Clear Sky Science · sv
Utvärdering av stora språkmodellers prestanda på persiska reumatologi-styrelseprov: noggrannhet och kliniskt resonemang hos GPT-4o vs. GPT-5.1
Varför detta är viktigt för läkare och patienter
Artificiell intelligens tränger snabbt in i medicinska skolor och kliniker, men de flesta tester av dessa verktyg fokuserar på engelska. Denna studie ställer en fråga som berör miljontals persisktalande: hur väl hanterar avancerade AI-chattrobotar, särskilt GPT‑4o och GPT‑5.1, komplexa reumatologifrågor skrivna på persiska? Svaret hjälper lärare, underläkare och patienter att förstå var dessa verktyg kan bistå inlärning på ett säkert sätt och var mänsklig expertis fortfarande är avgörande.
Att sätta AI på prov
Forskarna samlade 204 flervalsfrågor från de officiella iranska reumatologi-styrelseproven 2023 och 2024, samma prov som specialister måste klara för att bli certifierade. Efter att ha tagit bort sju bristfälliga frågor användes 197 uppgifter. Varje fråga, inklusive eventuella medföljande bilder eller diagram, matades in på persiska i GPT‑4o respektive GPT‑5.1 i separata nya chattar. Modellerna ombads välja det bästa svaret och förklara sitt resonemang, vilket speglar hur en underläkare kan fråga ett AI-verktyg under studier.
Kontroll av både svar och resonemang
Prestanda bedömdes på två sätt. För det första jämfördes modellernas valda alternativ med den officiella facit, vilket gav en enkel rätt-eller-fel-noggrannhetsmätning. För det andra bedömde sex styrelsecertifierade reumatologer oberoende kvaliteten på varje förklaring på en femgradig skala, från klart felaktigt resonemang till fullständigt och kliniskt hållbart resonemang. Varje modells svar granskades av två olika reumatologer som var blinda för varandras bedömningar och för facit. Det gjorde det möjligt för forskarna att se inte bara om AI:n "gissade rätt", utan också om dess logik efterliknade hur specialister tänker.
Hur den nyare modellen presterade
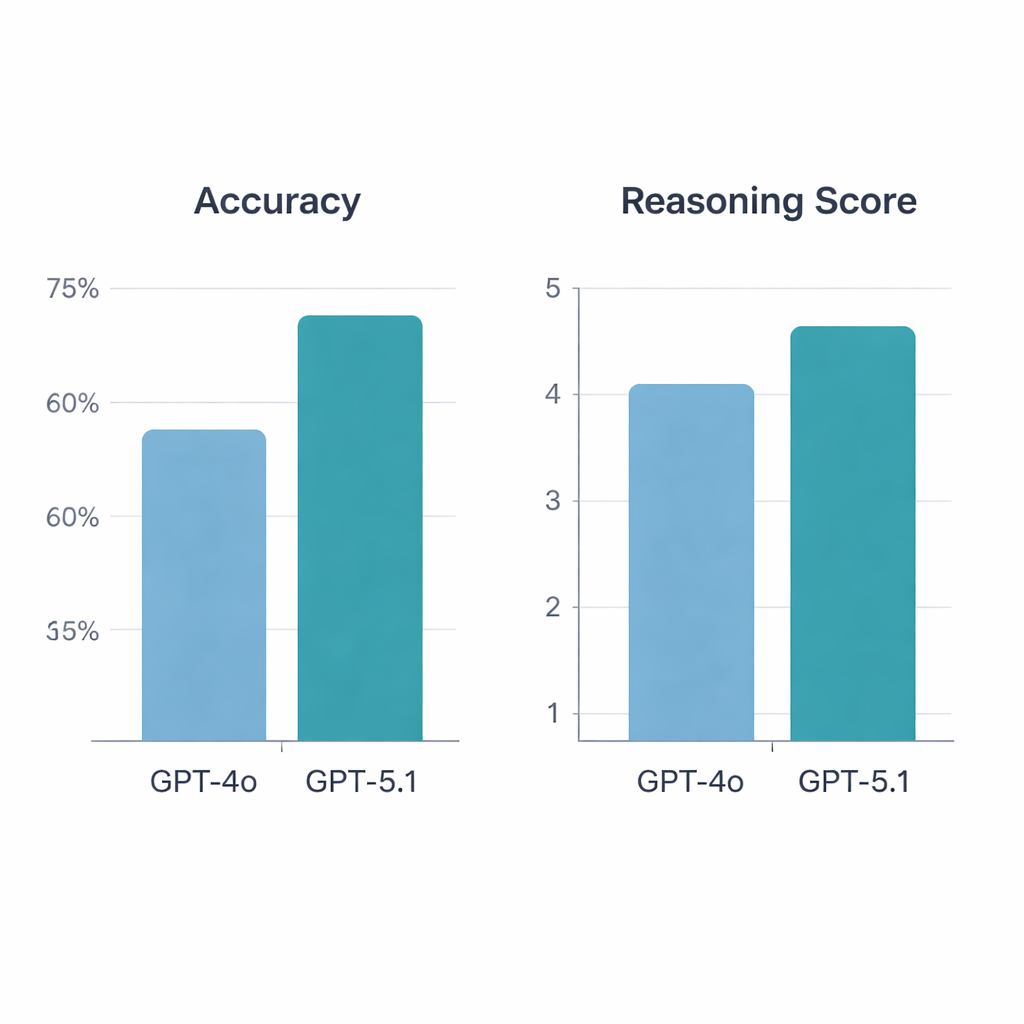
GPT‑5.1 presterade tydligt bättre än GPT‑4o. På de 197 giltiga frågorna svarade GPT‑4o korrekt på 64,5 %, medan GPT‑5.1 nådde 76 %—en statistiskt signifikant ökning. Båda modellerna klarade 113 frågor och svarade fel på 34, men GPT‑5.1 löste ensam ytterligare 36 frågor som GPT‑4o missade; GPT‑4o var unikt korrekt på endast 13. När reumatologerna graderade förklaringarna kom GPT‑5.1 återigen bättre ut, med ett genomsnittligt resonemangspoäng på 4,47 av 5 jämfört med 4,13 för GPT‑4o, och den fick fler toppbetyg. Till skillnad från GPT‑4o, vars resonemangskvalitet varierade beroende på om en fråga fokuserade på grundvetenskap, fallvignetter, diagnostik eller behandling, höll GPT‑5.1 en jämnare prestanda över alla kategorier.
Styrkor, brister och mänskliga meningsskiljaktigheter
Studien upptäckte viktiga nyanser. Även när en modells slutliga svar var fel bedömde specialister ibland att dess resonemang var relativt sammanhängande, vilket belyser en klyfta mellan provpoängsättning och verkligt kliniskt tänkande. Samtidigt var överensstämmelsen mellan reumatologernas bedömningar endast måttlig, vilket understryker att kliniker själva kan vara oense om vad som räknas som "gott resonemang". Språket verkar också spela roll: tidigare arbete på engelska och spanska har rapporterat högre poäng för liknande modeller, vilket tyder på att AI fortfarande hanterar stora världsspråk bättre än persiska. Författarna betonar att dessa chattrobotar kan generera övertygande förklaringar som kan dölja faktiska fel, och att deras prestanda kan förändras när systemen uppdateras.
Vad detta betyder framöver
För allmänheten är budskapet att den senaste generationens AI-chattrobotar blir bättre på att hantera specialistmedicinska prov på persiska, men de är inte redo att ersätta rigorös utbildning eller expertdom. GPT‑5.1 kan vara en användbar studiepartner för reumatologistudenter—sammanfatta ämnen, gå igenom fall och erbjuda strukturerade förklaringar—men den bör inte litas på som sista instans vid höginsatsbeslut om diagnostik eller behandling. Författarna efterlyser större, flerspråkiga studier, upprepade tester över tid och realistiska kliniska simuleringar för att avgöra hur dessa verktyg säkert kan vävas in i medicinsk utbildning och, så småningom, i daglig patientvård.
Citering: Rafiei, F., Sadeghipour, S., Sheikhalishahi, S. et al. Evaluation of large Language model performance on Persian rheumatology board exams: accuracy and clinical reasoning of GPT-4o vs. GPT-5.1. Sci Rep 16, 7274 (2026). https://doi.org/10.1038/s41598-026-38716-z
Nyckelord: reumatologi, persisk medicinsk utbildning, stora språkmodeller, kliniskt resonemang, styrelseprov