Clear Sky Science · sv
En robust ram för text‑till‑SQL från naturligt språk med dynamiska strategier baserade på LLM
Att förvandla vardagliga frågor till databassvar
Moderna organisationer sitter på stora mängder data, men de flesta kan inte tala det tekniska språk som krävs för att ställa frågor mot den. Denna artikel presenterar TriSQL, ett system som låter användare ställa frågor på vanligt språk och automatiskt omvandla dem till precisa databaskommandon. Genom att noggrant styra hur stora språkmodeller hanterar komplexitet syftar ramverket till att göra dataåtkomst både mer korrekt och mer pålitlig, även för de svåraste frågorna.
Varför det är så svårt att prata med databaser
När någon skriver en fråga som ”Vilka kunder köpte fler än fem produkter förra månaden?” måste en dator översätta det till SQL, det specialiserade språket som används av de flesta databaser. Denna uppgift, kallad text‑till‑SQL, låter enkel men är förvånansvärt svår. Systemet måste förstå vad användaren vill, hitta rätt tabeller och kolumner i en ibland enorm och rörig databas, och sedan bygga en fråga som både är strukturellt giltig och trogen den ursprungliga avsikten. Tidigare system, inklusive de som drivs av stora språkmodeller, fallerar ofta när frågor involverar många tabeller, nästlad logik eller subtila villkor. De kan generera frågor som ser ut att vara korrekta men som inte går att köra eller som ger felaktiga resultat vid exekvering.
En trestegsresa från fråga till fråga
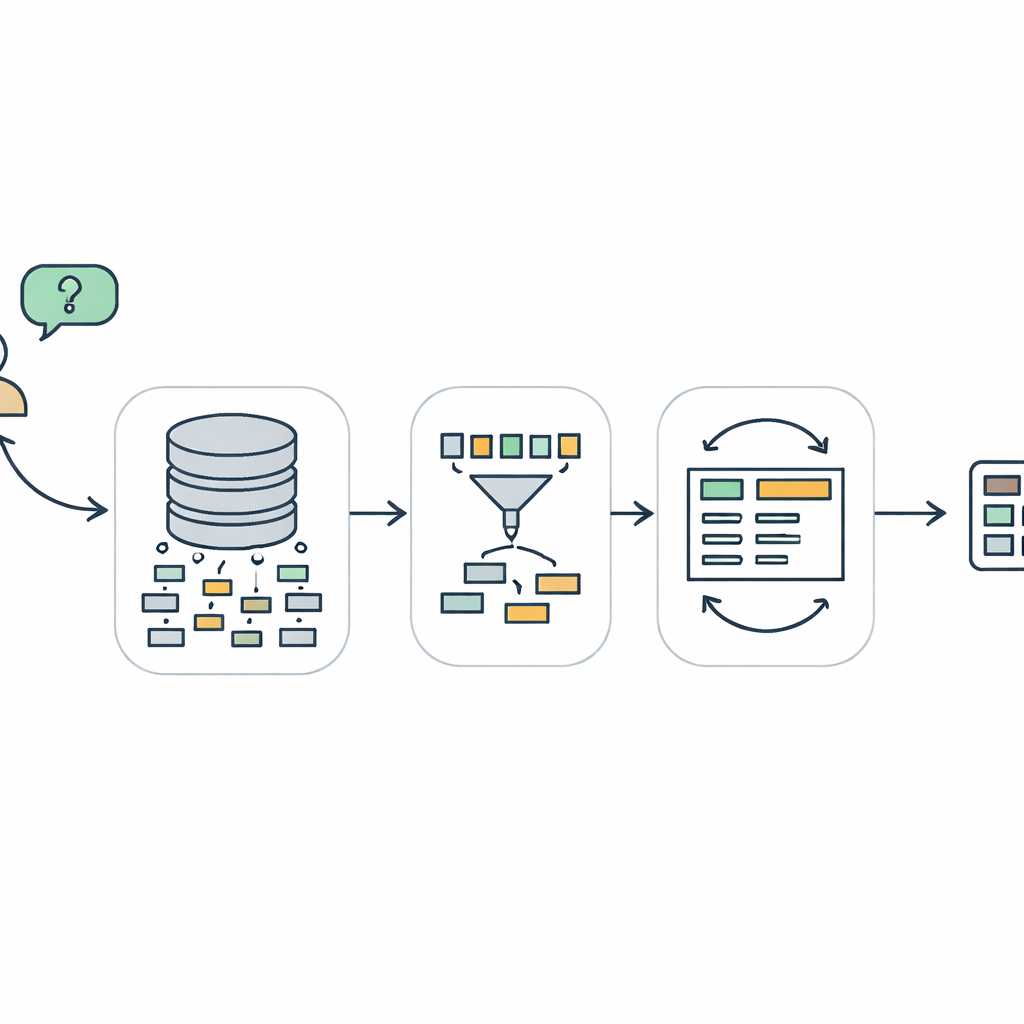
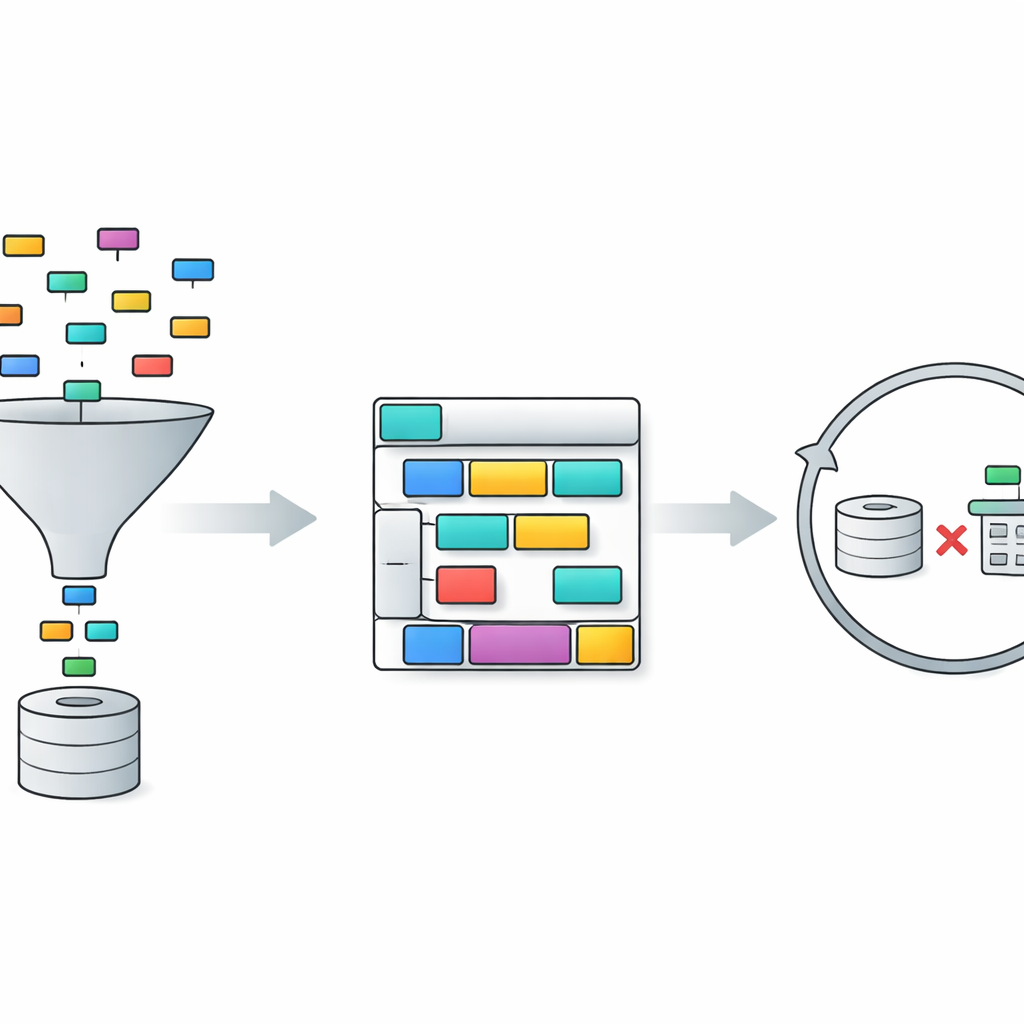
TriSQL angriper dessa problem med en trestegs pipeline. Först tittar en fråga‑styrd selektor på användarens ord och hela databasstrukturen och avgör vilka tabeller och kolumner som faktiskt är relevanta. Istället för att blint exponera språkmodellen för hela schemat begränsar den vyn till de delar som spelar roll. För det andra planerar en struktur‑medveten generator formen på SQL‑frågan innan detaljer fylls i. Den skissar först ett hög‑nivå skelett—vilka klausuler som behövs och hur de passar ihop—och sätter sedan in specifika tabeller, joinar och villkor. Detta ”struktur först, innehåll sedan”‑förhållningssätt hjälper till att bevara SQL:s strikta grammatik, särskilt för långa och invecklade frågor. Slutligen kontrollerar och förbättrar en komplexitetsmedveten förfinare den initiala frågan, med olika strategier beroende på hur svår frågan bedöms vara.
Anpassa insatsen efter frågans svårighetsgrad
Förfiningssteget är där TriSQL gör särskilt nyskapande användning av stora språkmodeller. Systemet poängsätter hur komplex varje fråga och utkast till fråga är, med hänsyn till faktorer som hur många tabeller som joinas, hur djupt eventuella nästlingar går och vilka typer av begränsningar som används. För enkla fall tillämpar det endast lätta korrigeringar, som att åtgärda små syntaxfel. För medelsvåra fall omorganiserar det klausuler och säkerställer att frågan stämmer överens med det valda schemat. För de mest krävande frågorna anropar det språkmodellen för djupare resonemang, ibland genom att dela upp problemet i deluppgifter och köra alternativa frågor. Viktigt är att TriSQL sedan exekverar både original‑ och förfinade frågor mot databasen och använder deras beteende—om de körs, hur lång tid de tar och vad de returnerar—för att avgöra vilken version som ska behållas eller om ytterligare förfining bör göras.
Sätta systemet på prov
För att utvärdera TriSQL testar författarna det på en mycket använd benchmark kallad Spider, tillsammans med flera hårdare varianter som introducerar domänkunskap, ovanliga meningsmönster och mer realistiska frågestrukturer. De mäter två saker: exact match, som kontrollerar om den genererade SQL‑strängen är identisk med en människoskriven referens, och exekveringsnoggrannhet, som kontrollerar om den faktiskt producerar rätt svar vid körning. Över dessa dataset uppnår TriSQL den högsta exekveringsnoggrannheten som rapporterats hittills samtidigt som exact match hålls konkurrenskraftig med de bästa tidigare systemen. Det är också mer robust: när frågor går från lätta till extremt svåra sjunker TriSQLs prestanda mycket mjukare än konkurrenternas. Ytterligare experiment på en verklig dataset för kraftnätsstyrning visar att samma ramverk kan hantera inte bara datahämtning utan också insert-, update‑, delete‑ och tabell‑skapande kommandon. Pilotanpassningar till grafdatabaser (Cypher) och MongoDB‑pipelines tyder på att trestegsdesignen kan sträcka sig bortom klassisk SQL.
Vad detta betyder för vardaglig dataanvändning
Enkelt uttryckt för oss detta arbete närmare en värld där människor kan föra samtal med komplexa databaser lika enkelt som de i dag chattar med sökmotorer. Genom att noggrant välja vilka delar av databasen som ska beaktas, genom att planera strukturen för en fråga innan detaljer fylls i, och genom att justera användningen av stora språkmodeller efter varje frågas svårighetsgrad, producerar TriSQL frågor som är mer benägna att köras korrekt och ge avsedda resultat. Visserligen återstår utmaningar—som att hantera tvetydiga frågor och aldrig sedda databaser—men studien visar att en genomtänkt, stegvis design kan göra gränssnitt för naturligt språk mot data både mer kraftfulla och mer förutsägbara för vardagliga användare.
Citering: Su, X., Gu, Y., Wang, P. et al. A robust natural language text-to-SQL generation framework with dynamic strategies based on LLMs. Sci Rep 16, 7892 (2026). https://doi.org/10.1038/s41598-026-39128-9
Nyckelord: text‑till‑SQL, gränssnitt för naturligt språk, databasfrågor, stora språkmodeller, frågerobusthet