Clear Sky Science · sv
En CNN-RNN-siamesisk ram med flernivå-aggregation för videobaserad personåteridentifiering
Varför det är viktigt att följa personer över kameror
Moderna städer täcks av kameror, men dessa kameror "pratar" sällan med varandra. När en person går från ett gatuhörn till en tågstation ser olika kameror personen från nya vinklar, i varierande ljus och ofta genom folksamlingar. Att automatiskt känna igen att det är samma person i olika videoklipp — kallat videobaserad personåteridentifiering — kan hjälpa utredare att spåra rörelser efter en händelse, stödja sökandet efter försvunna personer eller möjliggöra analys i välbesökta offentliga miljöer. Att göra detta noggrant och effektivt, särskilt på modest hårdvara, är dock en stor teknisk utmaning.
En enklare hjärna för att matcha rörliga personer
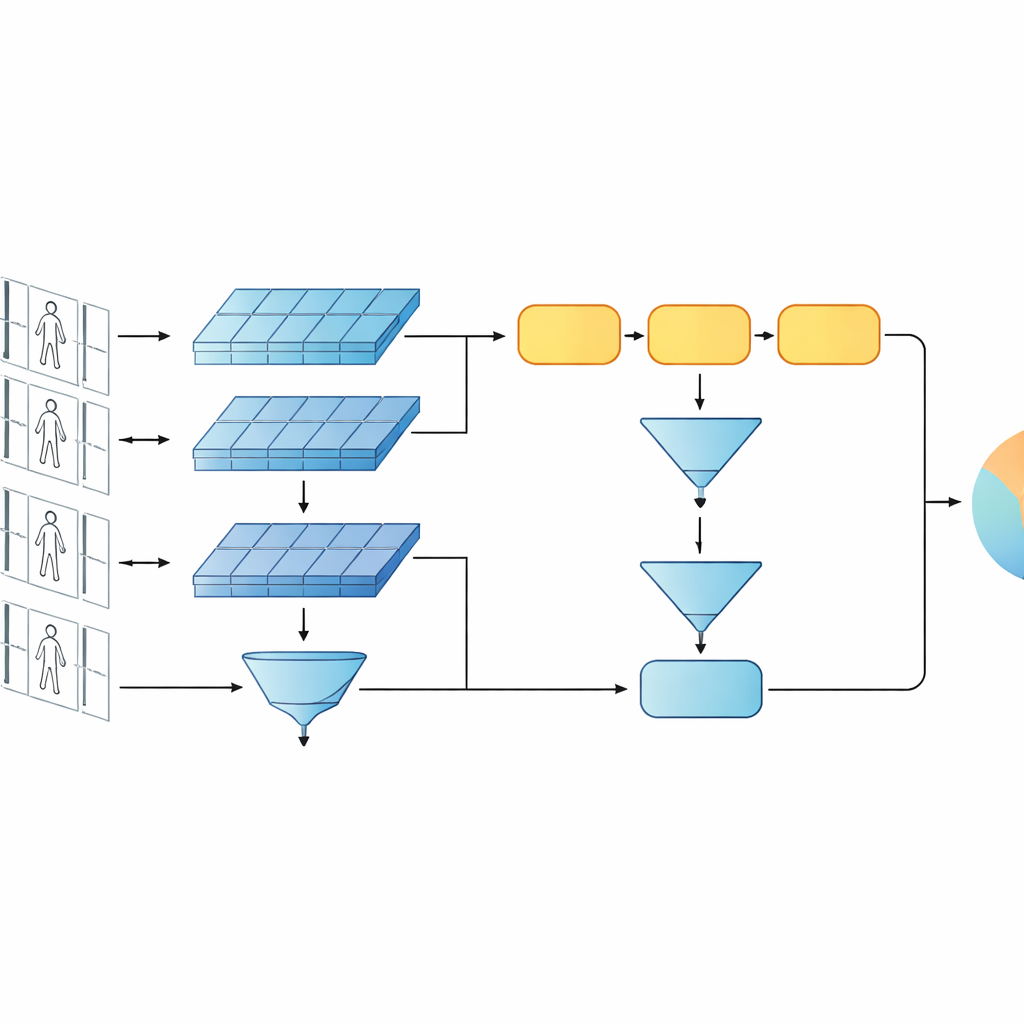
Denna studie presenterar ett kompakt AI-system utformat för att avgöra om två korta videoklipp visar samma person. Istället för att använda dagens trend med mycket djupa eller transformerbaserade nätverk bygger författarna vidare på en slankare design som kombinerar två klassiska ingredienser: ett konvolutionsnät som analyserar varje videoruta och en gated recurrent unit (GRU) som följer hur utseendet förändras över tid. Dessa två grenar är ordnade i en siamesisk layout — i praktiken tvillingkopior av samma nätverk som delar alla interna inställningar. Varje tvilling bearbetar en videosekvens, och systemet lär sig producera liknande interna signaturer för klipp av samma person och tydligt olika signaturer för olika personer.
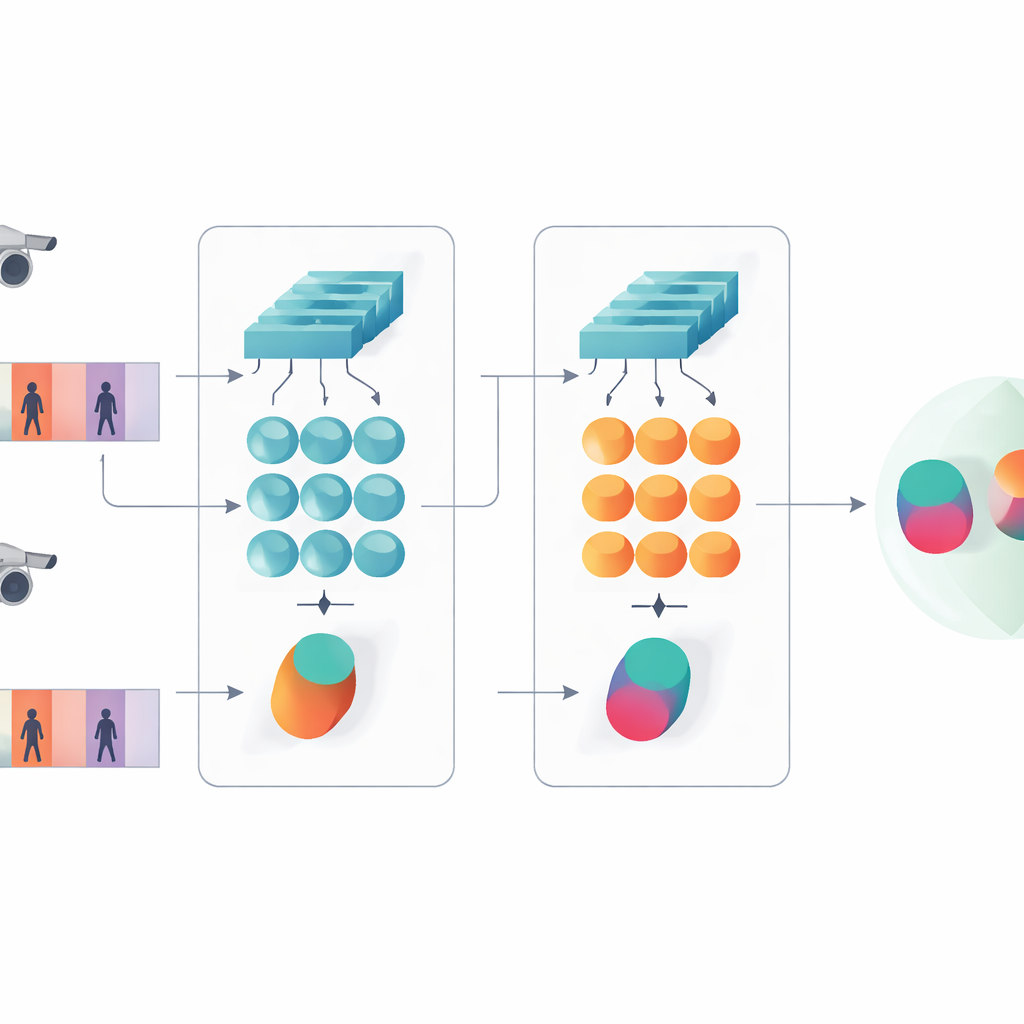
Se både detaljer och mönster över tid
En nyckelidé i arbetet är att igenkänning inte bara bör förlita sig på nätverkets djupaste, mest abstrakta funktioner. Tidigare lager innehåller fortfarande skarpa visuella detaljer som tygstruktur på en jacka, ränder på byxor eller konturen av en ryggsäck — ledtrådar som ofta överlever förändringar i kameravinkel. Den föreslagna modellen behåller därför två nivåer av beskrivning. Den ena grenen poolar tidiga lagningsfunktioner över alla rutor för att sammanfatta fint textur- och lokalbildsinformation. Den andra grenen matar senare funktioner till GRU:n, som följer sekvensen ruta för ruta och sedan genomsnittar sina interna tillstånd över tiden. Detta genomsnittstagande undviker att överbetona de sista rutorna och fångar istället en samlad bild av hur personen ser ut och rör sig i hela klippet.
Träna tvillingnäten att enas och att klassificera
För att lära systemet vad som är viktigt kombinerar författarna två träningsmål. Först uppmuntrar ett verifieringsmål de tvillinggrenar att producera närliggande signaturer för videor av samma person och avlägsna signaturer för olika personer. För det andra ber en klassificeringsuppgift nätverket att tilldela varje träningsklipp en specifik identitet. Genom att optimera båda samtidigt, och genom att göra detta på både låg- och högre featuresnivå, lär sig modellen interna beskrivningar som inte bara är distinkta mellan personer utan också robusta mot brus, ocklusion och tillfälligt dåliga rutor. Designen förblir grunda vad gäller lager och parametrar, vilket hjälper till att undvika överanpassning på relativt små videodatamängder.
Testning på verklighetsnära övervakningsvideor
Ramverket utvärderas på två välanvända videobenchmarks, PRID-2011 och iLIDS-VID, som innehåller korta gångsekvenser med hundratals individer fångade från par av diskreta kameror. Studien undersöker noggrant olika designval: att byta ut GRU mot andra rekurrenta enheter, ändra hur många rekurrenta lager som används, variera hur funktioner poolas över tiden och slå av eller på låg- respektive hög-nivå-grenarna. I dessa tester levererar en enkel-lagers GRU med medelpoolning och den fulla flernivåuppsättningen konsekvent bäst noggrannhet. Modellen matchar eller överträffar många mer komplexa rekurrenta och siamesiska system och presterar konkurrenskraftigt med vissa attention-baserade designer, samtidigt som den använder betydligt färre parametrar och beräkningar.
Effektivitet för verkliga implementationer
Utöver noggrannhet betonar arbetet praktisk användbarhet. Hela nätverket har bara omkring en till två miljoner träningsbara parametrar — flera ordningar färre än populära djupa residual- eller transformerbaserade backbones — och kräver en bråkdel av deras beräkningskostnad per ruta. Detta gör det mer lämpligt för implementation på enheter med begränsat minne och beräkningskraft, såsom edge-servrar nära kameror. Experiment visar också att längre galleri-sekvenser, där systemet ser fler rutor av varje lagrad person, förbättrar igenkänningen avsevärt, om än med en linjär ökning av bearbetningskostnaden. Författarna menar att sådana kompakta, omsorgsfullt utformade arkitekturer kan leverera pålitlig personåteridentifiering utan den höga kostnaden hos dagens största modeller.
Vad detta betyder för vardagliga övervakningssystem
Enkelt uttryckt visar denna artikel att smart design kan slå ren storlek: genom att kombinera grundläggande bildanalys, lättviktig sekvensmodellering och en tvånivåsyn på visuell likhet är det möjligt att spåra vem som är vem över kameror med hög tillförlitlighet samtidigt som modellen hålls liten och snabb. För framtida system som måste köras på många kameror, ofta med knappa hårdvaru- och energiresurser, kan denna typ av effektiv, flernivålösning bidra till att föra mer kapabel och ansvarsfull videoanalys in i verklig användning.
Citering: Wang, YK., Pan, TM. & Sun, CP. A CNN-RNN Siamese framework with multi-level aggregation for video-based person re-identification. Sci Rep 16, 8224 (2026). https://doi.org/10.1038/s41598-026-39277-x
Nyckelord: personåteridentifiering, videoövervakning, siamesiska neurala nätverk, temporell modellering, effektiv djupinlärning