Clear Sky Science · sv
Uppskattning av arters vanlighet och utbredning genom icke-övervakade metoder
Varför det spelar roll att räkna vanliga och sällsynta arter
När vi föreställer oss naturen i fara tänker vi ofta på sällsynta djur på randen till utrotning. Men större delen av den levande väven omkring oss består av mycket ordinära varelser som antingen är vanliga eller tyst försvinner innan någon märker det. Att kunna avgöra hur utbredd en art verkligen är på en plats är avgörande för att förutsäga hur ekosystem kommer att reagera på föroreningar, markanvändning eller klimatförändringar. Denna artikel presenterar ett sätt att samtidigt uppskatta hur vanliga eller sällsynta många arter är, med enbart befintliga observationsregister och moderna dataanalystekniker. Målet är att ge mer objektiva ingångsvärden till datorbaserade modeller som förutser var arter kan leva nu och i framtiden.
Från enkla observationer till stora ekologiska frågor
Ekologer använder rutinmässigt datorbaserade modeller, så kallade ekologiska nischmodeller, för att avgöra vilka miljöer som är lämpliga för en art. Dessa modeller hjälper till att förutsäga var en art kan dyka upp under klimatförändringar eller i nya regioner. En avgörande ingrediens är “prevalens” – ungefär andelen undersökta platser där en art finns. Det kodar för om en art förväntas vara vanlig eller sällsynt innan nya fältstudier görs. Denna förväntning påverkar starkt hur modeller omvandlar råa lämplighetspoäng till sannolikheter för förekomst och hur de drar gränsen mellan “förekommande” och “frånvarande” på en karta. Om prevalensen skattas fel, särskilt för sällsynta arter, kan prognoser bli missvisande och bevarandeinsatser rikta in sig på fel platser.
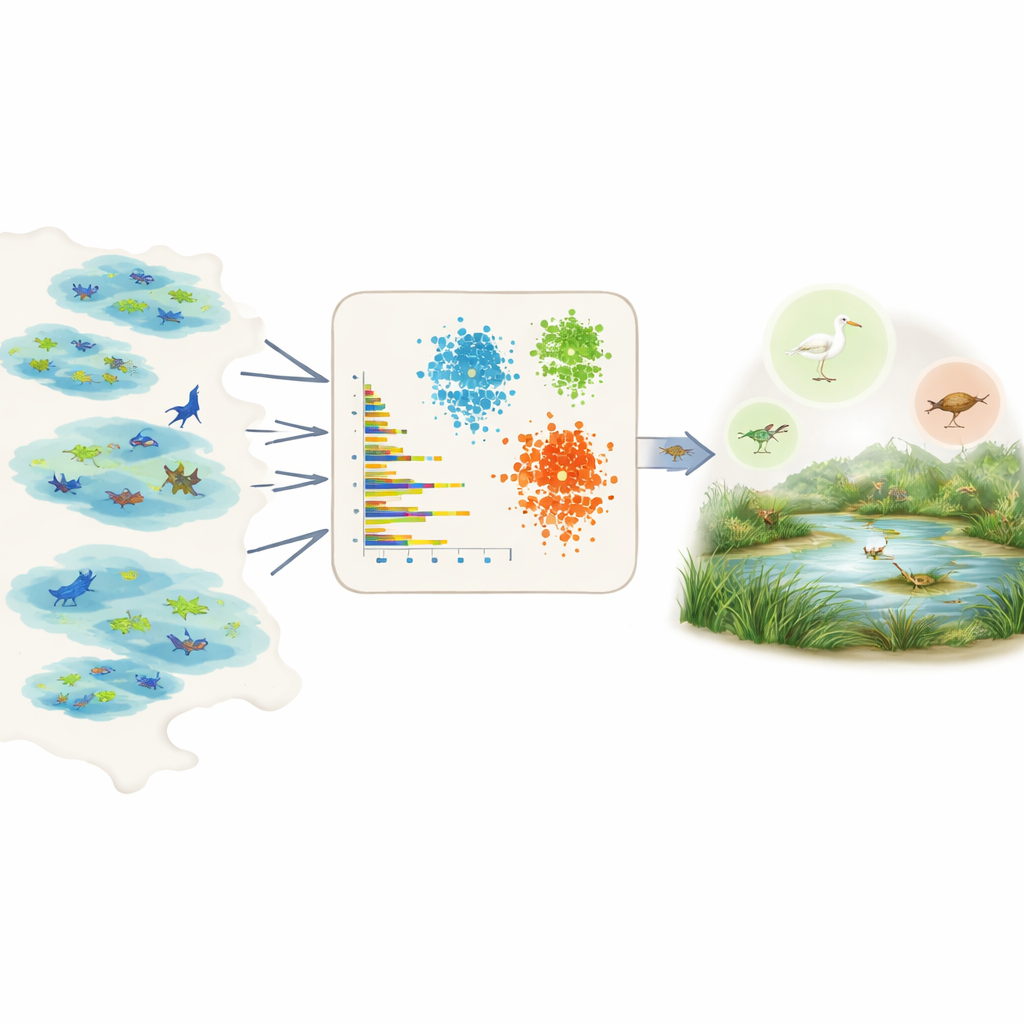
Låta data tala för hundratals arter
Att mäta prevalens direkt är svårt eftersom fältdat är ojämnt fördelade och partiska. Vissa områden är väl undersökta, vissa arter är lättare att se, och många register kommer från medborgarforskningsprojekt med varierande insats. Istället för att förlita sig på expertbedömning eller detaljerad kunskap för varje art använder författarna Global Biodiversity Information Facility, en stor öppen databas med artsobservationer. För varje art i en vald region sammanfattar de de råa registren till ett fåtal enkla, jämförbara mått: hur många individer som vanligtvis rapporteras per observation, hur många olika dataset eller våtmarker som innehåller arten, hur utbredd den är inom dessa våtmarker, och hur ofta den observeras över tid, inklusive hur ofta det förekommer toppar med många observationer.
Lära maskiner att skilja vanliga och sällsynta arter
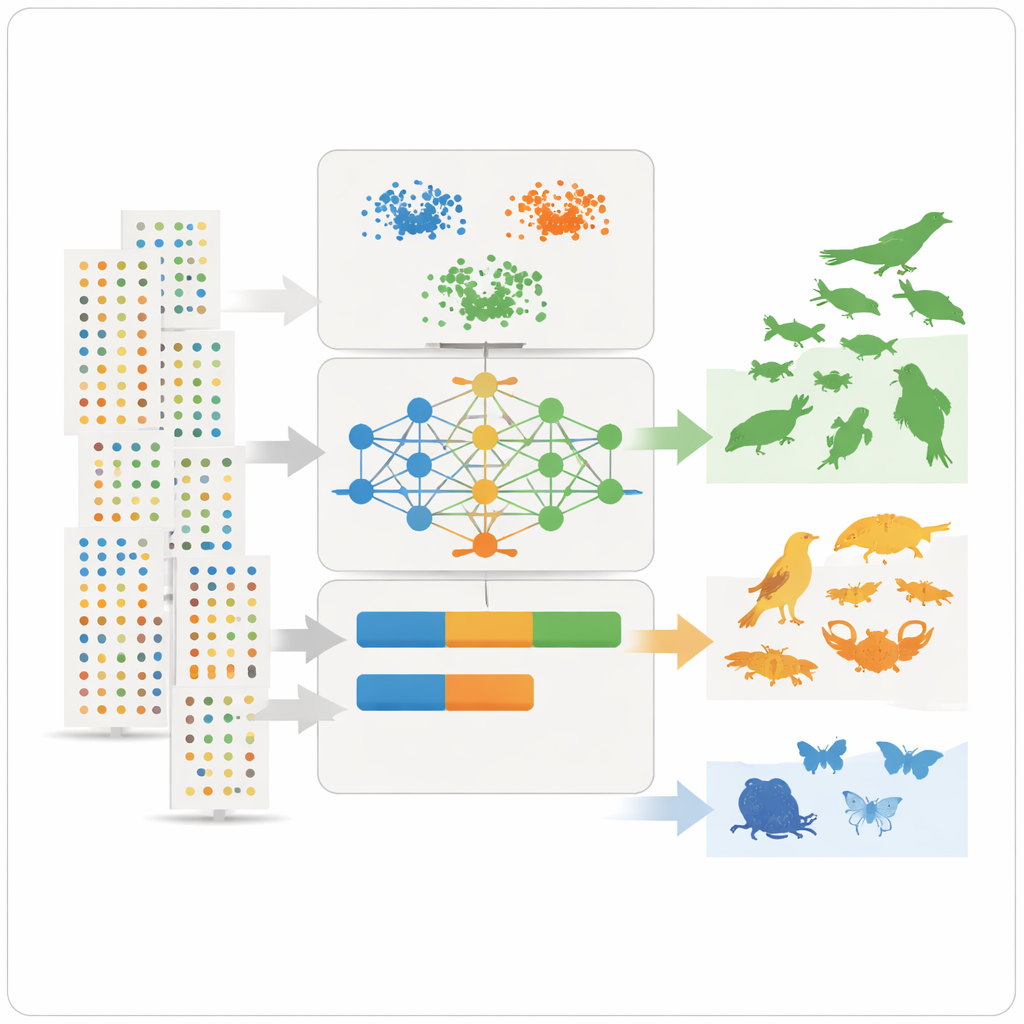
Med dessa sammanfattande funktioner till hands använder teamet tre icke-övervakade inlärningsverktyg – två klustringsmetoder och en djupinlärningsmodell känd som variational autoencoder – som letar efter mönster utan att i förväg få veta vilka arter som är vanliga eller sällsynta. Klustringsmetoderna grupperar arter som delar liknande abundans, spridning och observationsfrekvens. Autoencodern lär sig vad en “typisk” artsignal ser ut som och markerar avvikande mönster som anomalier, vilka ofta motsvarar sällsynta eller dåligt observerade arter. Modellerna tilldelar därefter varje art tre intuitiva klasser – mycket vanlig, ganska vanlig eller sällsynt – och omvandlar dessa klasser till numeriska prevalensvärden som kan matas direkt in i ekologiska nischmodeller som priorisannolikheter.
Testa metoden i en utsatt våtmark
För att testa hur väl detta ramverk fungerar i praktiken fokuserar författarna på Massaciuccoli-sjöns avrinningsområde i Toscana, Italien, en lågsluten våtmark rik på fåglar, fiskar, insekter och andra djur. Landskapet är både en hotspot för biologisk mångfald och en turistattraktion, men det är också sårbart för klimatförändringar, vattenbrist och föroreningar. För 161 djurarter knutna till sjön tränades modellerna med register från andra italienska våtmarker och fick sedan uppgiften att härleda hur vanliga arterna borde vara i Massaciuccoli. Två lokala experter med djup fälterfarenhet i området bedömde oberoende samma arter. Jämförelsen visade att djupinlärningsmodellen överensstämde med den sammanlagda expertbedömningen för cirka 81–90 procent av arterna, medan klustringsmetoderna och ett ensemble av alla tre också gav goda resultat.
Lära av oenigheter och dolda bias
Inte alla fall stämde perfekt. Några arter som experterna kände väl till som rikliga kring sjön framstod som sällsynta i datan, ofta eftersom de är svårfångade, underrapporterade eller mer noggrant bevakade i vissa våtmarker än i andra. Detta belyste en central begränsning: stora databaser speglar var och hur människor letar efter natur, inte bara var arter faktiskt förekommer. En känslighetsanalys visade vilka funktioner som betydde mest för klassificeringarna, där genomsnittligt antal poster per dataset, abundans per observation och konsekvens i observationer över år framträdde som särskilt informativa. Trots kvarstående biaser producerade metoden tydliga, reproducerbara prevalensuppskattningar och kan justeras för att använda finare eller grövre klasser beroende på modelleringsbehov.
Vad detta innebär för framtida naturprognoser
För icke-specialister är huvudbudskapet att vi nu kan använda befintliga biodiversitetsdata mer intelligent för att bedöma vilka arter som sannolikt är vanliga, medelmåttiga eller sällsynta i en given miljö, utan att handjustera varje fall. Genom att omvandla brusiga observationsregister till transparenta, datadrivna prevalensuppskattningar hjälper ramverket ekologiska modeller att göra mer realistiska prognoser om livsmiljöns lämplighet och framtida trender i biologisk mångfald. Det kan i sin tur stödja bättre planering för våtmarker som Massaciuccoli och många andra ekosystem globalt, även när fältdat är ofullständiga och expertresurser är begränsade.
Citering: Bove, P., Bertini, A. & Coro, G. Estimating species commonness and prevalence through unsupervised methods. Sci Rep 16, 8331 (2026). https://doi.org/10.1038/s41598-026-38900-1
Nyckelord: artspridning, modellering av biologisk mångfald, våtmarks-ekosystem, maskininlärning i ekologi, arters vanlighet