Clear Sky Science · sv
ImageNet-förtränade nätverk och tvåstegs transferinlärning vid klassificering av kromosombilder
Skarpare vyer av våra kromosomer
Våra kromosomer bär instruktionerna för att bygga och driva våra kroppar, och läkare studerar deras form för att upptäcka genetiska avvikelser och vissa cancerformer. Idag kan datorer hjälpa till att läsa kromosombilder, men att lära dem göra det bra är svårt eftersom medicinska bilder är ovanliga och ser mycket annorlunda ut än vanliga fotografier. Den här studien ställer en enkel fråga med stor praktisk betydelse: kan datorer lära sig bättre av närbesläktade medicinska bilder, och inte bara från jättestora samlingar av bilder på katter, hundar och bilar?
Varför kromosombilder är viktiga
På sjukhus ordnar specialister en persons 46 kromosomer i ett diagram som kallas en karyotyp, grupperade i 24 typer (22 numrerade par plus X och Y). Subtila mörka och ljusa band längs varje kromosom hjälper till att avslöja saknade eller extra delar som är kopplade till tillstånd som Downs syndrom eller vissa leukemier. Traditionellt klassificerar experter dessa band med ögat, vilket är tidskrävande och subjektivt. Djuplärning erbjuder ett sätt att automatisera arbetet, men dessa system startar ofta från modeller förtränade på ImageNet, en massiv datamängd av vardagsbilder. Hoppet—från semesterbilder till mikroskopiska kromosomvyer—är stort, och det är oklart hur väl den erfarenheten faktiskt överförs.
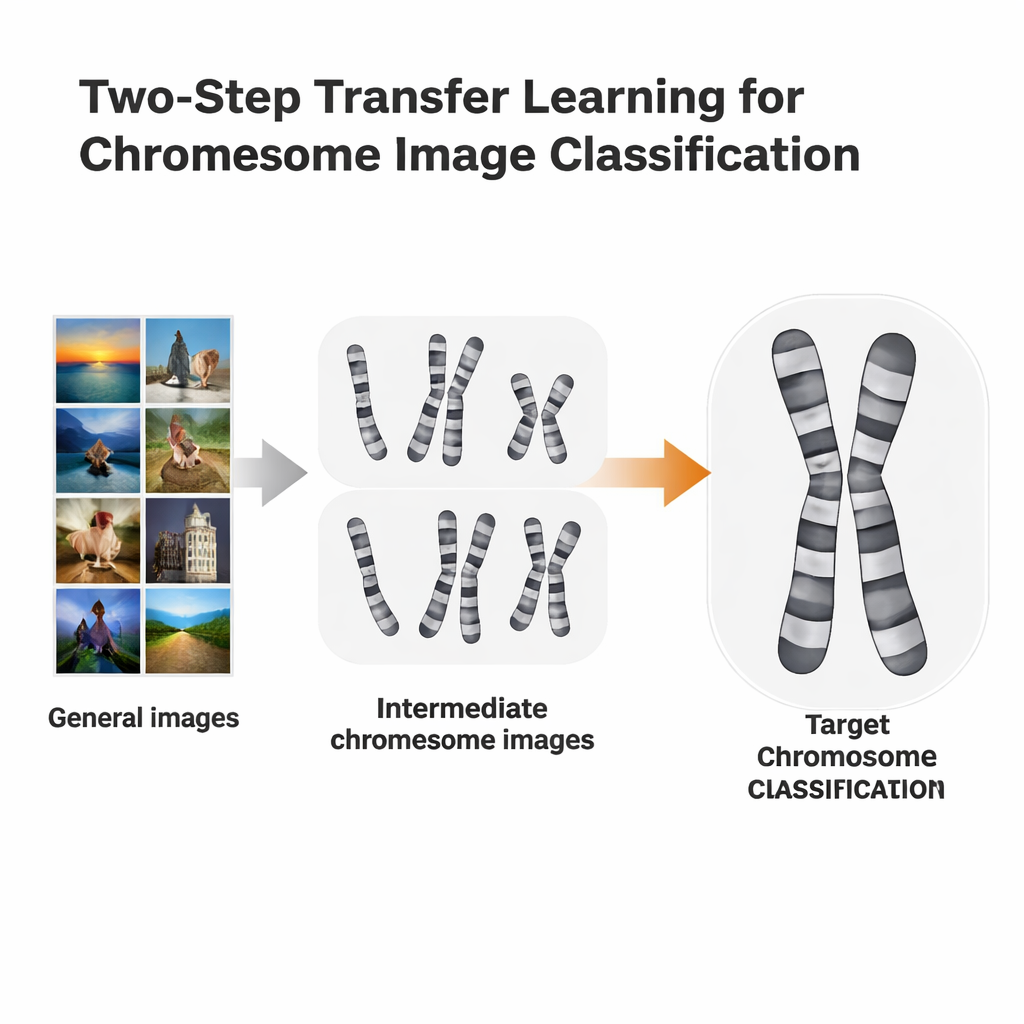
En tvåstegsinlärningsgenväg
Forskarna testade en mer anpassad träningsväg kallad tvåstegs transferinlärning. Istället för att gå direkt från ImageNet till en specifik kromosomuppgift finjusterade de först ImageNet-förtränade modeller på kromosombilder från en färgningsmetod och finjusterade sedan igen på en andra, något annorlunda metod. De använde två öppna dataset: Q-band-bilder, som är av lägre kvalitet och svårare att läsa, och G-band-bilder, som är renare och mer detaljerade. Varje dataset fick turas om att spela rollen som "stege" för det andra. Idén liknar språkinlärning: om du redan kan spanska kan det vara lättare att lära dig italienska än att hoppa direkt från engelska.
Test av många dator"ögon"
För att se när detta extra steg hjälper tränade teamet 66 olika klassificerare, genom att kombinera 11 populära neurala nätverksarkitekturer med tre strategier: träna från noll, finjustera från ImageNet endast, och använda tvåstegs transfer. De mätte prestanda med Macro-F1, ett mått som behandlar alla kromosomtyper rättvist, inklusive de sällsynta. Först bekräftade de att Q-band- och G-band-bilder statistiskt sett är mer lika varandra än någon av dem är ImageNet-foton, vilket gör dem till lovande mellanliggande steg. Sedan jämförde de hur väl de olika modellerna lärde sig under varje strategi på både det lättare (G-band) och det svårare (Q-band) datasetet.
När det extra steget lönar sig
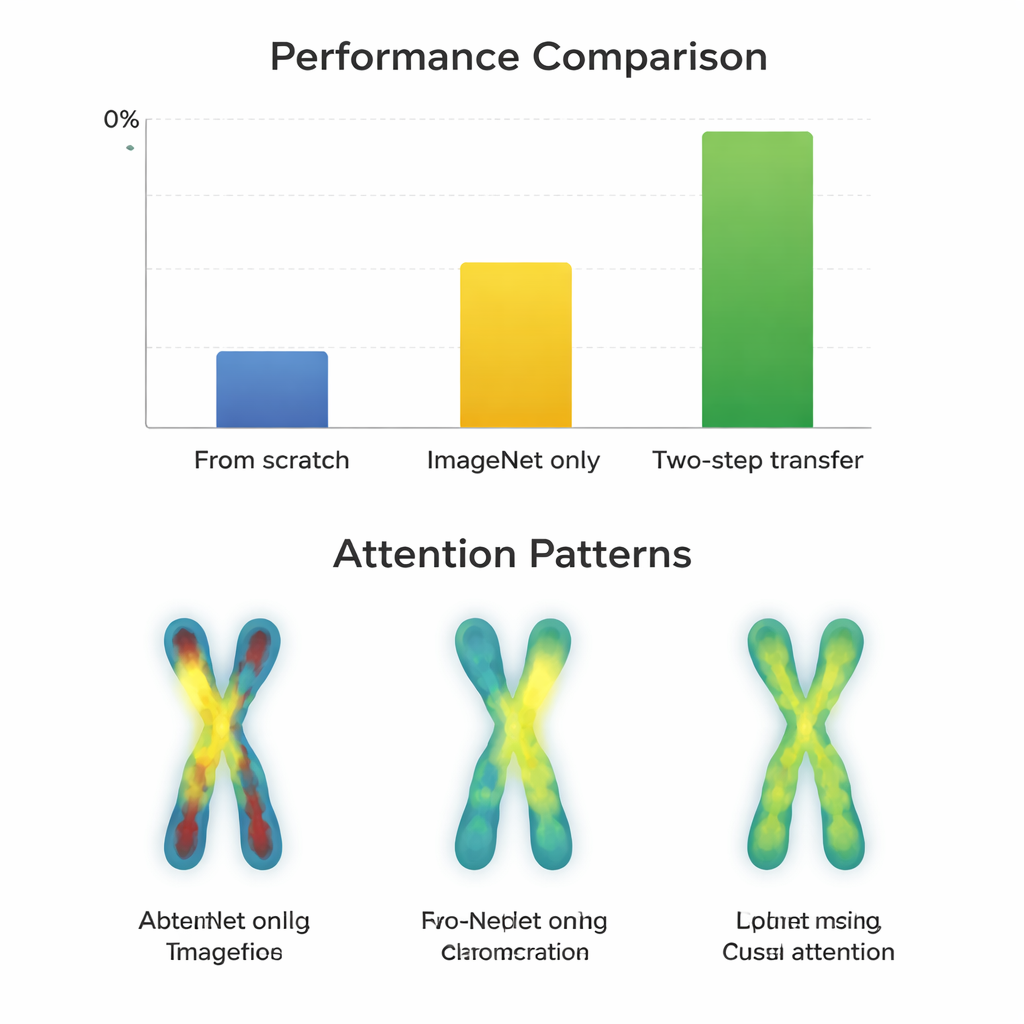
På de högkvalitativa G-band-bilderna presterade nästan alla modeller redan mycket bra efter enkel ImageNet-finjustering, med poäng runt 97–98 procent. Här gav den extra tvåstegsträningen bara små förbättringar—ofta mindre än en procentenhet—och skadade ibland äldre nätverksdesigner. I kontrast, på de mer utmanande Q-band-bilderna förändrades bilden. Moderna, kompakta arkitekturer som ConvNeXt, Swin Transformer, Vision Transformer och MobileNetV3 gynnades tydligt av tvåstegsmetoden och förbättrades med cirka 0,8 till 3,3 procentenheter jämfört med enbart ImageNet. Visualiseringar av var modellerna "tittade" visade varför: med tvåstegs transfer fokuserade nätverken mer jämnt längs kromosombanden på båda armarna, i stället för bara på konturer eller ett enda område. Däremot fick mycket stora, äldre nätverk som VGG inga fördelar och blev ibland sämre, vilket tyder på att smartare design kan överträffa ren storlek.
Begränsningar satta av själva data
Forskarna granskade också fel på G-band-bilderna. Vissa missar berodde inte på inlärningsstrategin utan på bristfälligt inputmaterial, till exempel kromosomer som blivit dåligt beskurna när överlappande former separerades. I sådana fall hade alla träningsmetoder svårt, och uppmärksamhetskartorna var spridda eller fixerade vid vilseledande kanter. Det här lyfter fram ett praktiskt budskap för kliniker och utvecklare: även den bästa träningspipeline kan inte helt övervinna dålig bildkvalitet eller felaktig förbehandling, särskilt när man arbetar med måttligt stora dataset som de som finns för kromosombilder.
Vad detta betyder för verklig diagnostik
För icke-specialister är huvudslutsatsen att smart återanvändning av närbesläktade medicinska bilder kan göra automatisk kromosomavläsning mer exakt—särskilt när måldata är brusiga eller knapphändiga och när man använder moderna, noggrant utformade neurala nätverk. För högkvalitativa bilder kan standardtraining baserad på ImageNet redan vara tillräcklig. Men när patologer arbetar med tuffare dataset kan ett extra inlärningssteg med en nära relaterad bildtyp skärpa datorns "öga" och höja prestandan till intervallet 93–98 procent. Denna metod kan också sträcka sig bortom kromosomer till många områden inom medicinsk bildbehandling där etiketterade data är begränsade, och därigenom hjälpa till att föra tillförlitliga AI-verktyg närmare vardaglig klinisk praxis.
Citering: Chen, T., Xie, C., Zhang, W. et al. ImageNet pre-training and two-step transfer learning in chromosome image classification. Sci Rep 16, 7572 (2026). https://doi.org/10.1038/s41598-026-38662-w
Nyckelord: kromosomklassificering, medicinsk bild-AI, transferinlärning, djuplärningsmodeller, karyotypering