Clear Sky Science · sv
Förbättrad upptäckt av abonnemangsfusk med ensemble‑inlärning: fallet Ethio Telecom
Varför telefonbedrägeri berör alla
Varje gång vi ringer, skickar ett sms eller använder mobildata litar vi på att fakturan motsvarar det vi faktiskt använt. Men kriminella kan utnyttja telenät genom att öppna abonnemang med falska identiteter, samla på sig stora obetalda avgifter och till och med använda dessa linjer för andra brott. Denna studie fokuserar på Ethio Telecom, Etiopiens nationella operatör, och visar hur avancerade datadrivna metoder kan upptäcka misstänkta abonnemang mycket mer träffsäkert än traditionella verktyg, vilket hjälper till att hålla telefonitjänster prisvärda och säkra för miljontals användare.
Den dolda kostnaden för falska telefonkonton
Abonnemangsfusk uppstår när någon registrerar sig för telefonservice med falska eller stulet uppgifter och aldrig tänker betala. Globalt är detta en av de mest förödande formerna av telekombedrägeri och kostar branschen tiotals miljarder dollar varje år. Enbart för Ethio Telecom beräknas bedrägerierna tömma omkring en miljard dollar årligen, där falska abonnemang står för ungefär 40 procent av förlusten. Utöver förlorade intäkter kan dessa linjer användas för bedrägerier, vidareförsäljning av internationella samtal eller andra olagliga aktiviteter, vilket utgör risker både för kunder och nationell säkerhet.
Från handgjorda regler till inlärning från data
Liksom många operatörer förlitade sig Ethio Telecom traditionellt på experter som utformade fasta regler för att flagga misstänkt beteende—till exempel att blockera en linje efter för många internationella samtal på kort tid. Dessa regelbaserade system är lätta att förstå men har svårt när bedragare ändrar taktik eller när användarmönster är komplexa. Författarna menar att maskininlärning, som lär sig mönster direkt från historiska data, kan reagera snabbare och känsligare. Istället för att förlita sig på en enda modell undersöker de ”ensemble”-metoder som kombinerar flera modeller, och ”adaptiva” metoder som kontinuerligt uppdateras när nya data kommer in.
Vad forskarna byggde från verkliga samtalsloggar
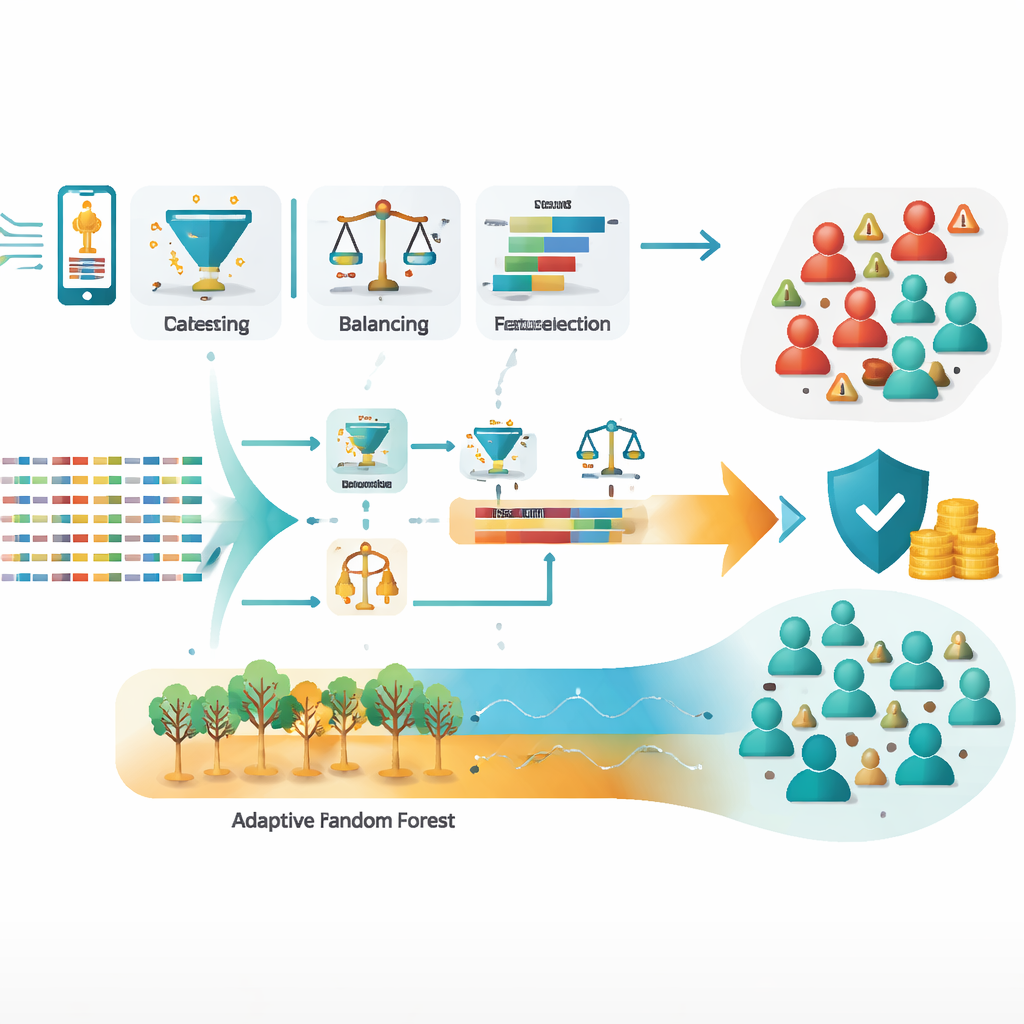
Teamet arbetade med ett stort antal anropsdetaljposter—loggar över vem som ringde vem, hur länge och under vilka förhållanden—från en tvåmånadersperiod känd för intensiv bedrägeriverksamhet. Utifrån cirka en miljon rådata rensade de upp datasetet, tog bort fel och dubbletter, balanserade de kraftigt snedfördelade klasserna (många fler ärliga användare än bedragare) och konstruerade nya funktioner som bättre fångar misstänkt beteende. Särskilt viktiga var mått som hur många internationella nummer en abonnent ringde, andelen av alla samtal som var internationella och förhållandet mellan unika nummer som ringts och totala samtal. Dessa destillerade signaler skiljer ofta normalt bruk från organiserat missbruk mycket bättre än enkla räkningar eller demografiska uppgifter.
Hur kombination av modeller förbättrar upptäckt
Forskarlaget testade tre standardmodeller—beslutsträd, logistisk regression och artificiella neurala nätverk—tillsammans med flera ensemble‑strategier såsom bagging (Random Forest), boosting (XGBoost), voting och stacking, samt adaptiva modeller avsedda för kontinuerliga datastreams (Hoeffding Tree och Adaptive Random Forest). Efter noggrann inställning av varje modells parametrar uppnådde stacking‑ansatsen, som lär sig hur man blandar styrkorna hos flera basmodeller, ungefär 99,3 procent träffsäkerhet på oanvänd data. Adaptive Random Forest var nästan lika stark med cirka 99,2 procent träffsäkerhet, samtidigt som den kan anpassa sig när bedrägarmönstren skiftar över tid. Båda angreppssätten minskade markant det farligaste felet—att missa verkligt bedrägeri—jämfört med enstaka modeller.
Hänga med i förändrade trick i realtid
Eftersom bedragare ständigt förändrar sina metoder kan en statisk modell snabbt bli föråldrad. För att hantera detta använde författarna en online‑funktion‑urvalsmetod som kontinuerligt omvärderar vilka signaler som är viktigast, utan att behöva bygga om systemet från grunden. De betonar också vikten av integritet: alla personliga identifierare i data anonymiserades före analys, och de rekommenderar strikta åtkomstkontroller och revisionsspår. För praktisk driftsättning skisserar studien en realtidsarkitektur där nya samtalsloggar strömmas genom verktyg som Apache Kafka in i adaptiva modeller som uppdateras på direkten samtidigt som de övervakar plötsliga förändringar i beteende.
Vad detta betyder för telefonanvändare och leverantörer
Enkelt uttryckt visar studien att låta flera intelligenta modeller ”rösta” tillsammans och låta dem lära sig kontinuerligt kan fånga falska abonnemang med anmärkningsvärd noggrannhet samtidigt som falsklarm hålls på hanterbara nivåer. För Ethio Telecom kan detta innebära betydande besparingar, stabilare prissättning och bättre skydd mot kriminalitet på nätverket. För kunder betyder det att ovanlig men legitim användning är mindre benägen att feltolkas som bedrägeri, medan verkligt riskfyllda linjer upptäcks och stängs snabbare. Författarna slutsatser är att ensemble‑ och adaptiv inlärning, förankrade i noggrant utvalda, kontextspecifika indikatorer, erbjuder en kraftfull och skalbar modell för modern upptäckt av telekombedrägerier.
Citering: Desta, E.A., Azale, K.W., Hailu, A.A. et al. Enhancing subscription fraud detection through ensemble learning the case of Ethio telecom. Sci Rep 16, 7867 (2026). https://doi.org/10.1038/s41598-026-38790-3
Nyckelord: telekombedrägeri, abonnemangsfusk, ensemble‑inlärning, adaptiv slumpmässig skog, anropsdetaljposter