Clear Sky Science · sv
En hybrid LSTM‑GRU‑ramverk för lungcancerklassificering med GWO‑WOA‑algoritm för hyperparameterinställning och BPSO för funktionsurval
Varför detta spelar roll för vardaglig hälsa
Att hitta lungcancer tidigt kan rädda liv, men många får aldrig avancerade skanningar förrän det är för sent. Denna studie undersöker om enkla frågebaserade hälsokontroller — om ålder, rökning, symtom och vardagsvanor — kan kombineras med modern artificiell intelligens för att upptäcka personer med hög risk långt innan svår sjukdom uppträder. Genom att utnyttja kostnadseffektiva enkäter och intelligenta datormodeller visar arbetet vägen mot snabbare, mer tillgängliga screeningverktyg som en dag skulle kunna stödja läkare och folkhälsoinitiativ globalt.
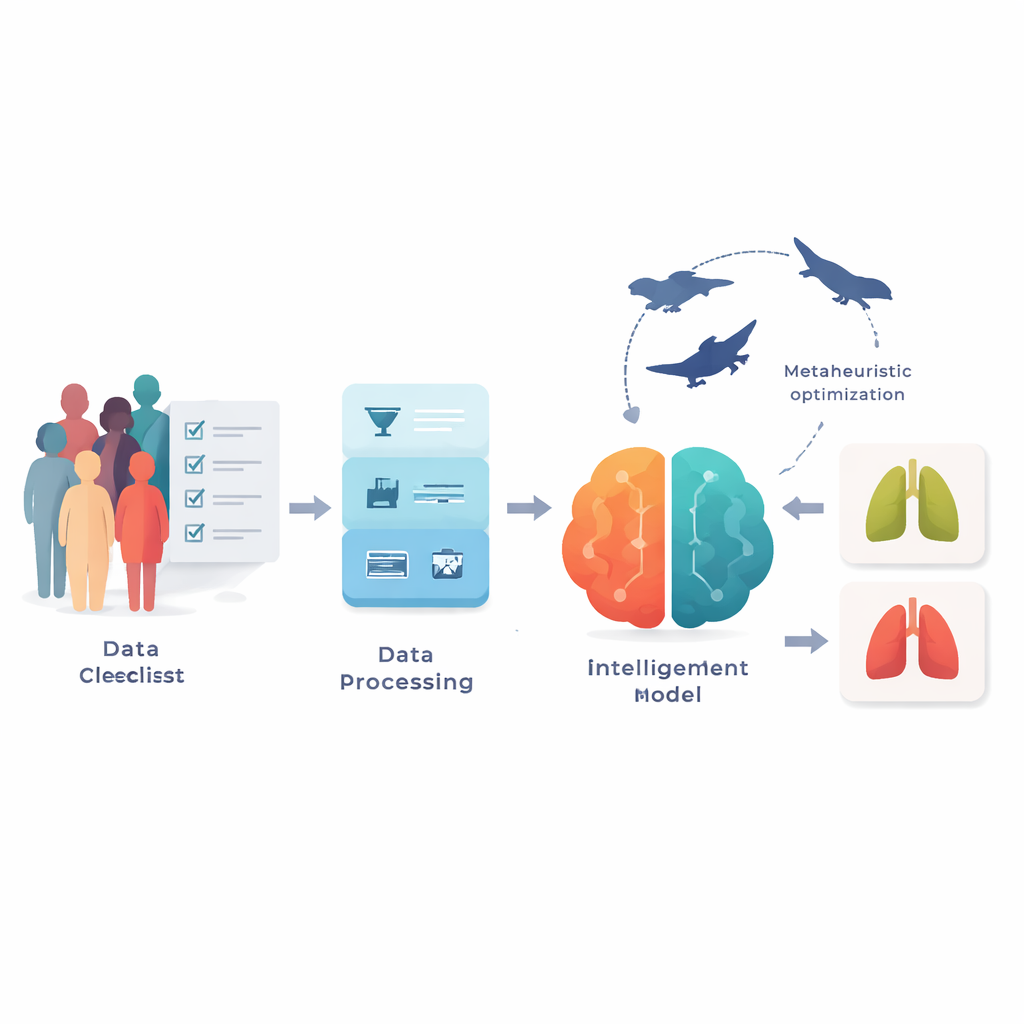
Att omvandla enkla frågor till användbara signaler
Forskarna arbetade med två offentliga dataset från webbplatsen Kaggle, som tillsammans täcker mer än 3 300 personer. Istället för medicinska bilder innehåller varje post 15 punkter som du kan se på en klinisk blankett: ålder, kön, rökstatus, gula fingrar, hosta, andfåddhet, bröstsmärta och liknande riskfaktorer och symtom, plus en etikett som anger om lungcancer fanns närvarande. Eftersom enkätdata i verkliga världen är röriga rengjorde teamet först informationen genom att åtgärda saknade värden, ta bort dubbletter och synkronisera hur svar kodades mellan de två datasetet. De justerade också värdena så att alla variabler låg på liknande skala och använde en balanseringsmetod för att rätta till en stark snedvridning mot cancerfall i det mindre datasetet, vilket hjälpte modellen att undvika att prediktera enbart majoritetsklassen.
Låta datorn välja de mest talande frågorna
Inte varje fråga på ett formulär är lika hjälpsam för att upptäcka sjukdom, och att använda för många kan faktiskt förvirra en modell. För att fokusera på vad som spelar störst roll använde författarna en svärm‑inspirerad sökstrategi som kallas Binary Particle Swarm Optimization. Enkelt uttryckt testas många kandidatuppsättningar av ”frågor” parallellt, och de rör sig genom möjligheternas rum genom att kopiera och förbättra de bäst presterande. Med tiden landade processen på kompakta uppsättningar om cirka sju nyckelfrågor och lyfte upp återkommande egenskaper som rökning, gula fingrar, hosta, bröstsmärta, pipande andning, andfåddhet och kronisk sjukdom. Dessa fokuserade uppsättningar förbättrade noggrannheten med flera procentenheter jämfört med att använda alla 15 frågor, samtidigt som de gjorde den slutliga modellen lättare att tolka och snabbare att köra.

En smartare motor för att läsa mönster i svaren
För att omvandla enkätsvar till ett ja‑eller‑nej‑cancerbeslut byggde teamet en hybridmodell som blandar två närbesläktade djupinlärningsenheter som ofta används för sekvenser: Long Short‑Term Memory (LSTM) och Gated Recurrent Unit (GRU). Även om enkätsvar inte är tidsserier som tal eller video, bildar grupper av symtom och vanor fortfarande mönster som kan behandlas som korta sekvenser. Modellen matar först de utvalda frågorna genom LSTM‑lager som kan lagra och glömma information selektivt, och därefter genom GRU‑lager som förfinar dessa mönster med färre interna steg och lägre beräkningskostnad. För att undvika trial‑and‑error‑design ställde författarna in avgörande parametrar — såsom inlärningshastighet, antal dolda enheter, batchstorlek och dropout — med ett andra lager av naturinspirerad sökning som blandar den breda utforskningen från ”gråvargar” med de finjusterande rörelserna från ”valar”. Denna gemensamma optimerare söker efter hyperparameterkombinationer som konsekvent ger hög träffsäkerhet vid korsvalidering.
Hur väl systemet presterade
Efter träning testades den hybrida LSTM–GRU‑modellen mot flera starka baslinjer, inklusive fristående LSTM‑ och GRU‑nätverk, ett konvolutionellt neuralt nätverk, traditionella support vector machines och träd‑baserade metoder som random forests och gradient boosting. På det mindre datasetet med 309 personer klassificerade det föreslagna systemet korrekt varje enda fall i det hållna testdelmängden och nådde 100 % i noggrannhet, precision, recall och F1‑poäng. På det större datasetet med 3 000 personer förblev det nära perfekt, med ungefär 99,3 % noggrannhet och liknande höga värden för övriga mått, och överträffade alla konkurrerande djupinlärnings‑ och klassiska modeller. Författarna visade också att deras tvåstegsstrategi — först välja frågor med svärmsökning och sedan finjustera den hybrida nätverksarkitekturen med varg‑och‑val‑optimeraren — gav mer stabila resultat över upprepade korsvalideringskörningar än enklare upplägg.
Vad detta innebär för framtida lungscreening
I vardagliga termer visar detta arbete att ett noggrant utformat AI‑system kan läsa vanliga enkätsvar och mycket precist skilja personer med och utan lungcancer i riktmärkesdataset. Det ersätter inte skanningar, läkare eller kliniska prövningar, och författarna betonar att deras data är begränsade och ännu inte redo för direkt användning på sjukhus. Ändå visar tillvägagångssättet att kombinationen av smart frågeval och fint inställda djupinlärningsmotorer kan förvandla lågkostnadsformulär till kraftfulla tidiga varningsverktyg. Med vidare testning på större, kliniskt kurerade populationer och bättre förklaringsmetoder för att visa varför modellen flaggar en person som hög risk, skulle liknande system en dag kunna hjälpa till att avgöra vilka som bör remitteras för mer detaljerad bilddiagnostik, och därigenom stödja tidigare diagnos samtidigt som screeningen hålls prisvärd och icke‑invasiv.
Citering: Amrir, M.M.S., Ayid, Y.M., Elshewey, A.M. et al. A hybrid LSTM-GRU framework for lung cancer classification using GWO-WOA algorithm for hyperparameter tuning and BPSO for feature selection. Sci Rep 16, 8600 (2026). https://doi.org/10.1038/s41598-026-39020-6
Nyckelord: lungcancerscreening, enkätdata, djupinlärning, funktionsurval, medicinsk AI