Clear Sky Science · sv
Djupinlärningsbaserad pseudonymisering för att bevara datasekretess för finansiella identifierare i offentliga dokument i Indien
Varför din signatur på ett ID‑kort är i riskzonen
De flesta av oss skriver våra namn på statliga ID‑kort, bankformulär och skattedokument utan att tänka på att de där slingrande linjerna kan kopieras, förfalskas eller utvinnas av hackare. När fler kontor skannar och delar dessa dokument online har handskrivna signaturer — som fortfarande i många sammanhang ses som juridiskt bindande — blivit ett attraktivt mål för identitetsstöld. Denna artikel undersöker en ny metod för att dölja signaturer på indiska skatte‑ID‑kort samtidigt som dokumenten behåller sitt värde för arkivering, revisioner och framtida säkerhetskontroller.
Att omvandla verkliga signaturer till säkra substitut
Författarna fokuserar på Indiens Permanent Account Number (PAN)‑kort, som används i stor utsträckning för finansiella transaktioner och skattedeklarationer. Dessa kort dyker allt oftare upp i e‑post, molnlagring och offentliga inlämningar, där blottlagda signaturer kan kopieras eller tryckas på falska handlingar. Att helt enkelt sudda ut eller svartmåla signaturen skyddar visserligen integriteten men förstör dokumentets värde för senare verifiering eller utredning. Istället använder forskarna en strategi kallad pseudonymisering: den ursprungliga signaturen upptäcks och ersätts med en syntetisk look‑alike som behåller placering och struktur av märket, men inte längre matchar personens handstil tillräckligt nära för att kunna missbrukas.
Hur ett smart visionsystem hittar vad som ska döljas
För att automatisera processen bygger teamet vidare på en djupinlärningsmodell känd som SuperPoint, ursprungligen utformad för att hitta viktiga punkter i bilder — som hörn och kanter — som är stabila även om bilden är brusig, sned eller något suddig. Metoden förbehandlar först PAN‑kortsskanningar genom att ändra storlek och konvertera dem till gråskala för att förenkla beräkningarna. Därefter isoleras regionen som innehåller signaturen. Inom det området fungerar SuperPoint‑nätverket som en specialiserad förstoringsglas: en del av nätverket producerar en värmekarta som visar var distinkta pennstreck finns, och en annan del genererar kompakta numeriska beskrivningar av dessa streck. Denna kombination gör att systemet kan lokalisera exakt vilka delar av handstilen som är mest karaktäristiska — och därmed mest riskfyllda att lämna blottade.
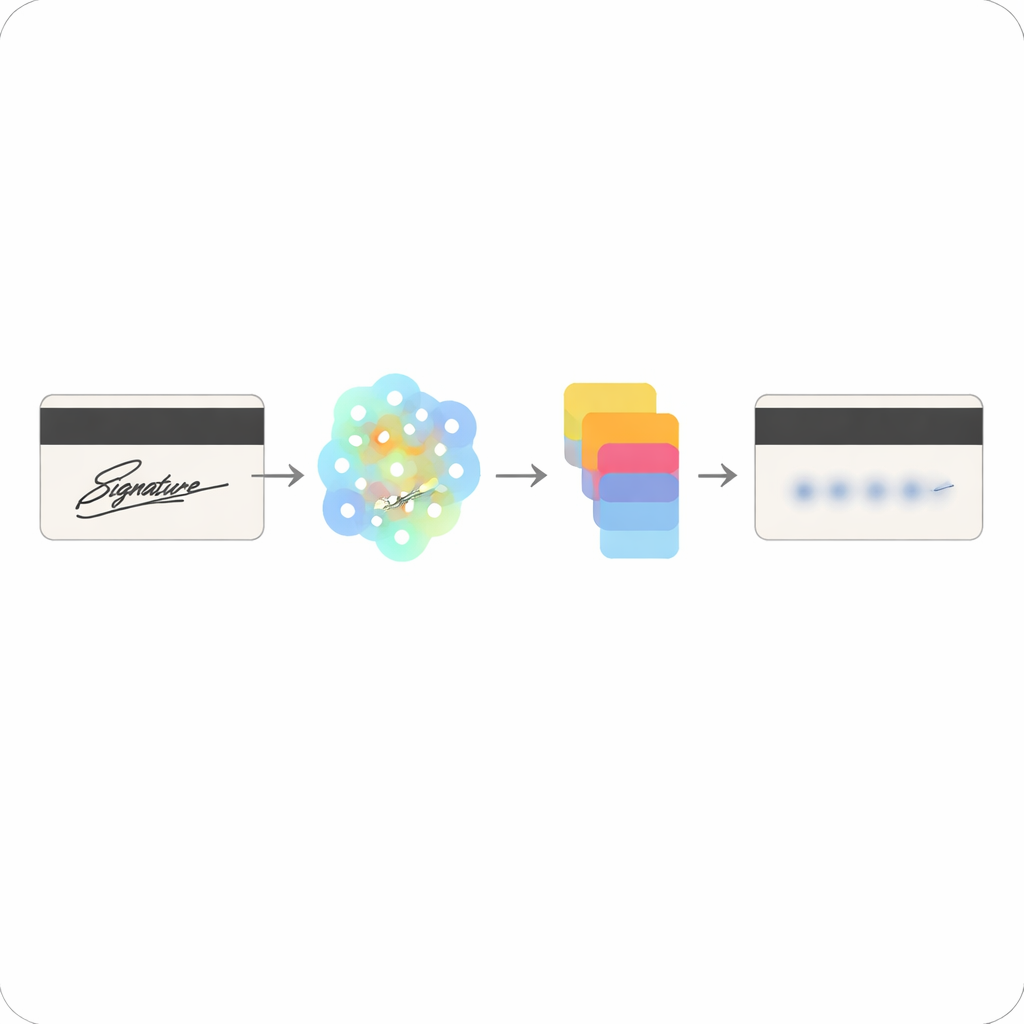
Från streck och nyckelpunkter till maskade märken
När de viktiga positionerna i signaturen identifierats ersätter systemet dem med neutrala former som bevarar det övergripande intrycket av ett signerat område utan att avslöja författarens personliga stil. Istället för att lagra det ursprungliga bläckmönstret förlitar sig modellen på abstrakta feature‑kartor — matematiska sammanfattningar av var nyckelpunkterna fanns — vilket gör det betydligt svårare för en angripare att rekonstruera den verkliga signaturen. Författarna använder också ett verktyg kallat Kornia för att omvandla nätverkets råa utsignaler till precisa koordinater, skalor och orienteringar, vilket hjälper till att säkerställa att den maskade regionen ligger i linje med det ursprungliga signaturområdet och fungerar över olika kortlayouter och skanningskvaliteter.
Hur väl den nya metoden står sig
Ramen testas på mer än 500 verkliga PAN‑kortsbilder hämtade från öppna dataset, som täcker många handstilar och kortdesigner. Dess prestanda jämförs med i stor utsträckning använda traditionella feature‑identifieringsmetoder — ORB, FAST och SIFT — samt ett djupt residualnätverk. Forskarna mäter hur noggrant systemet hittar signaturdetaljer, hur nära det maskade dokumentet förblir originalet i utseende, och hur mycket beräkningskraft och lagring som krävs. Deras metod uppnår hög precision och recall i att lokalisera de avgörande delarna av signaturerna och når en strukturell likhetspoäng på cirka 97 procent, vilket betyder att de pseudonymiserade korten ser nästan identiska ut med originalen förutom de skyddade markeringarna. Samtidigt använder den ett måttligt antal nyckelpunkter och kompakta deskriptorer, vilket balanserar noggrannhet, snabbhet och minnesanvändning.
Vad detta betyder för vardaglig integritet
För icke‑specialister är huvudbudskapet att det nu är möjligt att automatiskt skydda ett av de mest känsliga elementen på ett ID‑kort — din handskrivna signatur — utan att förvandla dokumentet till en värdelös svartskriven rektangel. Genom att ersätta riktiga signaturer med noggrant konstruerade substitut tillåter det föreslagna systemet att myndigheter och organisationer delar, lagrar och analyserar skannade ID‑handlingar samtidigt som risken för förfalskning och identitetsstöld minskar kraftigt. Författarna föreslår att liknande djupinlärningsverktyg kan byggas in i offentliga myndigheters dokumentflöden, hjälpa länder att uppfylla moderna sekretessregler såsom GDPR, och så småningom kunna utvidgas bortom PAN‑kort till pass, licenser och andra identitetshandlingar globalt.
Citering: Roopalakshmi, R., Kailas, S. & Sreelatha, R. Deep learning enabled pseudonymization for preserving data privacy of financial identifiers in public documents in India. Sci Rep 16, 8120 (2026). https://doi.org/10.1038/s41598-026-39309-6
Nyckelord: signatursekretess, identitetsskydd, dokumentavidentifiering, djupinlärningssäkerhet, statliga ID‑kort