Clear Sky Science · sv
DeCon-Net: avkopplad hierarkisk kontrast för objektigenkänning i fotboll
Varför det är svårare än det ser ut att upptäcka spelare och bollen
Moderna fotbollssändningar är fyllda med grafik, statistik och reprisbilder, alla drivna av datasystem som först måste svara på en förvånansvärt enkel fråga: var är spelarna och bollen i varje bildruta? Denna artikel tar upp varför dagens ledande artificiella intelligensverktyg fortfarande har problem med den grundläggande uppgiften i verkliga matcher — och presenterar en ny metod, DeCon‑Net, som gör automatisk upptäckt av spelare och boll mycket mer pålitlig, särskilt i röriga, trånga scener.
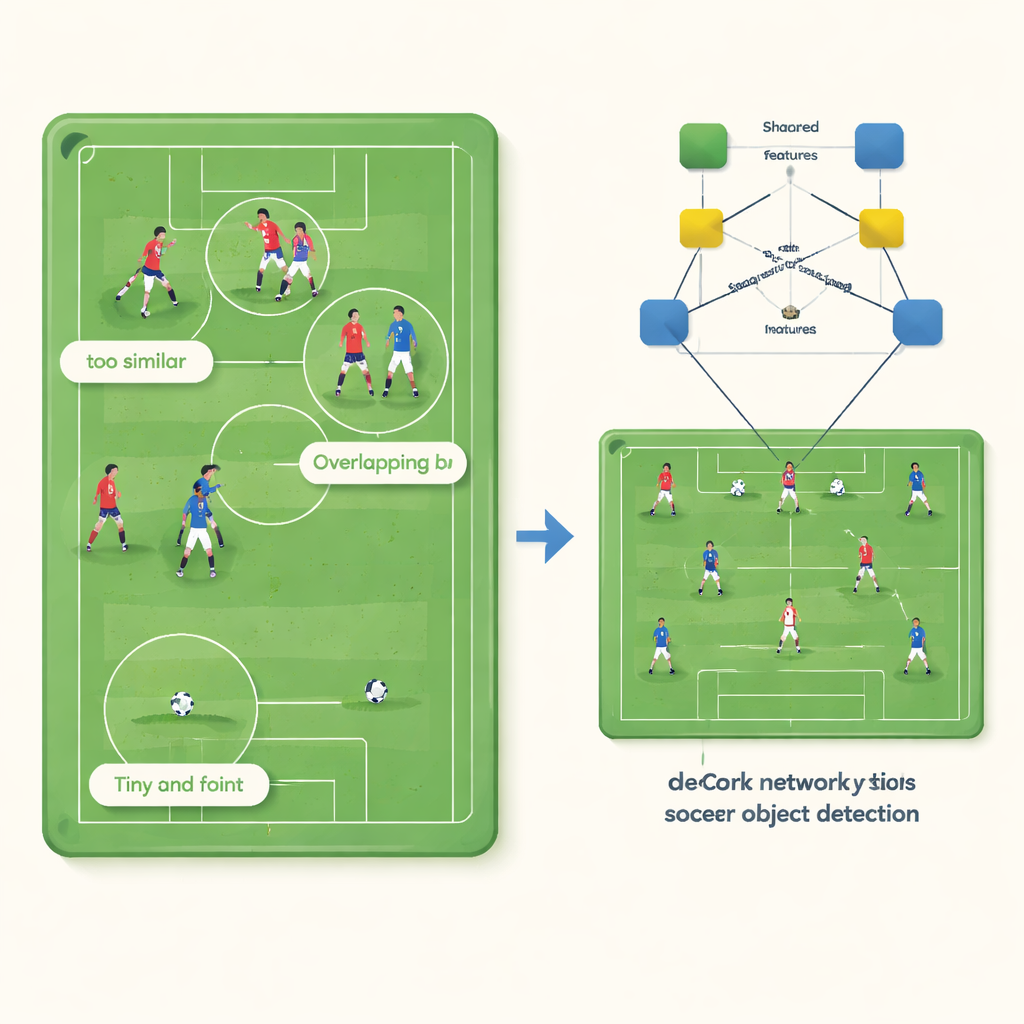
Tre dolda problem i fotbollsfilmer
Vid första anblicken verkar det enkelt att upptäcka spelare och boll: de rör sig, har tydliga former och står ut mot planen. Men författarna visar att standardiserade datorseendesystem lider av tre sammanflätade problem. För det första blir lagkamrater som bär identiska dräkter nästan omöjliga att skilja åt för algoritmen, vars interna „feature“-beskrivningar kollapsar till nästan identiska punkter. För det andra, i trängda närkamper överlappar spelare så mycket att detektorer ofta ritar en stor begränsande ruta runt flera personer istället för separata rutor för varje individ. För det tredje är bollen liten — ibland bara några tiotal pixlar — och dess visuella signal är så svag att den kan överröstas av grässtruktur och spelarrörelser, vilket gör att systemet helt missar den.
Att dela upp vad nätverket lär sig
DeCon‑Net tar itu med dessa problem genom att ändra hur ett neuralt nätverk representerar det det ser i en bildruta. Istället för att låta modellen lära en sammanblandad beskrivning för varje objekt delar författarna upp den beskrivningen i två kompletterande delar. En kanal fångar vad spelare i samma lag har gemensamt — som tröjfärg — medan den andra fokuserar på vad som gör varje individ unik, som kroppsställning eller exakt position. Ett särskilt träningsknep inverterar gradienten för „individ“-kanalen när nätverket försöker använda laginformation där, vilket effektivt lär den att ignorera tröjfärg och koncentrera sig på personspecifika ledtrådar. De två kanalerna kombineras sedan adaptivt, så att systemet kan förlita sig mer på delade drag i enkla scener och mer på individuella drag när spelare trängs.
Att lära modellen med jämförelser, inte bara etiketter
Utöver denna uppdelade representation omformar DeCon‑Net själva inlärningen. Metoden lägger till ett hierarkiskt „kontrastivt“ träningssteg som ständigt jämför par av detekterade objekt. Par som redan är tydligt olika får milda justeringar, medan par som ser förvirrande lika ut — som två lagkamrater stående axel vid axel — tränas mer aggressivt för att driva isär dem i nätverkets interna rum. Denna trestegsstrategi börjar med enkla åtskillnader, går vidare till subtilare skillnader inom ett lag och avslutas med variationer över olika matcher och sändningsförhållanden. För att rädda den lilla bollen från att förbises ökar metoden också vikten av mycket små objekt under träningen, vilket gör att bollens signal framträder istället för att försvinna i bakgrundsbrus.
Från laboratoriebenchmarks till verkliga sportsändningar
Forskarna testade DeCon‑Net på två krävande dataset: SportsMOT, som inkluderar fotboll, basket och volleyboll, och SoccerNet‑Tracking, byggt från verkliga TV-sändningar med kamerazoom, rörelseoskärpa och frekventa ockluderingar. Över hela linjen detekterade DeCon‑Net både spelare och bollar mer precist än vida använda system baserade på Faster R‑CNN, DETR och nyligen framtagna metoder inriktade på spårning. Vinsterna var särskilt markanta för bollen, med en noggrannhetsökning på mer än 40 procent jämfört med starka baslinjer. Systemet höll sig också bättre när det applicerades på ett annat dataset än det det tränats på, vilket antyder att dess uppdelade funktionsdesign fångar mer generella, återanvändbara ledtrådar om sportscener.
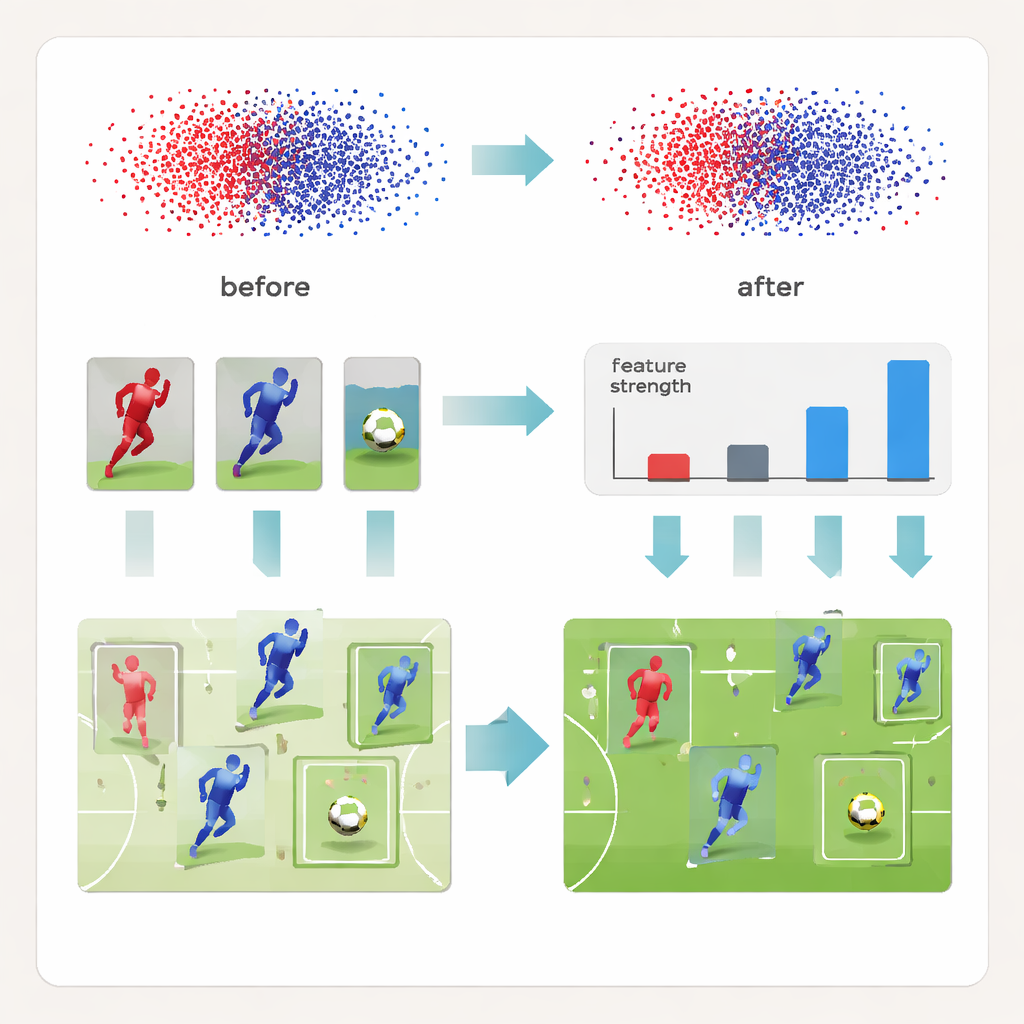
Vad det betyder för sportanalysens framtid
I vardagliga termer visar artikeln att många nuvarande AI‑system „ser“ fotboll på ett förenklat sätt: de slår ihop spelare i samma lag och nästan ignorerar bollen när spelet blir hektiskt. DeCon‑Net motverkar detta genom att tvinga nätverket att separat lära vem som hör till vilket lag och vem som är vilken individ, samtidigt som extra uppmärksamhet ges åt små, lättmissade objekt. Resultatet är en mer precis och pålitlig karta över varje spelare och bollen på planen, bildruta för bildruta. Den grunden kan driva bättre taktisk analys för tränare, rikare grafik för sändare och mer korrekta statistikuppgifter för fans, vilket för oss närmare en verkligt intelligent, automatiserad förståelse av spelet.
Citering: Ouyang, Q., Du, T. & Li, Q. DeCon-Net: decoupled hierarchical contrast for soccer object detection. Sci Rep 16, 7571 (2026). https://doi.org/10.1038/s41598-026-39084-4
Nyckelord: analys av fotbollsfilmer, objektigenkänning, sportanalys, datorseende, bollspårning