Clear Sky Science · sv
Utforska interaktionen mellan lärare och elev genom multimodala stora språkmodeller: en empirisk undersökning
Varför det spelar roll att låta AI iaktta klassrum
Den som någon gång suttit i ett klassrum vet att hur lärare och elever interagerar kan vara skillnaden mellan tristess och verkligt lärande. Ändå är det förvånansvärt svårt att studera dessa ögonblick‑för‑ögonblick‑utbyten: observatörer blir trötta, mänskliga bedömningar skiljer sig åt och videomaterial växer snabbt till en överväldigande mängd data. Den här artikeln undersöker hur en ny typ av artificiell intelligens—multimodala stora språkmodeller som kan ”se” bilder och ”läsa” text—kan hjälpa forskare och skolor att snabbare och mer objektivt förstå det komplexa klassrumslivet.
Att göra verkliga lektioner till forskningsdata
Forskarna började med vanliga klassrumsvideor från kinesiska grund‑ och gymnasieskolor, offentligt tillgängliga på en nationell utbildningsplattform. Från 30 lektioner extraherade de nästan 2 400 stillbilder som fångade centrala ögonblick av undervisning och lärande. Varje bild märktes upp enligt fem lättförståeliga interaktionsmönster: guidad (läraren förklarar), kollaborativ (elever samarbetar), frågeställande (frågor och svar), självständig (elever arbetar ensamma) och uppvisande (elever presenterar inför klassen). Experter inom utbildningsteknologi hjälpte till att förfina dessa kategorier så att de stämde överens med vad erfarna observatörer letar efter i verkliga klassrum.
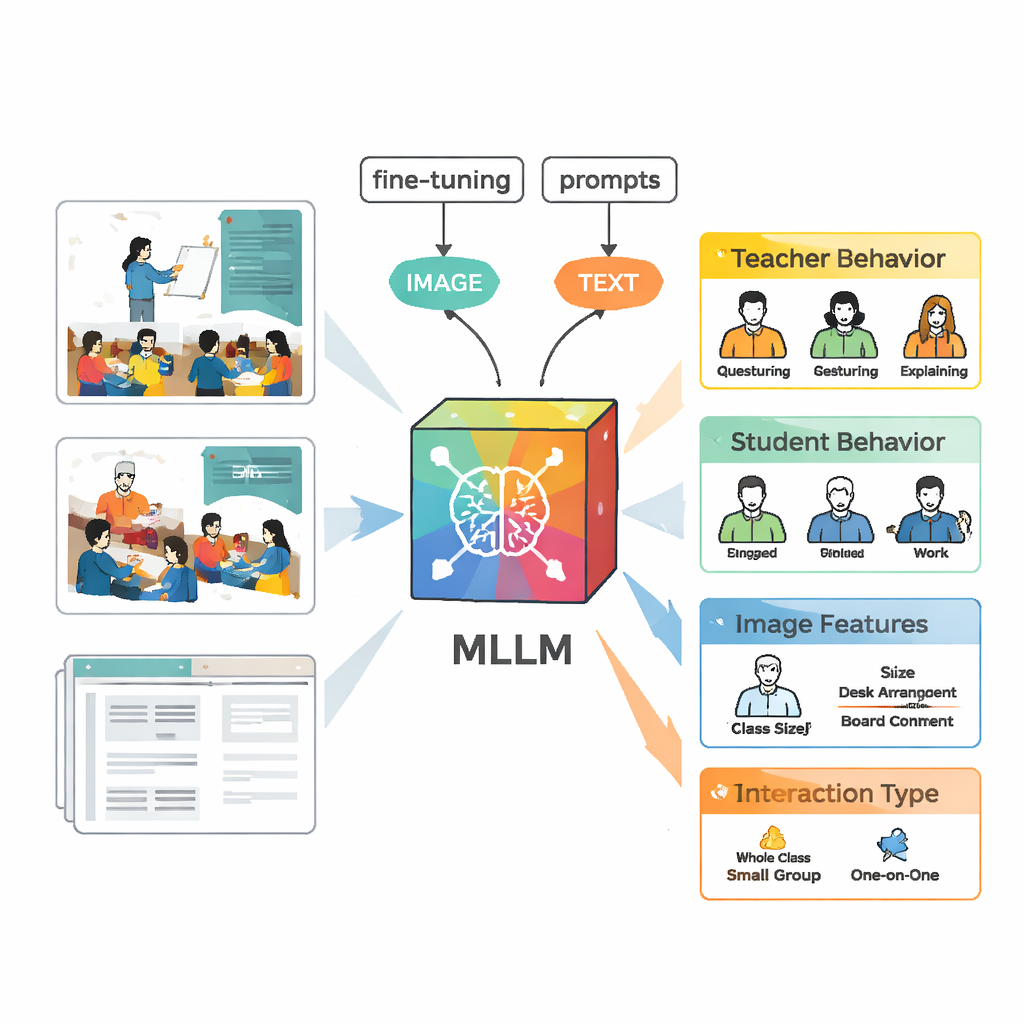
Att lära en AI att se klassrumsdynamik
För att analysera dessa scener använde teamet en multimodal stor språkmodell kallad VisualGLM‑6B, som kan ta både bilder och text som indata. Eftersom den ursprungliga modellen var tränad brett och inte specifikt på klassrum fin‑justerade forskarna den med sina uppmärkta bilder. De använde en teknik kallad LoRA som justerar endast ett litet antal av modellens interna parametrar, vilket gör träningen mer effektiv men ändå kraftfull. De utformade också noggranna prompts—strukturerade instruktioner som ber modellen beskriva lärarens beteende, elevernas beteende, visuella kännetecken och interaktionstyp i ett konsekvent format, så att utdata skulle bli enklare att jämföra med mänskliga experters bedömningar.
Bygga bättre etiketter med människor och maskiner
Att skapa en högkvalitativ träningsuppsättning krävde mer än att bara peka modellen mot videor. Först producerade VisualGLM grundläggande beskrivningar av varje bild. Mänskliga annotatörer rättade sedan fel och fyllde i saknad kontext, som vem som talade eller om eleverna lyssnade eller diskuterade. Därefter matade de in dessa polerade beskrivningar i ChatGPT, som med hjälp av specialanpassade prompts genererade strukturerade analyser enligt de fem interaktionskategorierna. Experter granskade och redigerade de AI‑genererade analyserna igen. Det slutliga resultatet blev en rik datamängd där varje bild bar en detaljerad, tillförlitlig redogörelse för vad lärare och elever gjorde.
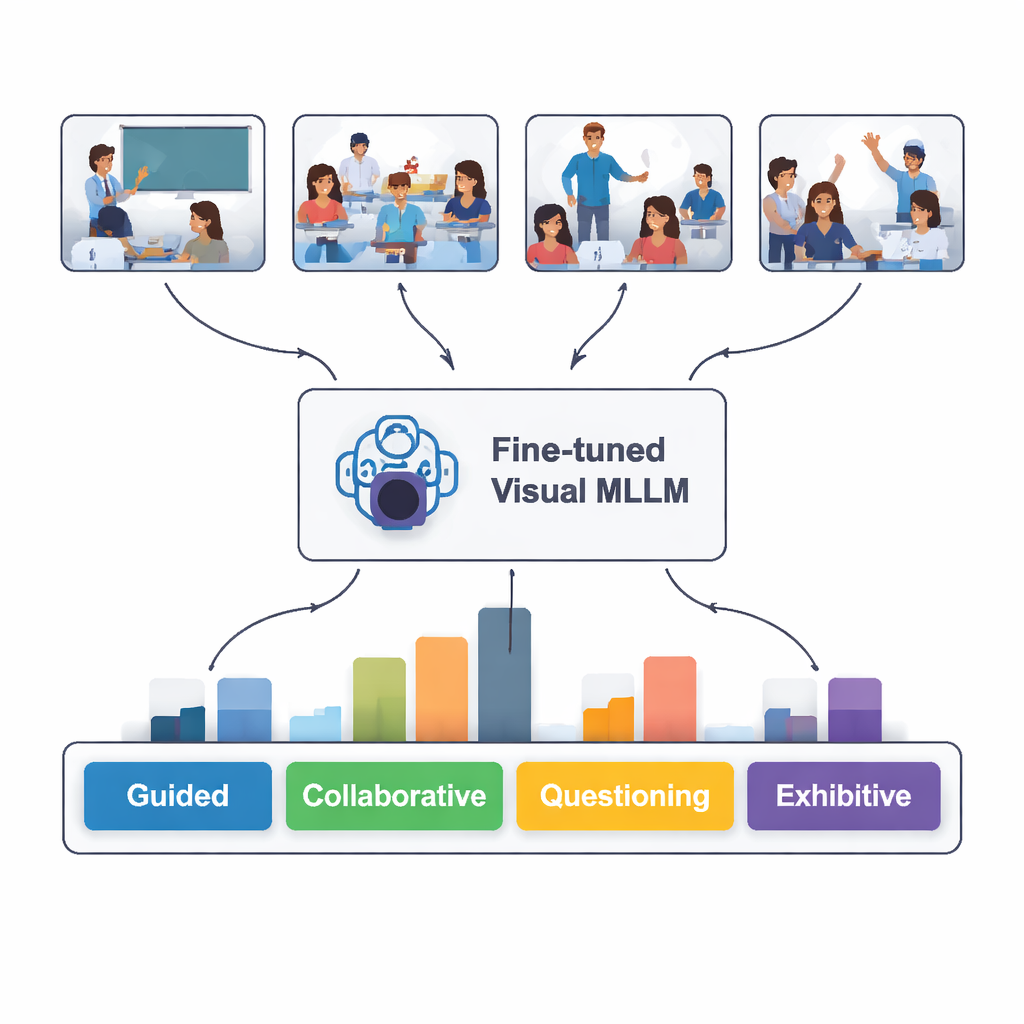
Hur väl ”läste” AI‑n klassrummet?
När den testades på 100 nya klassrumsbilder den aldrig sett tidigare identifierade den finjusterade modellen rätt interaktionstyp i 82 procent av fallen. Den presterade bäst på att känna igen guidade, självständiga och uppvisande situationer—när läraren tydligt förklarar, elever arbetar tyst på egen hand eller en elev presenterar framme. Den hade svårare med kollaborativt arbete och frågestunder, där kroppsspråk och sittordning kan vara tvetydiga även för människor. En djupare textbaserad jämförelse visade att modellens skriftliga beskrivningar ofta matchade experternas analyser ganska väl, även om den ibland ”hallucinerade” detaljer som inte fanns i bilderna eller misstolkade en subtil gest.
Vad detta betyder för framtidens klassrum
För en lekmannaläsare är huvudbudskapet att AI‑system blir kapabla att observera klassrum och sammanfatta hur undervisning och lärande utvecklas, med en struktur och konsekvens som vore svår för människor att upprätthålla över tusentals scener. Även om metoden inte är perfekt—särskilt för subtila former av diskussion och frågeställande—visar tillvägagångssättet att multimodala stora språkmodeller redan kan stödja utbildningsforskning och i förlängningen verktyg för återkoppling i klassrummet. När dessa modeller börjar inkludera ljud, gester och större, mer varierade datamängder kan de hjälpa lärare att upptäcka mönster i sin praktik som tidigare varit dolda, och erbjuda en ny lins på hur vardagliga interaktioner formar elevers lärande.
Citering: Chen, G., Han, G., Niu, J. et al. Exploring teacher-student interaction through multimodal large language models: an empirical investigation. Sci Rep 16, 7602 (2026). https://doi.org/10.1038/s41598-026-38626-0
Nyckelord: interaktion lärare‑elev, klassrumsanalys, multimodal AI, utbildningsteknologi, stora språkmodeller