Clear Sky Science · sv
SwinCup-DiscNet: En fusion-transformer-ramverk för glaukomdiagnos med hjälp av papill- och koppfunktioner
Varför detta är viktigt för att rädda synen
Glaukom är en av världens ledande orsaker till irreversibel blindhet, men det utvecklas ofta tyst, utan smärta eller tidiga varningssignaler. Ögonläkare kan upptäcka subtila förändringar i ögats bakre del innan synen går förlorad, men att göra detta manuellt för varje patient är långsamt och kan vara inkonsekvent. Den här artikeln presenterar SwinCup-DiscNet, ett nytt artificiellt intelligenssystem (AI) som läser retinala fotografier för att tidigt upptäcka glaukom genom att kombinera klassiska kliniska ledtrådar med modern djupinlärning. 
Att titta på nerven inne i ögat
För att förstå vad systemet gör är det bra att känna till hur glaukom vanligen upptäcks. Ögonspecialister undersöker synnervshuvudet, platsen där nerven som för med sig syninformation lämnar ögat. I mitten av denna ”papill” finns en ljusare fördjupning som kallas ”kopp”. När glaukom utvecklas tenderar koppen att fördjupas och vidgas och äter sig in i den omgivande nervvävnadens rand. Ett viktigt mått är kopp-till-papill-förhållandet, som jämför koppens storlek med papillens storlek. Ett högre förhållande signalerar ofta skada. Att mäta detta förhållande för tusentals retinala fotografier för hand är tidsödande och även experter kan vara oense. SwinCup-DiscNet automatiserar både mätningen av detta förhållande och den övergripande bedömningen av om ett öga sannolikt har glaukom.
En tvåspårig AI som ser detaljerna och helheten
Systemet följer två parallella spår när det får en retinal fundusbild. Först isolerar en segmenteringsgren papill och den centrala koppen. Den använder ett specialiserat nätverk känt som Attention U-Net, som lär sig att framhäva viktiga strukturer och ignorera störande bakgrundsdetaljer som blodkärl och belysningsartefakter. När den har identifierat kopp- och papillgränserna jämnar systemet ut dem och passar rena ovala former, för att sedan mäta deras vertikala storlekar och beräkna det vertikala kopp-till-papill-förhållandet—en kliniskt betrodd markör för glaukom.
Att lära mönster bortom vad ögat kan mäta
I det andra spåret tittar en transformerbaserad gren på hela bilden utan att fokusera på något enskilt mått. Denna gren använder en Swin Transformer, en modern djupinlärningsmodell som delar bilden i små patchar och analyserar hur de relaterar till varandra över hela näthinnan. På så sätt plockar den upp subtila mönster i textur, färg och struktur runt synnerven och närliggande regioner som kan korrelera med glaukom men som är svåra för människor att kvantifiera. Från denna globala vy producerar modellen en sannolikhet för att bilden kommer från en person med glaukom. 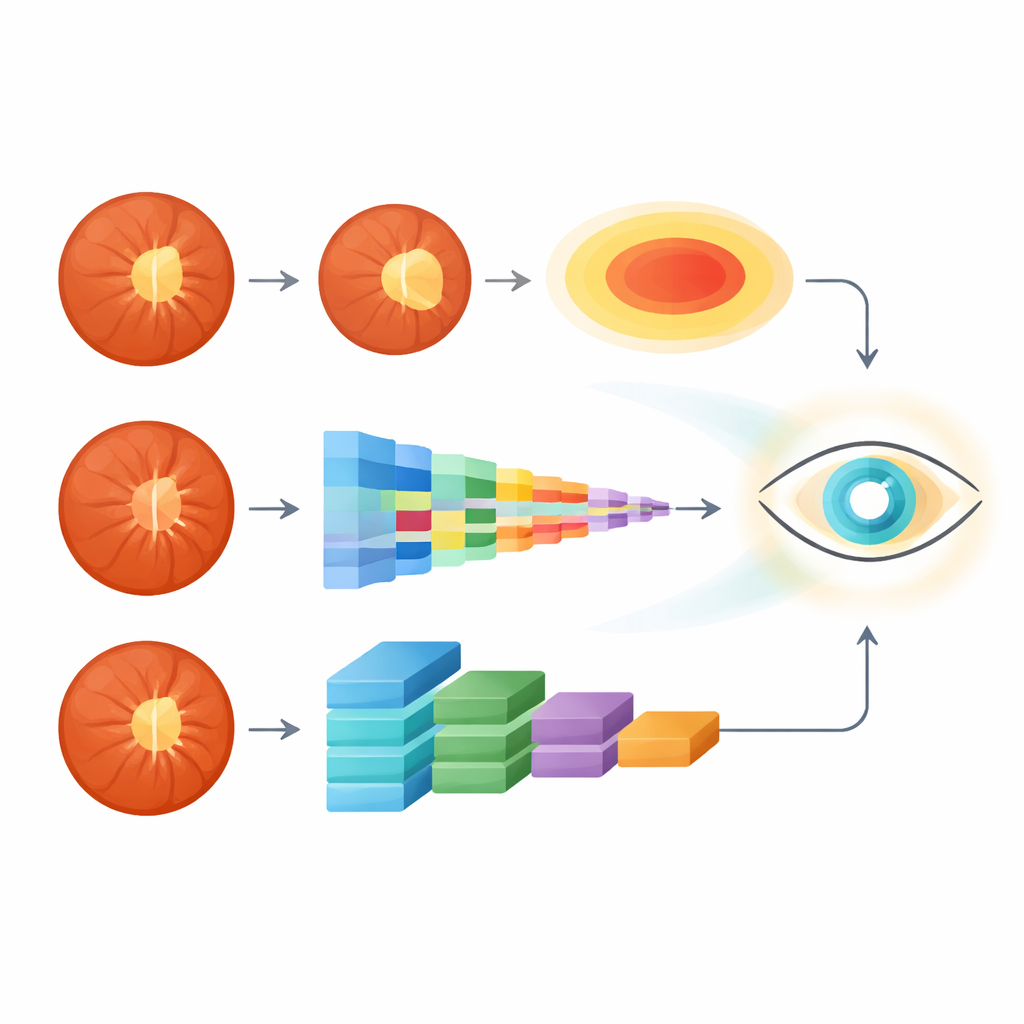
Att blanda betrodda ledtrådar med AI-intuition
Kärnan i SwinCup-DiscNet är hur det sammanför dessa två beviskällor. Istället för att enbart lita på kopp-till-papill-förhållandet eller endast transformerns sannolikhet blandas de med en viktad regel. Kopp-till-papill-förhållandet normaliseras utifrån hur det uppträdde i träningsdata och kombineras sedan med modellens inlärda glaukomsannolikhet till en enda poäng. Om den sammanslagna poängen passerar en tröskel klassificeras ögat som glaukomatiskt; annars etiketteras det som normalt. Denna utformning håller beslutet förankrat i ett välbekant kliniskt mått samtidigt som det drar nytta av de rikare mönster som AI kan upptäcka. Systemet överlagrar också de anpassade papill- och koppkonturerna på originalbilden, vilket ger läkare en tydlig visuell bild av vilken region som påverkade beslutet.
Att sätta metoden på prov
Författarna utvärderade SwinCup-DiscNet på tre allmänt använda publika dataset med retinala bilder: LAG, ACRIMA och DRISHTI-GS. Dessa samlingar varierar i kameratyp, bildkvalitet och patientmix, vilket gör dem till en tuff testbädd. Över samtliga matchade eller överträffade det nya systemet traditionella konvolutionsnätverk och metoder som enbart segmenterar kopp och papill. Det uppnådde mycket hög segmenteringskvalitet, låg felmarginal i uppskattningen av kopp-till-papill-förhållandet och klassificeringsnoggrannheter nära eller över 99 procent, med starka prestandakurvor som indikerar att det sällan förväxlar friska och sjuka ögon. En felanalys visade att de flesta återstående falska larm skedde i gränsfall där den optiska koppen naturligt var stor men inte verkligt sjuk—en kompromiss som ofta är acceptabel i screening.
Vad detta innebär för framtida ögonscreening
Enkelt uttryckt visar SwinCup-DiscNet att AI både kan ”tänka som en läkare” genom att använda etablerade markörer som kopp-till-papill-förhållandet och ”se bortom det uppenbara” genom att lära sig komplexa mönster i retinala bilder. Genom att kombinera dessa styrkor levererar systemet en noggrannare och mer tolkbar glaukomscreening än många befintliga metoder. Med vidare tester på verkliga sjukhusdata och möjliga utvidgningar för att grader a sjukdomens svårighetsgrad kan denna typ av hybrid-AI bli en praktisk assistent i ögonkliniker och bidra till att upptäcka glaukom tidigare och förebygga undvikbar blindhet.
Citering: Chilukuri, R., Praveen, P., Gatla, R.K. et al. SwinCup-DiscNet: A fusion transformer framework for glaucoma diagnosis using optic disc and cup features. Sci Rep 16, 7920 (2026). https://doi.org/10.1038/s41598-026-39065-7
Nyckelord: glaukom, retinalbildtagning, djupt lärande, optisk nerv, medicinsk screening