Clear Sky Science · sv
Stora språkmodeller visar Dunning–Kruger-liknande effekter i flerspråkig faktakontroll
Varför smart faktakontroll är viktigt för alla
Desinformation sprider sig nu snabbare än någonsin och formar vad människor tror om hälsa, politik, vetenskap och vardagsliv. Många plattformar och nyhetsredaktioner börjar förlita sig på artificiell intelligens—särskilt stora språkmodeller, eller LLM:er—för att hjälpa till att kontrollera om virala påståenden är sanna eller falska. Denna studie ställer en bedrägligt enkel men avgörande fråga: när vi låter dessa system bedöma fakta, hur ofta har de rätt, hur säkra uppträder de, och förändras det över olika språk och regioner i världen?
Hur forskarna testade AI mot verkliga rykten
I stället för att hitta på artificiella exempel byggde författarna sina tester på 5 000 genuina påståenden som professionella faktagranskningsorganisationer runt om i världen redan hade undersökt. Dessa påståenden täckte 47 språk och kom från både den globala norden och globala syd, vilket speglar den röriga, flerkulturella verkligheten av online-rykten. Endast uttalanden med tydliga ”sanna” eller ”falska” utfall—överenskomna av flera faktagranskare—inkluderades, vilket skapade en robust grundsanning för jämförelsen.
De körde sedan nio allmänt använda språkmodeller, från mindre öppna system till avancerade kommersiella, på varje påstående. För att efterlikna hur människor faktiskt talar med chattbotar var de flesta uppmaningarna enkla frågor som ”Är detta sant?” eller ”Är detta falskt?”, skrivna på samma språk som påståendet. En fjärde, mer professionell konfiguration använde en detaljerad instruktion på engelska som förvandlade modellen till en virtuell faktagranskare och bad om strukturerade svar. Mänskliga annotatörer läste noggrant modellernas svar och märkte dem som att de angav att påståendet var sant, falskt eller vägrade att ge ett klart uttalande.
Mäta inte bara rätt eller fel, utan också när man bör säga ”jag vet inte”
Teamet gjorde mer än att räkna träffar och missar. De använde tre nyckelmått för att fånga modellernas beteende. För det första tittade ”selektiv noggrannhet” på hur ofta en modell hade rätt när den faktiskt tog ställning och förklarade ett påstående sant eller falskt. För det andra behandlade ”avhållsamhetsvänlig noggrannhet” det som acceptabelt, till och med önskvärt, att modellen erkände osäkerhet i stället för att gissa—vilket är viktigt inom känsliga områden som medicin eller val. För det tredje följde ”säkerhetsgrad” hur ofta en modell gav ett definitivt svar alls, vilket tjänar som en grov indikator på hur självsäker den uppträdde.
Den professionella prompten, med sin steg-för-steg-vägledning, höjde konsekvent noggrannheten över alla modeller. Men den exponerade också en avvägning: mindre modeller blev ofta mer bestämda utan att bli mer pålitliga, medan större modeller använde strukturen för att ge färre men bättre svar. Vardagliga, chattliknande uppmaningar gav mer försiktigt beteende, särskilt hos svagare modeller, men sänkte också något deras noggrannhet.
När mindre kapabla system uppträder mer självsäkert
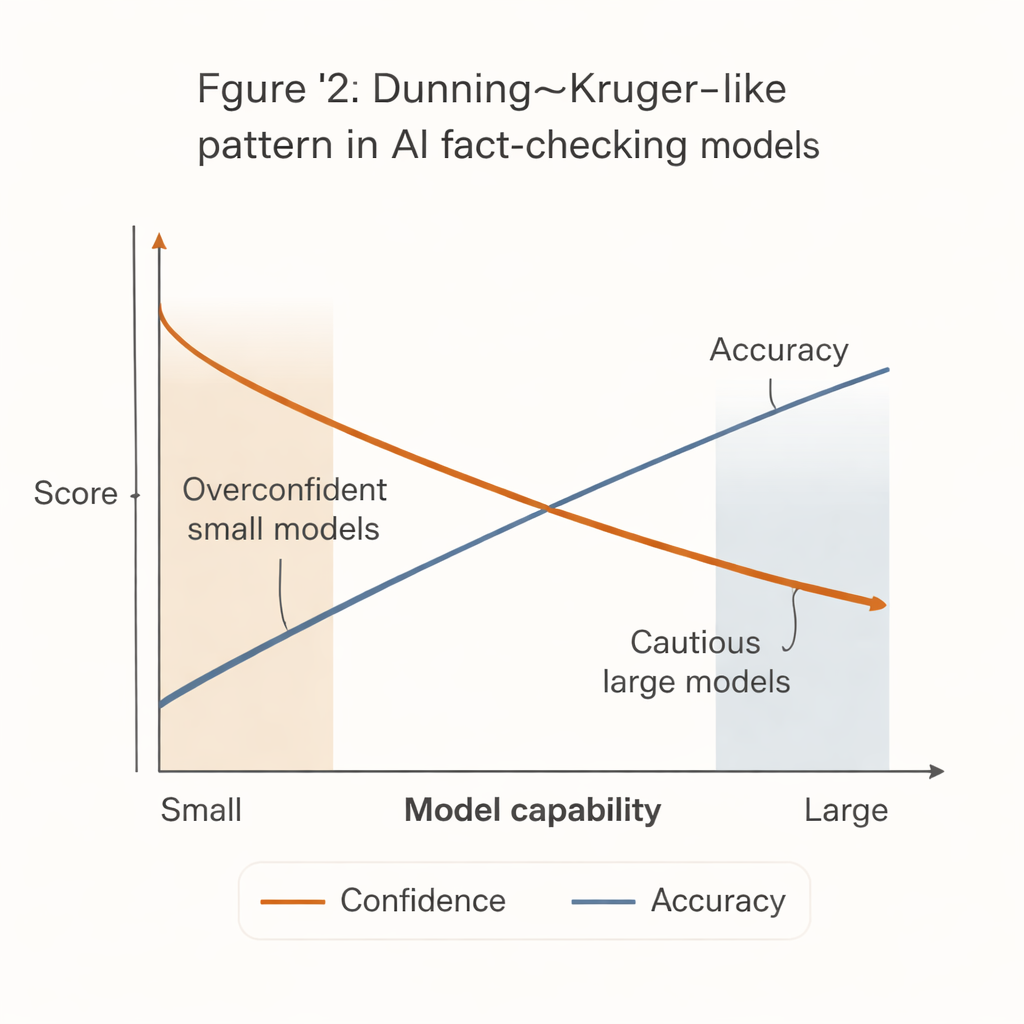
Ett slående mönster framträdde som speglar det välkända Dunning–Kruger-fenomenet inom människopsykologin: de minst kapabla systemen uppträdde mest självsäkert. Små, billiga modeller tenderade att utfärda bestämda utslag i en stor majoritet av påståendena, men med märkbart lägre noggrannhet. I kontrast var de starkaste modellerna—såsom avancerade GPT-versioner—mycket mer korrekta när de väl tog ställning, men betydligt mer benägna att avstå, särskilt i svåra eller tvetydiga fall.
Detta ”självförtroende–kompetens-gap” har verkliga följder. Många resursknappa redaktioner, civilsamhällesgrupper och lokala faktagranskare har inte råd med de mest kraftfulla AI-systemen. De är mer benägna att adoptera mindre, billigare modeller som framstår som beslutsamma men oftare har fel. Om dessa verktyg kopplas in i arbetsflöden eller system för community-moderering utan noggranna skyddsåtgärder kan de faktiskt förstärka desinformation genom att producera självsäkra men felaktiga faktakontroller.
Ojämn prestanda över språk och regioner
Studien visar också att dessa system inte fungerar lika bra för alla. Över flera stora språk presterade modellerna generellt bäst på engelska påståenden och något sämre på portugisiska och hindi. Större modeller tenderade att svara mer försiktigt på icke-engelska språk, men överträffade ändå de mindre i noggrannhet. När författarna jämförde påståenden kopplade till globala norden och globala syd snubblade de flesta modeller mer på det sistnämnda. Mindre system förblev ofta självsäkra samtidigt som deras noggrannhet föll, medan stora modeller visade större minskningar i säkerhet men mindre minskningar i korrekthet, vilket tyder på att de uppfattade sin egen osäkerhet och höll tillbaka.
Vad detta betyder för framtidens pålitliga AI-verktyg
För en icke-specialist är kärnbudskapet tydligt: dagens AI-faktagranskare är långt ifrån jämlika, och de mest tillgängliga kan vara mest vilseledande. Kraftfulla modeller kan vara försiktiga och korrekta, men de är kostsamma och ibland överdrivet tveksamma. Svagare modeller är djärva men mer benägna att ha fel, särskilt utanför engelska och i berättelser från globala syd. Författarna argumenterar för att AI bör stödja, inte ersätta, mänskliga faktagranskare, och att policy- och designval måste driva mot bättre kalibrering—lära systemen när de ska tiga—och rättvisare tillgång till högkvalitativa verktyg. Annars kan samma teknik som byggs för att bekämpa desinformation fördjupa de informationsojämlikheter den avser att lösa.
Citering: Qazi, I.A., Khan, Z., Ghani, A. et al. Large language models show Dunning-Kruger-like effects in multilingual fact-checking. Sci Rep 16, 7594 (2026). https://doi.org/10.1038/s41598-026-39046-w
Nyckelord: desinformation, faktagranskning, stora språkmodeller, AI-förtroende, flerspråkig partiskhet