Clear Sky Science · sv
En tvåströms djupinlärningsram för kontinuerlig igenkänning av teckenspråk för att förbättra kommunikativ tillgänglighet i Ha’il-regionen
Att överbrygga kommunikationsklyftan
För många döva är teckenspråk det huvudsakliga sättet att kommunicera, men de flesta datorer, telefoner och offentliga tjänster kan fortfarande inte förstå det. Den här artikeln presenterar ett nytt artificiellt intelligenssystem som kan tolka kontinuerlig teckning i video och omvandla den till skrift mer exakt. Genom att uppmärksamma inte bara handrörelser utan också huvudets position och ansiktsmarkörer syftar systemet till att göra teknikbaserad kommunikation mer naturlig och tillgänglig—särskilt för döva samhällen i Ha’il-regionen i Saudiarabien, där digitalt stöd fortfarande är begränsat. 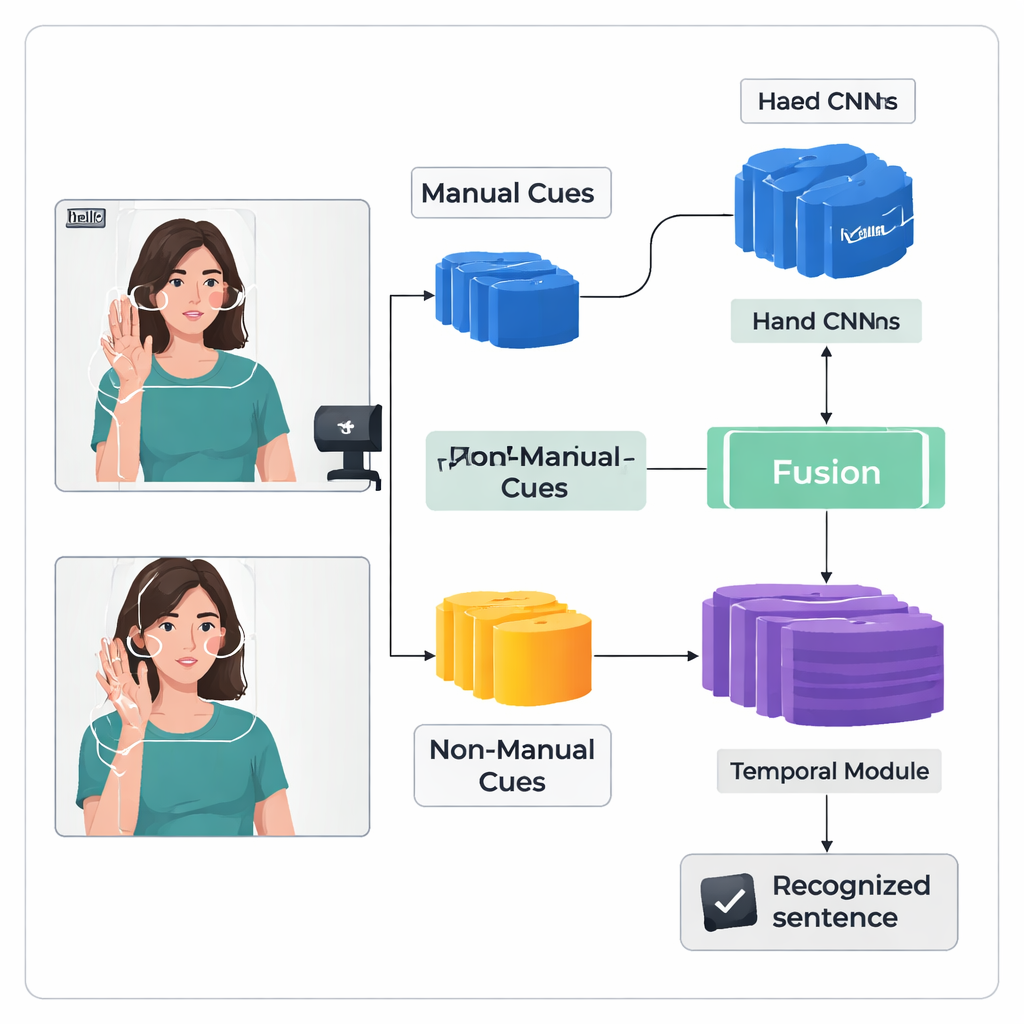
Varför händerna inte räcker
Teckenspråk är rika, komplexa system som använder hela överkroppen. Betydelse uppstår inte bara från hur händerna rör sig, utan också från ansiktsuttryck, vart tecknaren tittar och hur huvudet lutar eller nickar. Dessa icke-handliga signaler kan markera frågor, negation, betoning eller känslor. Människor uppfattar allt detta utan ansträngning, men de flesta datorsystem för teckenspråksigenkänning fokuserar nästan uteslutande på händerna. Den genvägen gör träningen enklare men gör att viktiga ledtrådar går förlorade, särskilt när tecken flyter samman i snabba, kontinuerliga meningar snarare än isolerade ord.
Två strömmar som arbetar parallellt
Författarna introducerar en "tvåströms" djupinlärningsram kallad TS-CNN som behandlar händer och huvud separat och sedan förenar dem. En ström fokuserar på beskurna bilder av tecknarens händer och lär sig mönster i form, rörelse och position. Den andra strömmen får en kompakt karta över ansikte och huvud, härledd från landmärkespunkter och huvudposeuppskattningar. Båda strömmarna använder en standardtyp av visionsnätverk för att omvandla varje videoruta till numeriska funktioner. Systemet fusionerar dessa funktioner ruta för ruta och beaktar att hand- och huvudsignaler sker samtidigt i verklig teckning. En senare temporal modul ser över många rutor för att förstå hur tecken utvecklas över tid, och ett rekurrent lager producerar en sekvens av förutsagda teckenenheter, eller glossor.
Förbättra systemets minne av tecken
Att känna igen kontinuerlig teckning är svårt eftersom träningsdata är begränsade och tecken flyter ihop utan tydliga ruta-för-ruta-etiketter. För att tackla detta lägger författarna till en Feature Enhancement Module som ger nätverket extra vägledning under träning. En allmänt använd teknik anpassar den förutspådda glosssekvensen med videon och producerar sannolika positioner för varje gloss i tiden. Den nya modulen tar dessa justeringsförslag och använder dem som direkt tillsyn för att förfina den interna representationen av glossfunktioner. Enkelt uttryckt lär sig systemet inte bara att outputta rätt sekvens, utan också att bygga tydligare, mer konsekventa interna "minnen" av hur varje tecken ser ut över olika videor.
Sätta metoden på prov
Teamet utvärderar TS-CNN på två välkända teckenspråksdataset: RWTH-PHOENIX-Weather 2014 för tyska teckenspråket och CSL Split II för kinesiskt teckenspråk. De mäter prestanda med word error rate, en standardmetrik liknande den som används i taligenkänning. Jämfört med en baslinje som endast ser på handrörelser minskar tillägget av huvudposeinformation felen med omkring 4 procentenheter på de tyska data och 3–4 enheter på de kinesiska. Att lägga till feature enhancement-modulen ger ännu större förbättringar och minskar felen med ungefär 10–14 procent totalt på båda dataset. Systemet körs också effektivt och når realtidsprestanda på en modern grafisk processor, vilket är avgörande om det ska användas i liveinterpretation eller mobilverktyg. 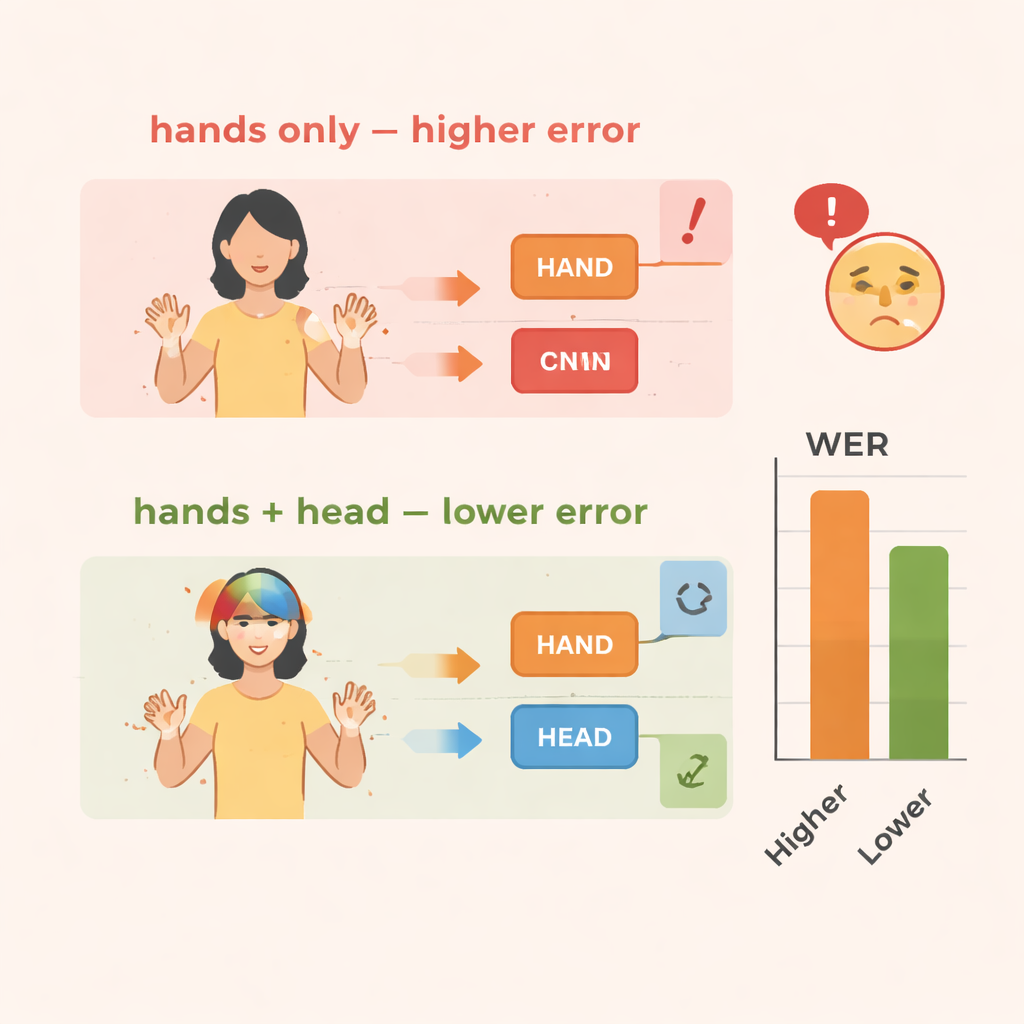
Vad detta betyder i vardagen
I vardagstermer visar denna forskning att datorer kan förstå teckenspråk mer pålitligt när de ser hela tecknaren, inte bara händerna. Genom att modellera huvudrörelser och ansiktsmarkörer tillsammans med handrörelser, och genom att omsorgsfullt förfina hur det lär sig från begränsade träningsdata, tar TS-CNN-ramverket ett steg närmare praktiska system som kan stödja döva i klassrum, sjukhus och offentliga kontor. För regioner som Ha’il, där mänskliga tolkar är få och tekniska projekt fortfarande är under utveckling, skulle ett sådant system så småningom kunna stödja mer inkluderande kommunikation—hjälpa till att överbrygga klyftan mellan tecknare och den hörande världen utan att ersätta den rika, mänskliga upplevelsen av att teckna i sig.
Citering: Harrouch, H., Guesmi, H., Alalfy, H. et al. A dual-stream deep learning framework for continuous sign language recognition to enhance communication accessibility in the Ha’il region. Sci Rep 16, 7070 (2026). https://doi.org/10.1038/s41598-026-38912-x
Nyckelord: igenkänning av teckenspråk, djupinlärning, tillgänglighet, datorseende, människa–dator-interaktion