Clear Sky Science · sv
FedSCOPE: Federated cross-domain sequential recommendation with decoupled contrastive learning and privacy-preserving semantic enhancement
Varför smartare och säkrare rekommendationer är viktiga
Varje gång du söker efter filmer, handlar online eller läser recensioner bestämmer rekommendationssystem tyst vad som visas för dig härnäst. Allteftersom våra digitala liv sprids över många appar och webbplatser skulle dessa system kunna bli mycket bättre om de kunde lära sig av all din aktivitet på en gång—utan att någonsin exponera dina privata uppgifter. Denna artikel presenterar FedSCOPE, ett nytt sätt för olika plattformar att samarbeta kring rekommendationer som både är mer träffsäkra och mer respektfulla mot användarnas integritet.
Problemet med dagens rekommendationsmotorer
De flesta nuvarande rekommendationssystem finns inom en enda app eller webbplats och ser bara en snäv del av ditt beteende. Det innebär att de har svårt med så kallade ”cold-start”-användare som har lite historik, eller med nischprodukter som få personer interagerar med. När företag försöker kombinera data över domäner—som böcker och filmer, eller mat och köksredskap—stöter de på tre stora problem: data är ofta gles, olika plattformar har mycket olika typer av användare och aktiviteter, och strikta sekretessregler gör det riskabelt att samla rådata på ett och samma ställe. Enkla lösningar, som att lägga till samma mängd sekretessbevarande brus för alla, tenderar antingen att försvaga skyddet eller kraftigt skada träffsäkerheten.
Låta språkmodeller fylla i luckorna
FedSCOPE tar itu med problemet med gles data genom att låta varje plattform berika sin data med hjälp av en stor språkmodell (LLM), men på ett ovanligt, integritetsmedvetet sätt. Istället för att skicka användarhistorik till en fjärr-AI-tjänst vid varje rekommendation kör varje klient en engångs offline-process: den matar in titlar och grundläggande artikelinformation (till exempel en films namn och genre) till en LLM och ber om strukturerade beskrivningar, såsom troliga teman, tittvanor eller relaterade intressen. Dessa genererade attribut ligger kvar på den lokala enheten eller servern och förenas med vanliga klick- och visningshistoriker med hjälp av ett lättviktigt neuralt nätverk. Det ger systemet en rikare förståelse av både användare och artiklar, vilket är särskilt användbart när det finns få registrerade interaktioner. Eftersom processen är offline och lokal lämnar aldrig rått beteende plattformen, och det finns inget fortlöpande beroende av externa AI-tjänster.
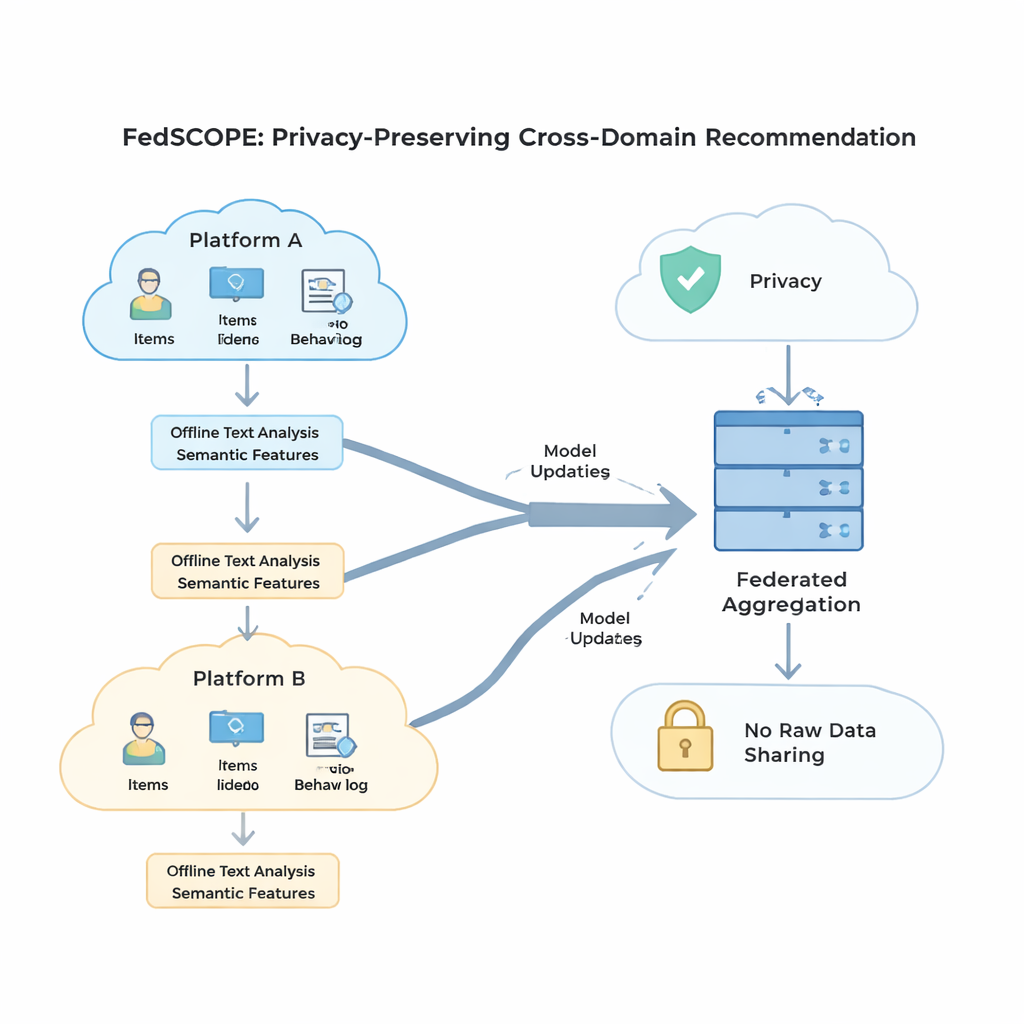
Separera vad som är personligt från vad som delas
För att kunna utnyttja beteenden från flera domäner utan att blanda signaler på ett skadligt sätt inför FedSCOPE en träningsstrategi kallad decoupled contrastive learning (avkopplad kontrastiv inlärning). Enkelt uttryckt lär sig systemet två saker samtidigt. För det första, inom varje domän—säg bara filmsidan—drar det ihop användare som beter sig likartat och skiljer dem från dem som inte gör det, vilket skärper känslan för personlig smak inom den miljön. För det andra, över domäner, justerar det representationer av samma användare samtidigt som olika användare hålls isär, så att vad du tittar på kan hjälpa till att förutsäga vad du kanske läser eller köper utan att sudda ihop dig med andra. Genom att hantera dessa mål "inom domän" och "över domän" separat undviker metoden en vanlig fallgrop där man tvingar allt in i en enda gemensam form som förstör finkorniga preferenser.
Skydda integriteten utan att offra användbarhet
Stark matematisk integritet, känd som differentialsekretess, betyder vanligtvis att man lägger till slumpmässigt brus till modelluppdateringar innan de delas med en central server. Många tidigare system använde samma sekretessinställningar för alla deltagare, vilket är en dålig lösning när vissa klienter har miljontals användare och andra bara några tusen. FedSCOPE ger istället varje klient en personlig sekretessbudget och anpassar hur mycket den klipper och perturbear sina uppdateringar baserat på datamängd och tidigare beteende. Stora, datarika plattformar kan bidra med mer precisa uppgifter utan att överbrusas, medan mindre plattformar skyddas mer aggressivt. Alla uppdateringar kombineras sedan med säker aggregering, så servern aldrig ser något individuellt bidrag i klartext.
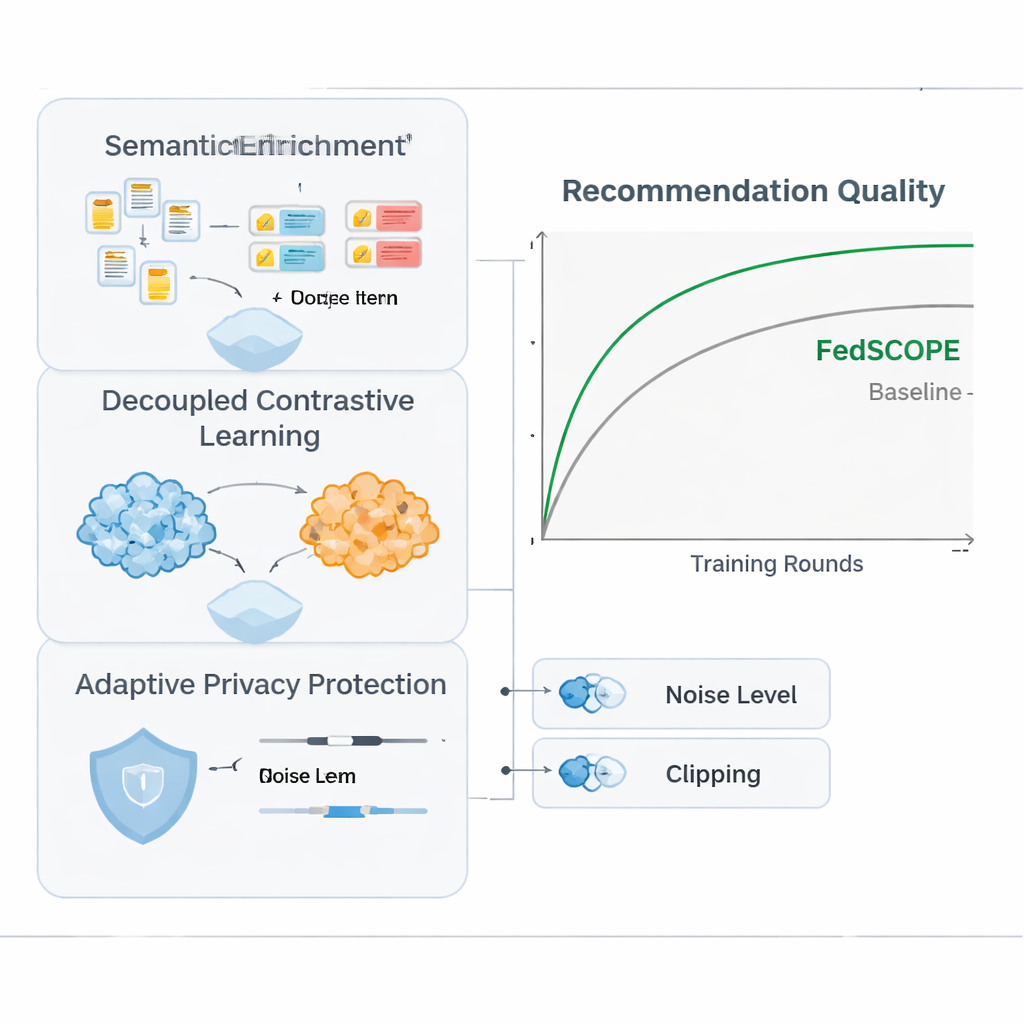
Vad experimenten visar i praktiken
Författarna testade FedSCOPE på verkliga köpdata från Amazon, genom att para ihop domäner som Filmer med Böcker och Mat med Kök. De jämförde det med en rad moderna rekommendationsmetoder, inklusive andra sekretessbevarande och tvärdomänsmetoder. Över flera mått på träffsäkerhet placerade sig FedSCOPE konsekvent i toppen eller nära toppen. Det konvergerade snabbare under träning, fungerade bättre för användare med mycket få tidigare interaktioner och höll måttet väl när antalet deltagande klienter eller den andel som samplades varje runda förändrades. Viktigt är att när teamet stramade åt sekretessbegränsningarna behöll FedSCOPE:s adaptiva strategi betydligt högre prestanda än system som använder en universell differentialsekretess.
Vad det betyder för vardagsanvändare
Ur en lekmans perspektiv pekar FedSCOPE mot en framtid där dina favoritappar kan samarbeta för att förstå dina preferenser djupare utan att någonsin slå ihop din rådata. Genom att berika glesa historiker med insikter från språkmodeller, noggrant separera vad som är domänspecifikt från vad som delas, och finjustera sekretesskontroller för varje deltagare, levererar ramverket rekommendationer som både är mer relevanta och mer respektfulla mot personlig information. I praktiken kan det innebära bättre förslag på vad du ska titta på, läsa eller köpa härnäst—utan att behöva byta bort din digitala integritet.
Citering: Zhao, L., Lin, Y., Qin, S. et al. FedSCOPE: Federated cross-domain sequential recommendation with decoupled contrastive learning and privacy-preserving semantic enhancement. Sci Rep 16, 7420 (2026). https://doi.org/10.1038/s41598-026-38628-y
Nyckelord: federerad rekommendation, sekretessbevarande AI, tvärdomän-personalisering, stora språkmodeller, differentialsekretess