Clear Sky Science · sv
Intelligent inkrementell klassificering med ett dynamiskt gräshoppeförstärkt neuralt nätverk för dataströmmar
Varför ständigt föränderliga data spelar roll
Från elnät och fabriker till onlinetransaktioner producerar moderna system data varje sekund. Dolda i dessa kontinuerliga dataströmmar finns tidiga varningssignaler om utrustningsfel, cyberattacker eller kommande prisökningar. Utmaningen är att denna informationsström aldrig tar slut och att dess beteende förändras över tid. Artikeln som sammanfattas här presenterar ett nytt sätt att träna neurala nät så att de kan fortsätta lära av sådana live-data utan att bli långsamma eller tappa noggrannhet, vilket gör dem mer användbara för övervakning och beslutsfattande i verkliga miljöer.
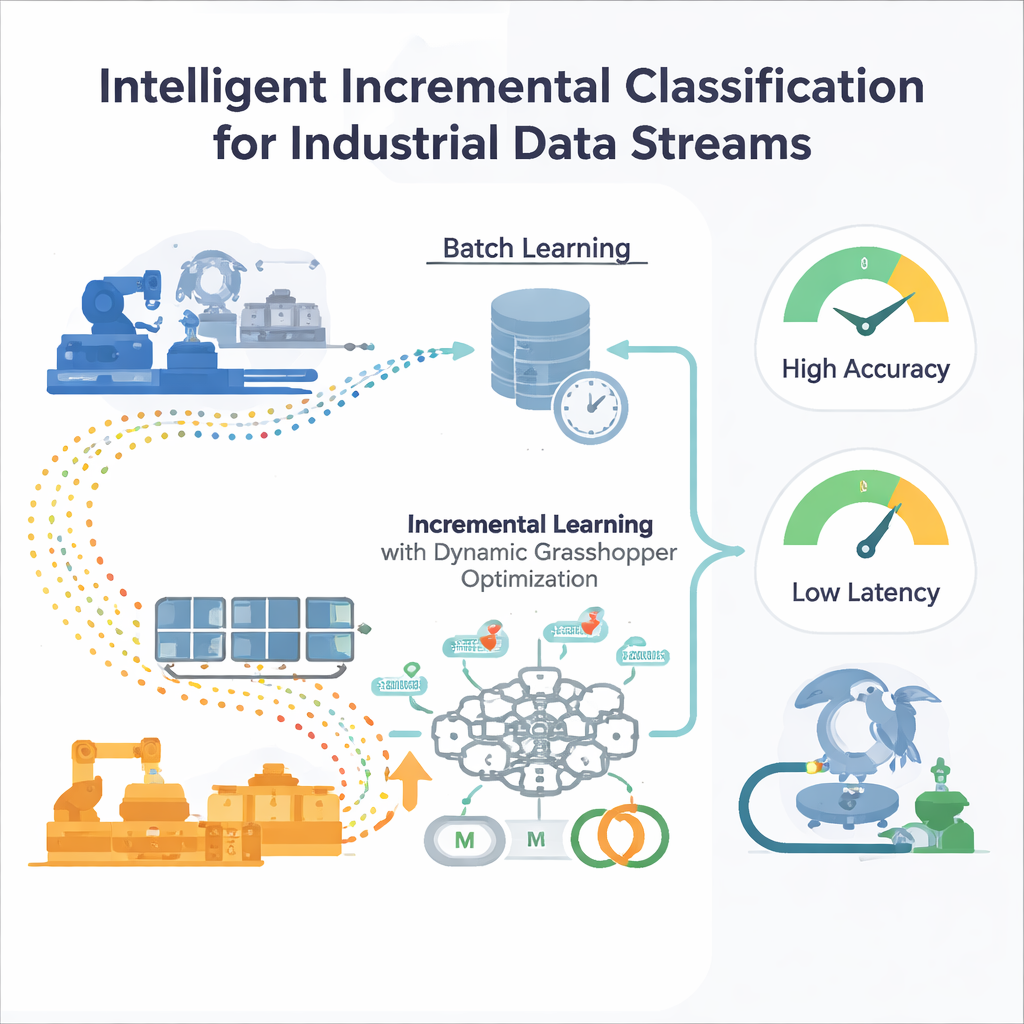
Begränsningarna med engångsträning
De flesta traditionella maskininlärningsmodeller tränas i ”batcher”: ingenjörer samlar in en stor historisk datamängd, finjusterar modellen och sedan distribuerar den. Det fungerar om världen förblir någorlunda oförändrad. Men i industriella miljöer driver villkoren—efterfrågemönster förändras, sensorer åldras, marknader fluktuerar. En modell frusen i tiden blir gradvis blind för nya mönster, och att träna om den från början på ständigt växande dataset är kostsamt och långsamt. Standardmetoder för automatisk justering, som grid search eller evolutionära algoritmer, antar också fast data, vilket innebär att de måste startas om när datadistributionen skiftar—något som är opraktiskt för system som alltid måste vara igång.
Ett neuralt nät som lär i realtid
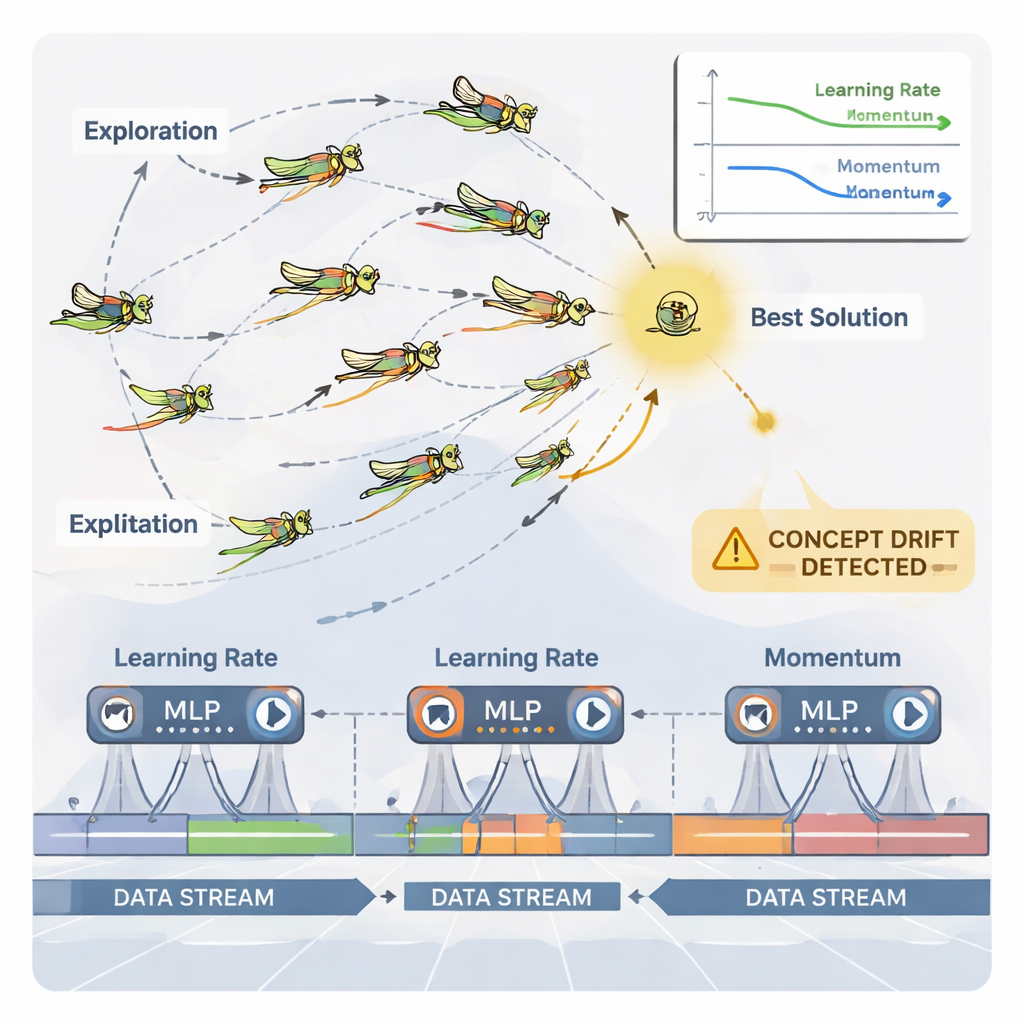
Författarna föreslår en inkrementell läranderam byggd kring en multilagerperceptron (MLP), en vanlig typ av neuralt nätverk. Istället för att mata nätet med all historisk data på en gång delas den inkommande dataströmmen upp i hanterbara fönster. Varje nytt fönster blir ett litet träningssteg som uppdaterar nätverkets interna vikter och sedan kastas bort—en ”train-and-forget”-strategi som håller minnesanvändningen låg. Avgörande är att systemet inte förlitar sig på fasta träningsinställningar. Två viktiga reglage som styr lärandets beteende—inlärningshastighet (hur stora uppdateringarna är) och momentum (hur jämnt uppdateringarna rör sig)—justeras kontinuerligt i takt med att strömmen utvecklas, så modellen kan vara lyhörd utan att bli instabil.
Gräshoppor som smarta parameterjusterare
För att hantera denna kontinuerliga anpassning använder artikeln en naturinspirerad optimerare kallad Dynamic Grasshopper Optimization Algorithm (DGOA). Föreställ dig en svärm av virtuella gräshoppor som utforskar möjliga kombinationer av inlärningshastighet och momentum. I början rör de sig vida för att söka bra regioner; senare förfinar de sina rörelser för att slipa på lovande val. I denna dynamiska variant ändras deras steglängd och attraktionskraft mot den bästa lösningen över tid baserat på hur väl det neurala nätverket presterar. Systemet övervakar också för ”concept drift”—plötsliga förändringar i prediktionsfel eller i själva datan. När en drift upptäcks återställs vissa gräshoppor och deras steg blir tillfälligt större, vilket tillåter optimeraren att snabbt söka i nya områden och lämna inaktuella inställningar bakom sig.
Metoden satt på prov
Forskarna utvärderade sitt tillvägagångssätt på en verklig dataset från den australiska elmarknaden, där målet var att förutsäga om priser skulle stiga eller falla. Jämfört med vanliga justeringsmetoder som grid search, random search, particle swarm optimization, genetiska algoritmer, ant colony optimization och den standardiserade gräshoppsalgoritmen uppnådde den dynamiska varianten i kombination med inkrementellt lärande högst noggrannhet (cirka 89,5%) samtidigt som den använde mindre beräkningstid och färre iterationer. Ytterligare experiment visade att metoden anpassar sig bättre till både stabila och föränderliga dataströmmar, skalar från tusentals till miljarder prover samtidigt som minnet hålls i schack, och presterar konkurrenskraftigt på uppgifter som prediktivt underhåll, anomalidetektion och bedrägeribekämpning, liksom på standardiserade matematiska optimeringsbenchmarks.
Vad detta betyder i praktiken
För icke-experter är slutsatsen att detta arbete erbjuder ett sätt att hålla neurala nät ”levande” och väljusterade i miljöer där data aldrig upphör och förhållanden ständigt skiftar. Istället för att upprepade gånger stoppa systemet för att bygga om modeller från grunden låter den föreslagna ramen ett lätthanterligt nät uppdatera sig fönster för fönster, medan en svärmbaserad optimerare kontinuerligt finjusterar hur snabbt och hur jämnt det lär sig. Resultatet är snabbare anpassning till nya mönster, bättre långsiktig noggrannhet och effektivare användning av beräkningsresurser—nyckelingredienser för tillförlitligt beslutsfattande i realtid inom sektorer som energi, produktion och finans.
Citering: Darwish, S.M., El-Shoafy, N.A. Intelligent incremental classification using a dynamic grasshopper-enhanced neural network for data streams. Sci Rep 16, 7730 (2026). https://doi.org/10.1038/s41598-026-38571-y
Nyckelord: dataströmmar, inkrementellt lärande, neurala nätverk, hyperparameteroptimering, svärmintelligens