervakad igenkänning av mänskliga handlingar
Lära datorer att läsa kroppsspråk
Från videobelopp till smarta rehabiliteringsverktyg behöver många moderna system förstå vad människor gör enbart genom att observera hur de rör sig. Men att träna datorer att känna igen mänskliga handlingar kräver ofta stora, noggrant märkta dataset där varje vinka, spark eller handslag annoterats för hand. Denna studie introducerar ett sätt för maskiner att lära sig från rå rörelsedata enbart — genom kroppens rörliga skelett — utan etiketter, ansikten eller fullfärgsvideo, vilket gör igenkänningen av handlingar mer exakt, mer privat och mycket mindre beroende av kostsam mänsklig annotering.
Varför skelett är allt som behövs
I stället för att analysera fulla videor arbetar metoden med 3D-skelettdata: koordinaterna för nyckelleder som axlar, armbågar, höfter och knän över tid. Denna avskalade bild av kroppen har flera fördelar. Den undviker i stor utsträckning integritetsproblem eftersom ansikten och kläder elimineras, och den är kompakt nog att bearbetas effektivt även för långa inspelningar. Skelett är också robusta mot röriga bakgrunder och ljusförändringar som kan förvirra vanliga videobaserade system. Trots detta förlitar sig många befintliga skelettbaserade metoder fortfarande i hög grad på märkta exempel och har svårt att fullt ut fånga hur leder rör sig tillsammans i komplexa, samordnade handlingar.
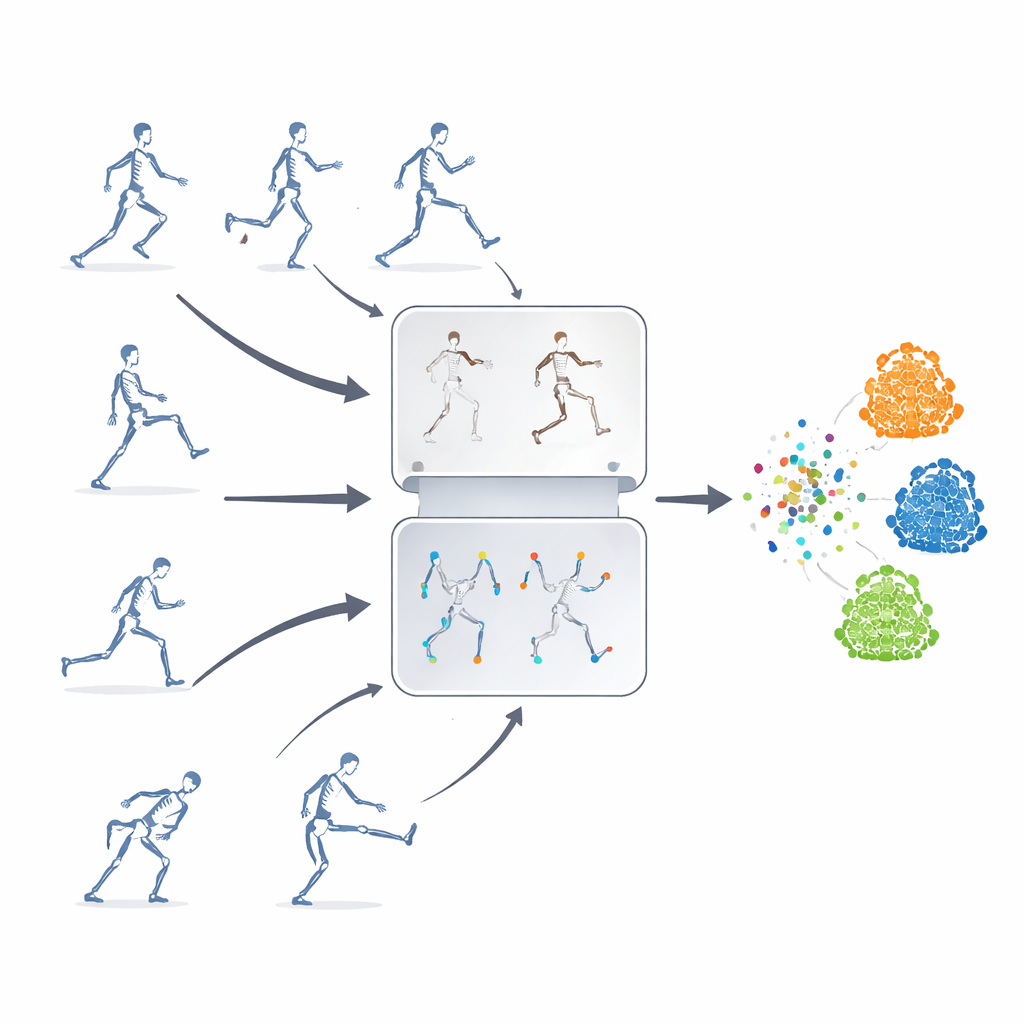
Lära utan etiketter
Författarna föreslår ett självövervakat inlärningsramverk, vilket betyder att systemet lär sig själv från omärkta skelettsekvenser. Deras nyckelidé är att kombinera två kraftfulla strategier som vanligen används separat. Den ena är ”maskerad prediktion”, där delar av skelettdatan avsiktligt döljes så att modellen måste gissa den saknade rörelsen utifrån den återstående kontexten. Den andra är ”kontrastinlärning”, som visar modellen flera förändrade versioner av samma handling och tränar den att inse att dessa variationer fortfarande representerar en underliggande rörelse. Genom att blanda dessa angreppssätt lär sig systemet både finare detaljer om ledernas rörelser och helhetsbetydelsen av en handling.
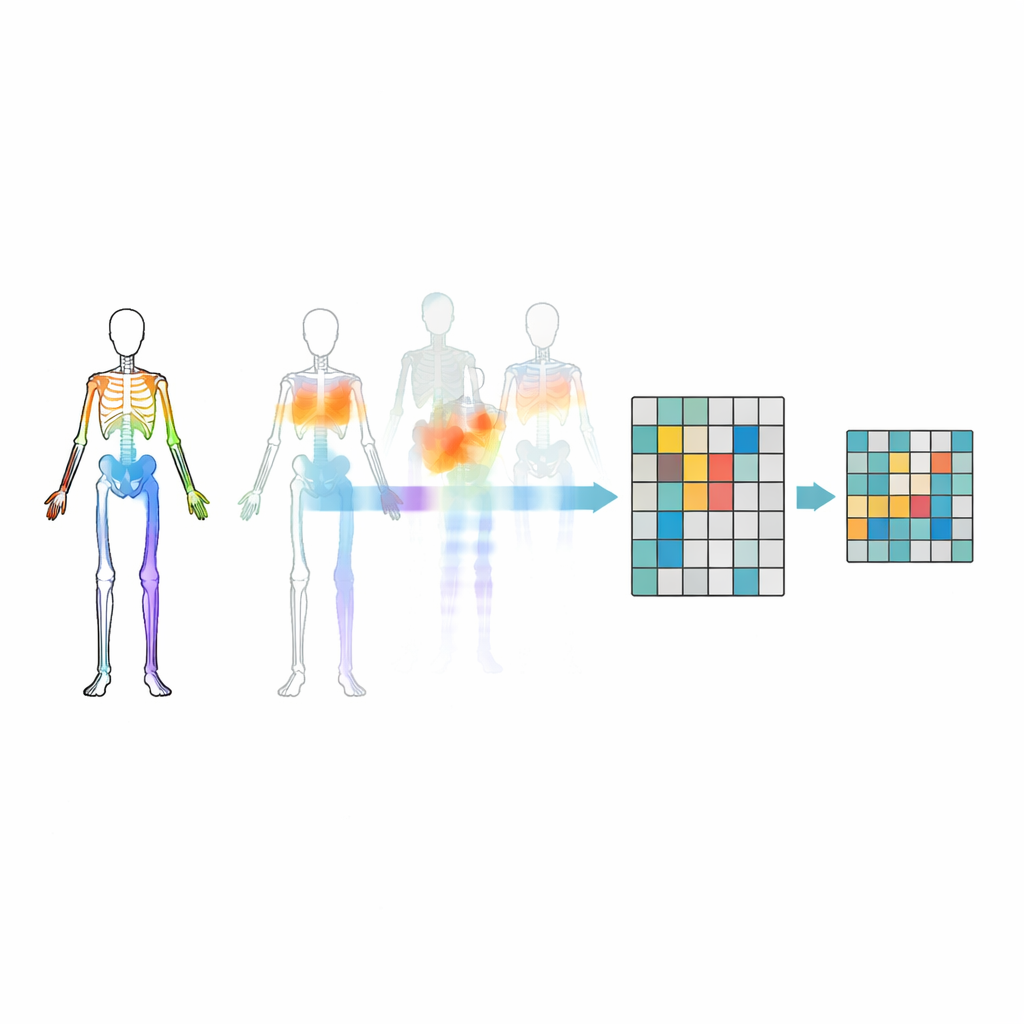
Dölja rätt leder
Att enbart maskera slumpmässiga leder räcker inte — modellen kan komma att ignorera viktiga relationer mellan kroppsdelar eller fokusera på den mest uppenbara rörelsen. För att undvika detta introducerar forskarna en rörelse–topologi-maskeringsstrategi. De grupperar leder i meningsfulla kroppsregioner såsom armar, ben och bålen, och mäter hur starkt varje region rör sig över tid. Maskeringsbeslut styrs både av kroppens struktur och av hur mycket varje region rör sig, så att ibland döljs mycket aktiva delar och modellen tvingas härleda dem från resten av kroppen. Denna riktade doldhet hjälper systemet att lära sig hur leder samarbetar under handlingar, i stället för att bara memorera några iögonfallande rörelser.
Sträcka handlingar på många sätt
För att träna den kontrastiva delen av systemet omvandlas samma ursprungliga skelettsekvens till många olika ”vyer”. Vissa förändringar är milda, såsom att beskära tidsfönstret eller lätt vrida banan, medan andra är mer extrema, inklusive speglingar, rotationer och starkare brus. Dessa flera nivåer av augmentation exponerar modellen för en rik variation av rörelsemönster och uppmuntrar den att fokusera på handlingens kärnstruktur snarare än ytliga detaljer. Samtidigt spårar en bana-styrd funktion-dämpningsmodul vilka rörelsefaktar modellen förlitar sig mest på och dämpar avsiktligt dessa under träningen. Genom att tillfälligt ta bort sina favoritledtrådar pressas systemet att upptäcka reservledtrådar och lära sig mer generella, överförbara representationer.
Hur väl fungerar det?
Ramverket testas på tre stora publika benchmarkdataset för 3D-mänskliga handlingar, som täcker vardagligt beteende, medicinskt relaterade rörelser och interaktioner mellan människor. Trots att det använder enbart skelettleddata och ett relativt lättviktigt rekurrent neuralt nätverk matchar eller överträffar metoden många toppmoderna system som förlitar sig på mer komplexa indata eller arkitekturer. Den är särskilt stark när annotering är knapp eller när vissa kroppsdelar är ockluderade, förhållanden som ofta uppstår i verkliga miljöer. Även om dess förmåga att överföra kunskap mellan mycket olika dataset fortfarande har förbättringspotential, minskar angreppssättet avsevärt klyftan mellan märkt och omärkt träning för igenkänning av handlingar.
Vad detta innebär för system i verkliga världen
För en icke-specialist är slutsatsen att detta arbete visar hur datorer kan bli mycket bättre på att läsa mänskligt kroppsspråk utan att explicit informeras om vad varje rörelse betyder. Genom att smart dölja och förvränga skelettdata under träning lär sig modellen robusta rörelsemönster som håller under dåliga ljusförhållanden, visuellt brus eller saknade leder, och gör det med betydligt färre mänskligt tillhandahållna etiketter. Detta öppnar dörren för mer privata, skalbara och anpassningsbara system för handlingigenkänning i tillämpningar som hemövervakning, idrottsträning, medicinsk rehabilitering och människa–robot-interaktion.
Citering: Hui, Y., Li, F., Hu, X. et al. Skeleton motion topology-masked prediction and contrastive learning for self-supervised human action recognition. Sci Rep 16, 8100 (2026). https://doi.org/10.1038/s41598-026-39330-9
Nyckelord: igenkänning av mänskliga handlingar, 3D-skelettdata, självövervakad inlärning, kontrastinlärning, rörelseanalys