Clear Sky Science · sv
Seriella kaskadkopplade hybrid-adaptiva djupa nätverk för klassificering av sångtexter med optimeringsmetod
Varför smartare låtfilter spelar roll
Musik strömmar in i våra liv nästan oavbrutet, och mycket av det vi hör väljs av algoritmer. Ändå brottas många av dessa system fortfarande med en enkel fråga: vad säger egentligen orden i en låt, och vem är de lämpliga för? Denna artikel tar sig an problemet genom att bygga en avancerad artificiell intelligens (AI) som automatiskt läser låttexter och sorterar dem efter stämning, genre, sentiment och till och med typ av framförande. Målet är att hjälpa till att skapa säkrare spellistor för barn, mer träffsäkra stämningsbaserade rekommendationer och bättre verktyg för musikforskare.
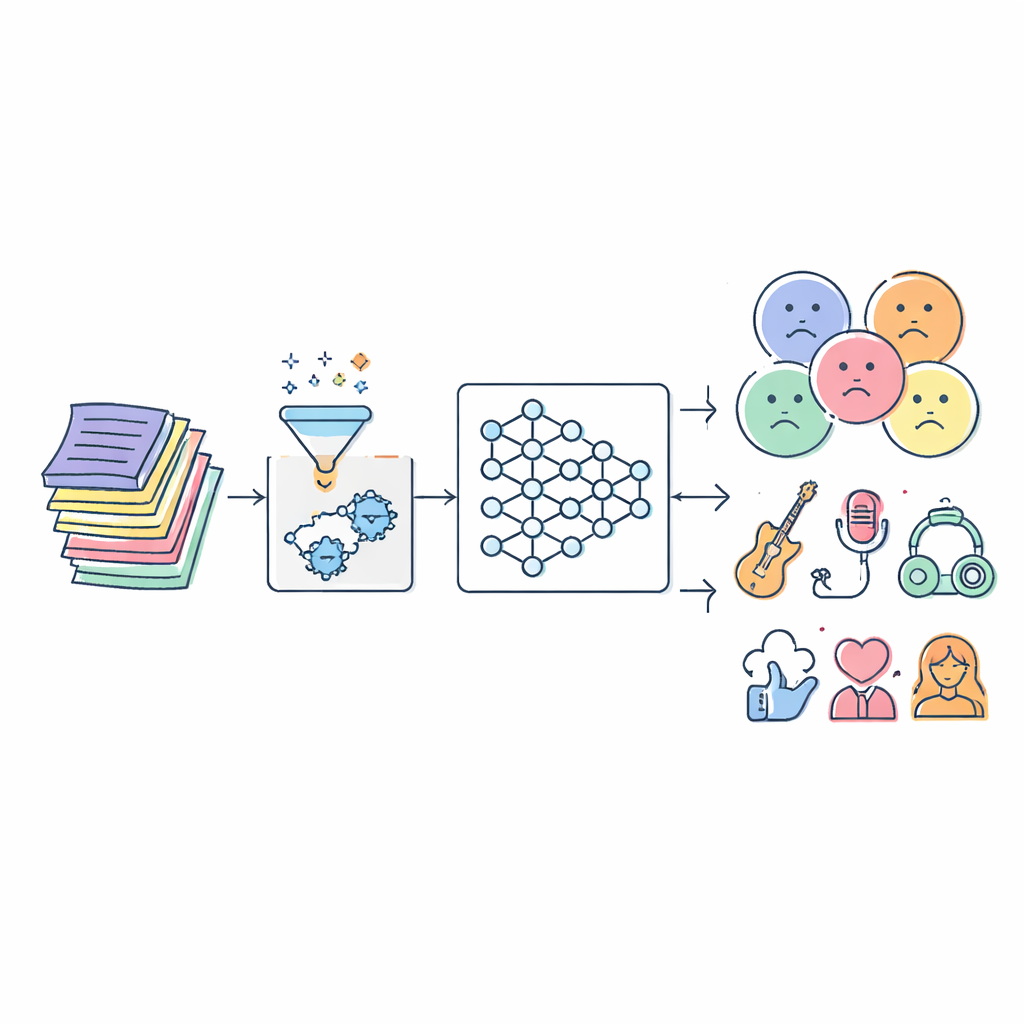
Utmaningen som döljer sig i låtord
Texterna är mycket mer komplicerade än en lista över bra eller dåliga ord. Samma fras kan kännas öm i en låt och hotfull i en annan, och lyssnare tar med sig egna erfarenheter i tolkningen. Traditionella filter förlitar sig ofta på statiska listor över stötande termer eller enkla statistiska metoder. Dessa angreppssätt missar kontext, håller inte jämna steg med slang som utvecklas och märker ofta felaktigt upp låtar. Samtidigt innebär explosionen av digital musik att det finns miljontals spår att analysera, på många språk och i många stilar, vilket överbelastar manuell märkning och äldre algoritmer.
Rensa råa låttexter
Författarna börjar med att samla stora textkorpusar från tre publika dataset som tillsammans täcker hundratusentals låtar över flera genrer och språk. Innan någon AI kan lära sig av texten måste texterna rengöras. Systemet tar bort interpunktion, specialtecken och upprepade eller irrelevanta fragment, och reducerar sedan relaterade ordformer till en gemensam rot (till exempel blir ”sjunger”, ”sjöng” och ”sjungit” alla ”sjung”). Detta förbehandlingssteg tar bort brus samtidigt som betydelsen bevaras, så att senare steg kan fokusera på känslomässig ton och ämne snarare än formateringsavvikelser eller stavningsvarianter.
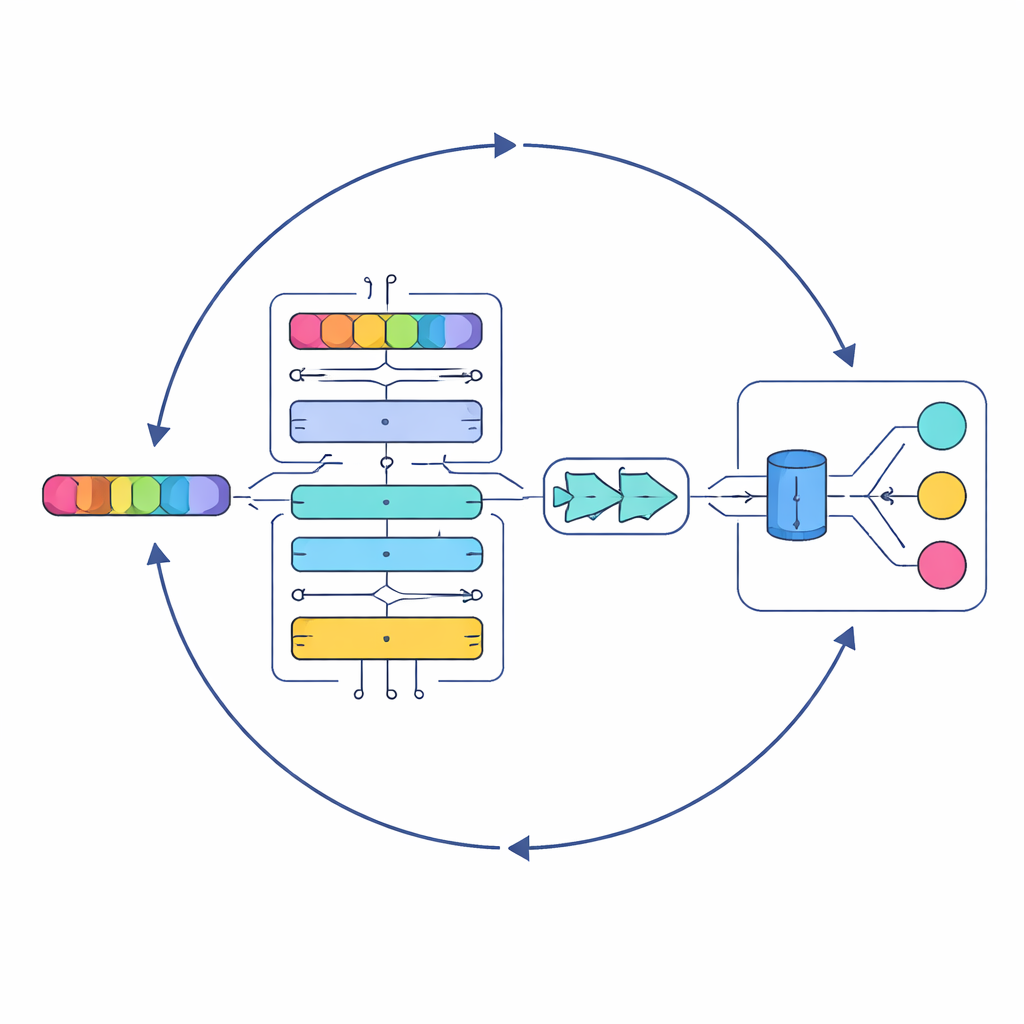
Ett lagerbyggt AI som lyssnar som en noggrann åhörare
I kärnan av studien finns en ny modell kallad Serial Cascaded Hybrid Adaptive Deep Network, eller SCHADNet. Den kombinerar tre kraftfulla idéer från modern språk-AI. För det första fångar en transformer-baserad encoder hur ord relaterar till varandra över en hel text, inte bara närområden. För det andra läser ett bidirektionellt Long Short-Term Memory-lager texten både framåt och bakåt i tiden, vilket hjälper systemet att förstå hur tidigare rader färgar betydelsen av senare. För det tredje förfinar ett Gated Recurrent Unit-lager denna information till en kompakt sammanfattning som lämpar sig väl för slutgiltiga beslut. Tillsammans agerar dessa komponenter som en kör av specialiserade läsare, där var och en fokuserar på olika aspekter av låttexten.
Att låna en strategi från havet
Att stapla djupinlärningslager räcker inte; deras interna inställningar—som hur många neuroner de innehåller och hur länge de tränas—påverkar i hög grad prestandan. Istället för att finjustera dessa val för hand vänder sig författarna till en optimeringsmetod inspirerad av jaktmönster hos marina rovdjur. Deras förbättrade Marine Predators Algorithm (IMPA) utforskar många möjliga parameterkombinationer och hittar gradvis de som ger bäst resultat. Genom att trimma bort delar av den ursprungliga algoritmen som inte hjälpte i denna tillämpning förbättrar de konvergensen, vilket innebär att systemet når bra lösningar snabbare och mer pålitligt.
Hur bra systemet presterar
Forskarlaget testar SCHADNet med IMPA på tre olika dataset med låttexter och jämför det med en rad etablerade metoder, inklusive klassiska maskininlärningsklassificerare och flera populära djupinlärningsmodeller som enkel LSTM, transformer–endast system och hybrida nätverk. Över mått som noggrannhet, recall (hur många verkligt relevanta låtar som hittas) och andra kvalitetsmått presterar den nya metoden konsekvent bäst. På ett stort flerspråkigt dataset klassificerar den omkring 93 % av låtarna korrekt och uppnår särskilt högt negativt prediktivt värde, vilket betyder att den är mycket bra på att identifiera texter som inte hör hemma i en flaggad kategori—avgörande för att undvika överdriven blockering eller felmärkning.
Vad detta betyder för lyssnare och skapare
För en lekman är budskapet tydligt: författarna har byggt en mer nyanserad och pålitlig läsare för låttexter. Istället för att förlita sig på grova ordlistor ser deras system hela fraser, kontext och mönster över stora musikskatter och tilldelar automatiskt etiketter som stämning, stil eller lämplighet för yngre publik. Även om modellen är komplex och kräver mycket beräkningsresurser öppnar den dörren för smartare föräldrakontroller, rikare stämningsbaserade spellistor och nya sätt att studera trender i populärmusiken. Framtida arbete syftar till att minska dess behov av data och snabba upp träningen, men även i sin nuvarande form pekar SCHADNet mot en framtid där musikplattformar förstår texter nästan lika noggrant som en uppmärksam mänsklig lyssnare.
Citering: Jasmine, R.L., Mukherjee, S., Robin, C.R.R. et al. Serial cascaded hybrid adaptive deep networks-based lyrics text classification using optimization approach. Sci Rep 16, 8527 (2026). https://doi.org/10.1038/s41598-026-38813-z
Nyckelord: musikrekommendation, texteranalys, textklassificering, djuplärande, innehållsmoderering