Clear Sky Science · sv
En metod för att hantera obalanserade dataset genom grensförskjutning
Varför sällsynta fall spelar roll i vardaglig data
Från bankbedrägerier och medicinska diagnoser till att förutse kundavhopp—många av de beslut vi ber datorer fatta bygger på att upptäcka sällsynta men avgörande händelser. I de flesta verkliga dataset är dessa viktiga fall drastiskt underrepresenterade jämfört med vanliga fall. En modell som mestadels ser ”business as usual” kan bli blind för just de situationer vi bryr oss mest om. Denna artikel presenterar ett nytt sätt att återbalansera sådan snedvriden data så att inlärningsalgoritmer ägnar rimlig uppmärksamhet åt de sällsynta, högeffektiva fallen.
Den dolda fällan i snedfördelad data
När en typ av exempel kraftigt överstiger en annan tenderar standardmetoder inom maskininlärning att fokusera på majoriteten och tyst försumma minoriteten. Ett system för att förutse churn kan till exempel märka nästan alla som lojala kunder och ändå redovisa hög noggrannhet, helt enkelt därför att verkliga churnare är så få. Liknande problem uppstår vid olycksupptäckt, bedrägerimonitorering och medicinsk screening, där positiva fall är sällsynta men kostsamma att missa. Traditionella sätt att åtgärda detta faller i två läger: att justera inlärningsalgoritmen så att den ”bryr sig” mer om minoriteten, eller att omforma själva datan genom att antingen ta bort vissa majoritetsfall (undersampling) eller skapa extra minoritetsfall (oversampling). Populära oversampling-verktyg som SMOTE genererar syntetiska minoritetsexempel, men de kan omedvetet överbelasta den känsliga gränsregion där de två klasserna möts.
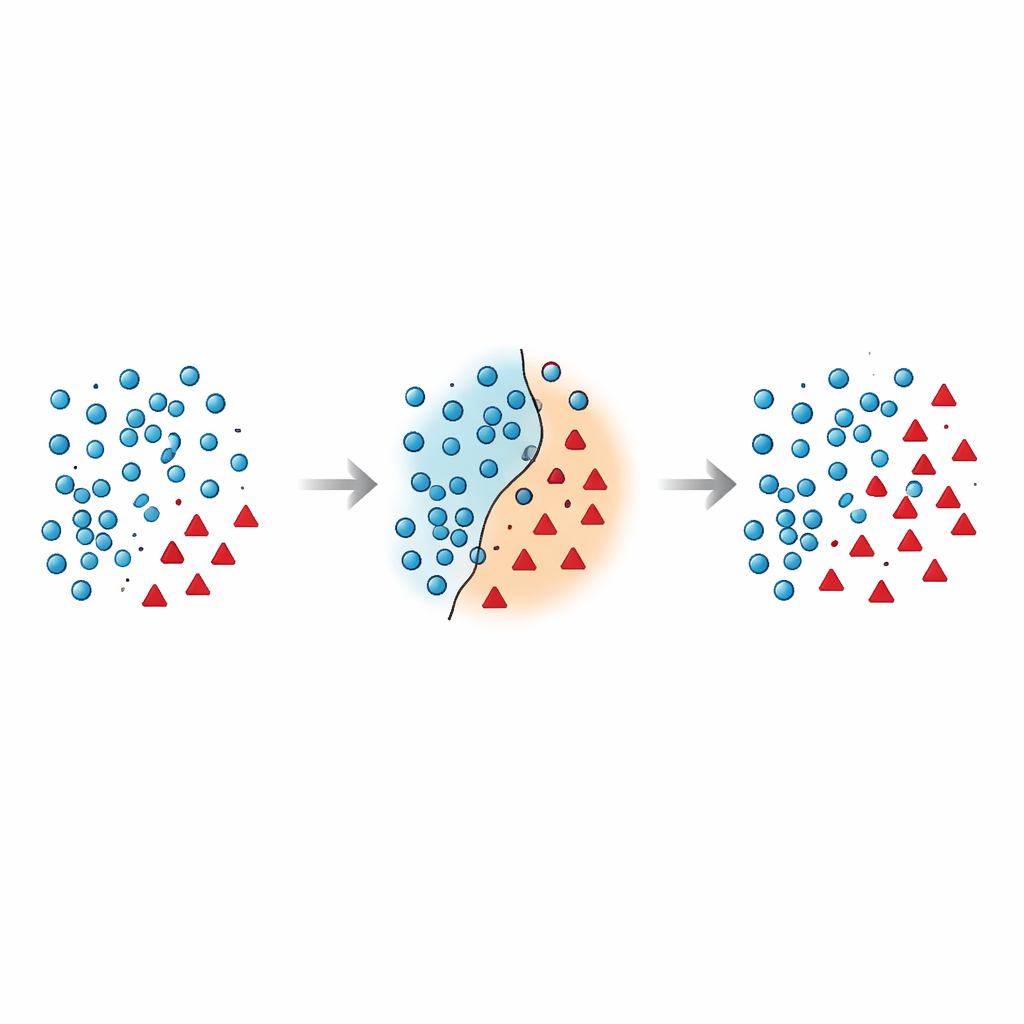
Varför gränsen mellan grupper är så bräcklig
Författarna hävdar att de farligaste misstagen sker nära beslutsgränsen – zonen där majoritets- och minoritetsfall överlappar i feature‑rymden. Många befintliga tekniker lägger antingen till syntetiska punkter i denna riskfyllda region utan att rensa upp, eller de tar aggressivt bort data och råkar samtidigt eliminera informatíva exempel. Nyare forskning har försökt hantera detta genom geometriska begränsningar, lokala densitetsuppskattningar eller brusfilter, men de flesta metoder behandlar fortfarande minoritetspunkter på plats och omprövar sällan hur majoritetspunkter nära gränsen bör hanteras. Detta lämnar ett kvarstående problem: överlappande och brusiga exempel som förvirrar klassificeraren och leder till ostabila prediktioner, särskilt på ny data.
En tvåstegsmetod för att reda upp gränsen
Artikeln introducerar Borderline Shifting Oversampling (BSO), en tvåfasig datastruktureringsmetod som uttryckligen riktar in sig på denna problematiska gränsregion. Först skannar den omgivningen runt varje majoritetsexempel för att avgöra om det ligger i en trygg zon, på gränsen eller på en uppenbart felaktig plats (brus). Majoritetspunkter omgivna av minoritetsgrannar antingen omklassificeras mot minoritetssidan eller markeras som brus och tas bort, vilket effektivt rensar och förskjuter gränsen så att den bättre speglar det underliggande mönstret. I den andra fasen genererar metoden nya syntetiska minoritetspunkter med en SMOTE‑lik interpolering, men endast kring minoritetsexemplar nära den förfinade gränsen. Genom att koncentrera ny data där den är mest informativ och undvika uppenbart brusiga punkter bygger BSO ett träningsset som både är mer balanserat i storlek och renare i struktur.
Att testa metoden i praktiken
För att se hur väl detta fungerar i praktiken utvärderade forskarna BSO på 30 referensdataset med varierande grad av obalans och överlapp. De jämförde den med sju allmänt använda alternativ, inklusive Random Over‑ och Under‑Sampling, SMOTE, Borderline‑SMOTE, NearMiss samt två hybrida metoder som blandar oversampling med brusrensning (SMOTE‑Tomek och SMOTE‑ENN). Tre vanliga klassificerare – Support Vector Machines, Naïve Bayes och Random Forests – tränades på varje omsampat dataset. Istället för att förlita sig på rå noggrannhet använde studien mått som är mer informativa vid obalans, såsom F1‑score, G‑mean, recall, precision och AUC (Area Under the ROC Curve). I nästan samtliga dataset och för alla klassificerare gav BSO högre eller jämförbara poäng samtidigt som variationen var mindre, vilket innebär att vinsterna var konsekventa snarare än beroende av en viss modell eller inställning.
Vad detta innebär för verkliga beslut
I vardagliga termer agerar Borderline Shifting‑metoden som en noggrann redaktör för rörig data: den rensar förvirrande exempel nära skiljelinjen mellan klasser och lägger sedan till precis tillräckligt med realistiska minoritetsfall på rätt ställen. Resultatet är att inlärningsalgoritmer blir bättre på att känna igen sällsynta men viktiga händelser utan att vilseledas av brusiga överlapp. För tillämpningar som bedrägeridetektion, olycksförutsägelse eller medicinsk triage—där det kan vara kostsamt att missa ett minoritetsfall—erbjuder denna metod ett praktiskt sätt att göra modeller rättvisare, mer känsliga och mer tillförlitliga, samtidigt som den endast tillför en måttlig beräkningskostnad.
Citering: Malhat, M.G., Elsobky, A.M., Keshk, A.E. et al. An approach for handling imbalanced datasets using borderline shifting. Sci Rep 16, 8264 (2026). https://doi.org/10.1038/s41598-026-39118-x
Nyckelord: klassobalans, översampling, beslutsgräns, anomalidetektion, maskininlärningsrobusthet