Clear Sky Science · sv
En humanoid styrstrategi baserad på djup förstärkningsinlärning för förbättrad komfort i rehabiliteringsrobotar för underkroppen
Robotar som hjälper människor att gå igen
När någon har svårt att gå efter en stroke eller ryggmärgsskada kan terapin vara långsam, utmattande och obekväm. Rehabiliteringsrobotar för underkroppen är utformade för att stödja och vägleda patientens ben under träning, men dagens maskiner känns ofta stela och "robotiska." Denna studie undersöker hur det att ge dessa robotar en mer människoliknande "hjärna" — med hjälp av avancerade inlärningsalgoritmer — kan göra träningen mjukare, mer naturlig och i förlängningen mer effektiv för patienterna.
Varför gångträning behöver kännas naturlig
I takt med att befolkningar åldras lever fler med allvarliga gångproblem, och många vänder sig till robotassisterad rehabilitering. Traditionella robotar följer förprogrammerade benbanor och använder enkla styrregler för att röra lederna. Även om dessa metoder är tillförlitliga har de svårt att hantera den röriga verkligheten i mänsklig rörelse: allas gångmönster skiljer sig åt, och en styv robot kan dra eller trycka på sätt som känns klumpiga eller till och med smärtsamma. Författarna menar att för att rehabilitering ska fungera väl måste roboten inte bara hålla patienten upprätt och i rörelse, utan också anpassa sig till naturliga gångmönster och minimera de krafter den utövar på kroppen.
Lärande från verkliga steg
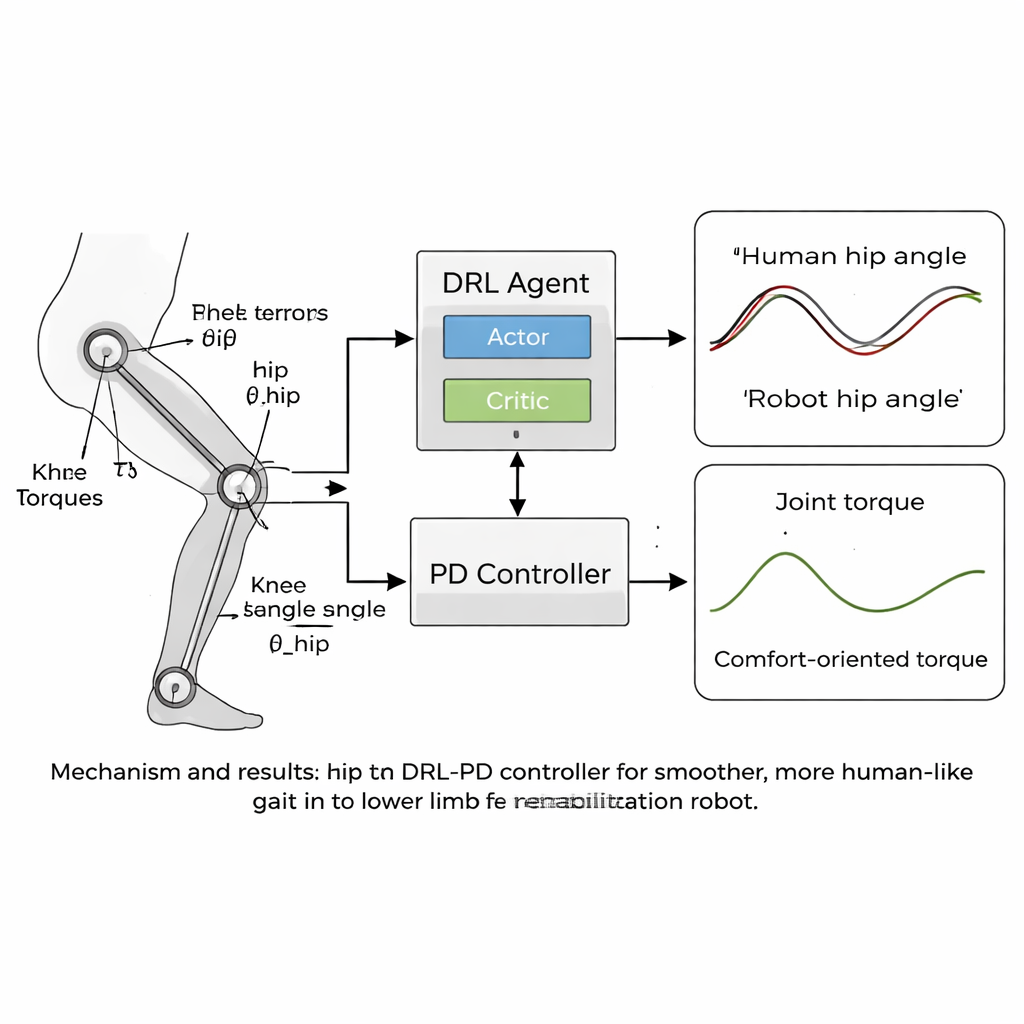
För att lära roboten hur människor faktiskt går byggde forskarna först en förenklad matematisk modell av ben och bål. De spelade sedan in gångdata från fem friska frivilliga med ett högprecisions 3D-rörelseinspelningssystem och kraftplattor i golvet. Reflektiva markörer på höfter, knän, vrister och bål gjorde det möjligt att beräkna hur varje led rörde sig under ett helt steg, medan sensorer under fötterna mätte hur hårt varje ben tryckte mot marken. Från dessa mätningar skapade de släta referenskurvor för höft- och knävinklar och följde hur ledkrav förändrades över tid, vilket fångade både formen och rytmen i normal gång.
En smartare regulator som ändå håller säkerheten
Hjärtat i artikeln är en ny "humanoid" styrstrategi som kombinerar djup förstärkningsinlärning (DRL) med en klassisk proportionell-derivativ (PD) regulator. DRL är en typ av artificiell intelligens där en virtuell agent provar handlingar, observerar resultaten och gradvis upptäcker vad som fungerar bäst genom att maximera en belöningssignal. I detta fall sitter agenten ovanpå PD-regulatorn: den ser robotens ledvinklar och hastigheter och bestämmer vilka vridmoment som ska appliceras, medan PD-lagret ser till att lederna inte driver för långt från säkra, människoliknande målvinklar. Belöningsfunktionen är noggrant utformad för att uppmuntra stabil framåtrörelse samtidigt som den straffar allt som skulle kännas obehagligt för en patient — såsom ryckig rörelse, stora krafter i lederna eller osäkra kroppsställningar som överdriven lutning eller låg fotfrigång.
Mjukare rörelse, närmare mänsklig gång
Teamet testade sin metod i datorbaserade simuleringar med en modell av en rehabiliteringsrobot för underkroppen med höft- och knäleder som matchade deras gångdata. Under tusentals träningsavsnitt lärde sig DRL–PD-regulatorn att producera en upprepad gångcykel där ledvinklar följde de mänskliga referensmönstren nära. Robotens höfter och knän rörde sig i regelbundna, stabila slingor, ett tecken på tillförlitlig, repetitiv gång. Avgörande var att de vridmoment som behövdes för att driva lederna blev mjukare och mindre jämfört med en standard PD-regulator. Kvantitativa mått visade att följningsfelen sjönk till bara några hundradels radian, och den takt med vilken ledvridmomenten förändrades — en proxy för hur "ryckigt" krafterna skulle kännas för en patient — minskade med mer än hälften. Regulatorn förblev också stabil även när modellens benmassor varierades med flera procent, vilket antyder att den kan tolerera verkliga skillnader mellan användare.
Vad det innebär för framtidens rehabiliteringsrobotar
För icke-specialister är huvudbudskapet enkelt: genom att låta en robot lära sig rytmerna och gränserna för mänsklig gång från verkliga data, och genom att belöna den för att vara mjuk och skonsam, kan vi utforma maskiner som hjälper människor att öva gång på ett sätt som känns mer naturligt och mindre stressande. Patienter kan vara mer villiga att delta i längre och mer frekventa sessioner om roboten rör sig med dem istället för mot dem. Även om de nuvarande resultaten kommer från simuleringar och kräver kraftfulla datorer för träning, kan regulatorn när inlärningen är klar köras effektivt på riktiga enheter. Författarna ser detta arbete som ett steg mot personliga, adaptiva rehabiliteringsrobotar som anpassar sig till varje patients unika gångmönster och komfortbehov, vilket potentiellt förbättrar både återhämtning och livskvalitet.
Citering: Jin, Y., Zhang, J., Li, W. et al. A humanoid control strategy based on deep reinforcement learning for enhanced comfort in lower limb rehabilitation robots. Sci Rep 16, 7370 (2026). https://doi.org/10.1038/s41598-026-39011-7
Nyckelord: rehabiliteringsrobotar, gångträning, djup förstärkningsinlärning, exoskelett, patientkomfort