Clear Sky Science · sv
Jämförande bedömning av maskininlärningsmodeller för daglig flödesprognos i ett subtropiskt monsunavrinningsområde
Varför flodprognoser spelar roll i vardagen
Floder i monsunområden kan stiga från lugna till katastrofala på bara några timmar och hota liv, hem och vattenförsörjning. Att med precision förutsäga hur mycket vatten som rinner i en flod varje dag ligger till grund för översvämningsvarningar, dammförvaltning och vattenkranar som försörjer städer. Denna studie fokuserar på ett subtropiskt flodsystem i södra Kina och ställer en praktisk fråga med global relevans: bland dagens populära maskininlärningsverktyg, vilka klarar verkligen bäst att förutsäga dagliga flöden, särskilt under farliga översvämningar?
En stormbenägen flod under press
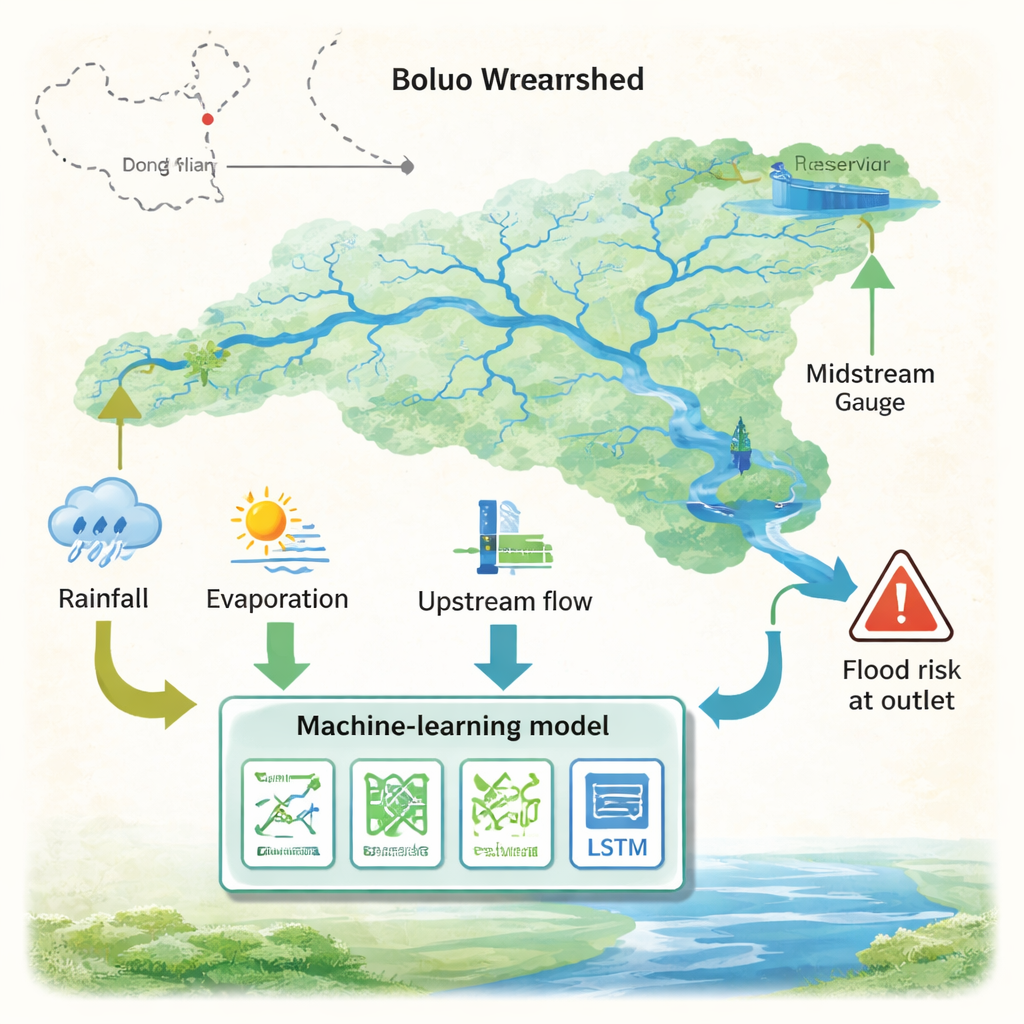
Forskningen koncentreras på Boluo‑avrinningsområdet, en del av Dongjiangfloden som bidrar till vattenförsörjningen i Guangdong–Hong Kong–Macao Greater Bay Area. Regionen har ett klassiskt monsunklimat: största delen av nederbörden faller under några intensiva månader, ofta levererad av fronter och tyfoner. Utöver denna naturliga volatilitet omformar en större reservoar och annan mänsklig verksamhet tidpunkten och storleken på flödena. Författarna samlade flera decennier av dagliga data från regnmätare, väderstationer och flödesmätare vid nyckelplatser och delade upp posterna i träningsår och testår för att efterlikna verkliga prognosscenarier. Detta gjorde det möjligt att se hur olika algoritmer hanterar ett flodsystem som både är starkt säsongsbetonat och kraftigt reglerat.
Sju digitala prognosmakares ansikte mot ansikte
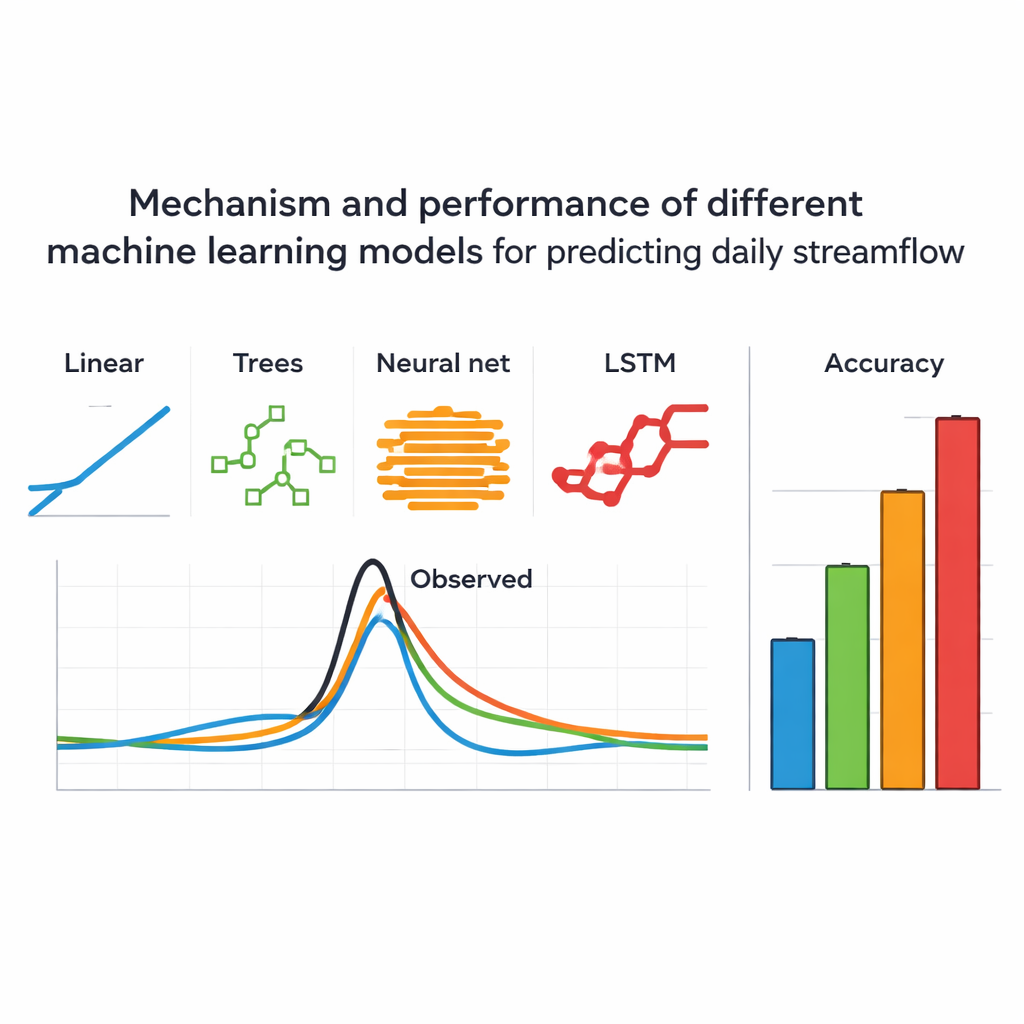
Teamet jämförde sju välanvända maskininlärningsmodeller: en enkel linjär regression, tre typer av träd‑baserade ensemblemetoder (Random Forest, Extra Trees och Gradient Boosting, inklusive XGBoost), ett klassiskt artificiellt neuronnät och ett mer avancerat Long Short‑Term Memory (LSTM)‑nätverk utformat för sekvenser över tid. Varje modell finjusterades noggrant med samma procedurer och utvärderades med flera noggrannhetsmått. Över hela spannet av förhållanden gav alla sju rimligt bra prognoser, vilket bekräftar att datadrivna tillvägagångssätt är kraftfulla verktyg för flödesprognoser. Tydliga skillnader framträdde dock. LSTM‑modellen hamnade i topp, tätt följd av det konventionella neuronnätet, medan den rena linjära modellen presterade överraskande bra och slog alla de träd‑baserade metoderna.
Hur modeller beter sig när floden dånar
Översvämningar är där prognoser verkligen räknas, så författarna zoomade in på dagar med höga flöden och tre av de största översvämningshändelserna i serien. Under dessa extrema förhållanden skärptes kontrasterna. LSTM höll sin position och var mest träffsäker när flödena översteg 90:e, 95:e och till och med 99:e percentilen — dagar då floden är som farligast. Den underskattade fortfarande vissa toppar, men oftast med mindre än 20 procent. Det standardmässiga neuronnätet klarade sig hyfsat, medan träd‑baserade modeller ofta missade toppstorlekar med 30 till 50 procent och presterade sämre än att helt enkelt använda långtidsmedelvärdet på de allra högsta flödesdagarna. Ändå träffade de flesta modellerna dagpunkten för toppen inom ungefär en dag, vilket är avgörande för att utfärda varningar även om exakt nivå kan vara felaktig.
Vad som egentligen driver flodens upp‑ och nedgångar
För att gå bortom ”svarta lådan”‑prognoser undersökte studien vilka indata som betydde mest för modellerna. Flera tekniker, inklusive en spelteoriinspirerad metod kallad SHAP, pekade på samma svar: flödet mätt vid en upstream‑mätstation kallad Lingxia dominerade prognoserna. Med andra ord var gårdagens vattenstånd uppströms vanligtvis mer informativt än dagens nederbördssummor. Detta speglar ett slags hydrologiskt minne, där floden integrerar effekterna av senaste stormar, markfukt och grundvatten i sitt aktuella flöde. När forskarna tog bort uppströmsflödesdata sjönk LSTM‑modellens skicklighet kraftigt; när de tog bort nederbördsdata förändrades prestandan knappt. Det tyder på att för daglig prognostisering i detta avrinningsområde kan det vara viktigare att följa hur mycket vatten som redan finns i systemet än att installera fler regnmätare.
Vad resultaten betyder för översvämningssäkerhet
För icke‑specialister är slutsatsen enkel: smarta modeller som minns gårdagens förhållanden, som LSTM, kan ge mer tillförlitliga flödesprognoser än många populära alternativ, särskilt när översvämningar hotar. Samtidigt kan en väl utformad enkel modell fortfarande vara förvånansvärt effektiv, särskilt när bra uppströmsflödesmätningar finns tillgängliga. Arbetet understryker att förbättrad översvämningsprognos inte bara handlar om att använda mer avancerade algoritmer eller mer nederbördsdata; det handlar om att fånga flodens inneboende minne och kombinera datadrivna verktyg med fysisk förståelse. Sådana framsteg kan hjälpa vattenförvaltare i monsunpåverkade regioner att fatta tidigare och mer självsäkra beslut när nästa stora storm närmar sig.
Citering: Zhang, Z., Xiao, Y., Chen, R. et al. Comparative assessment of machine learning models for daily streamflow prediction in a subtropical monsoon watershed. Sci Rep 16, 7341 (2026). https://doi.org/10.1038/s41598-026-38969-8
Nyckelord: flödesprognos, översvämningsprognoser, maskininlärning, LSTM‑neuronnätverk, monsunfloder