Clear Sky Science · sv
En tolkbar maskininlärningsmodell som använder rutinmässiga kliniska data för tidig återfallsprognos vid hepatocellulärt karcinom
Varför detta är viktigt för patienter och familjer
För personer som genomgår operation för att avlägsna levercancer är en av de viktigaste frågorna: ”Kommer cancern att komma tillbaka snart?” I dag kan läkare bara erbjuda grova uppskattningar, ofta baserade på breda stadieindelningar som behandlar många olika patienter som om de vore lika. Denna studie presenterar ett nytt sätt att använda information som sjukhusen redan samlar in — rutinmässiga blodtester och röntgenfynd — tillsammans med tolkningsbar artificiell intelligens för att ge varje patient en klarare, mer personlig bild av deras kortsiktiga risk att cancern återkommer.
En vanlig cancer med en seg återfallsfrekvens
Hepatocellulärt karcinom är den vanligaste typen av primär levercancer och en betydande orsak till cancerdöd i världen. Även när kirurger tar bort synliga tumörer fullständigt ser mer än 70 % av patienterna sjukdomen återkomma inom fem år. Tidigt återfall — inom cirka två år efter operation — är särskilt oroande eftersom det ofta speglar aggressiva cancerceller som redan spridit sig i levern, och det försämrar överlevnaden kraftigt. Befintliga kliniska stadieindelningar, såsom TNM eller Barcelona Clinic Liver Cancer (BCLC), kan ungefärligen sortera patienter i breda kategorier men misslyckas ofta med att exakt identifiera vilka som verkligen har hög risk för ett tidigt återfall.
Att omvandla vardagliga testresultat till en riskpoäng
Forskarna använde registerdata från 1 120 patienter som genomgått till synes kurativ leveroperation vid två stora sjukhus i Kina mellan 2014 och 2024. De fokuserade endast på information som fanns tillgänglig före operationen: ålder och kön, bilddiagnostiska drag som storleken på den största tumören och om det fanns flera tumörer, samt ett brett panel av standardlaboratorietester utförda dagarna före operationen. Utifrån dessa screenades nio nyckelprediktorer kopplade till återfallsrisken. Istället för att förlita sig på en enda matematisk formel kombinerade de tre olika maskininlärningsmetoder och medelvärdesbildade deras utdata till en riskpoäng mellan 0 och 1. Patienterna grupperades sedan i låg-, medel- och hög-riskkategorier baserat på denna poäng. 
Överträffar standardiserade stadieindelningar
För att testa modellens prestanda utvärderade teamet den först i en ”hold-out”-grupp från det ursprungliga sjukhuset och därefter i en oberoende grupp från det andra sjukhuset. I båda sammanhangen var den nya modellen tydligt bättre än traditionella stadieindelningar vad gäller att skilja dem som skulle förbli fria från cancer och dem som skulle få återfall inom 24 månader. I den interna testgruppen var modellens noggrannhet över tid, mätt med ett standardmått kallat area under kurvan, cirka 0,76, jämfört med ungefär 0,55 till 0,64 för vanliga stadieringsmetoder. Personer i hög-riskgruppen hade sämst återfallsfri överlevnad, de i medel-riskgruppen hade ungefär 60 % lägre risk för återfall, och de i låg-riskgruppen hade ungefär 90 % lägre risk än hög-riskgruppen. Dessa starka skillnader stod sig även i det externa sjukhuset och var konsekventa över de flesta undergrupper, såsom yngre och äldre patienter, män och kvinnor, samt dem med stora eller små tumörer.
Öppnar den svarta lådan i artificiell intelligens
En vanlig kritik mot maskininlärning inom medicin är att den fungerar som en svart låda: den kan prediktera väl, men även specialister kan ha svårt att förstå varför. För att hantera detta använde författarna en metod kallad SHapley Additive exPlanations, eller SHAP, som bryter ned varje prediktion i bidrag från varje ingångsfaktor. Analysen visade att tumörstorlek var den enskilt starkaste drivkraften för högre risk i samtliga tre algoritmer, följt av faktorer som antalet tumörer och blodbaserade indikatorer på leverfunktion och inflammation. Intressant nog tenderade blodkloridnivå att trycka riskbedömningen åt motsatt håll och fungerade som en skyddande faktor i denna datamängd. För enskilda patienter kan modellen generera enkla stapelgrafikexempel som visar hur till exempel en stor tumördiameter och ogynnsamma blodmarkörer skjuter upp riskpoängen, medan bättre leverfunktion drar ner den. 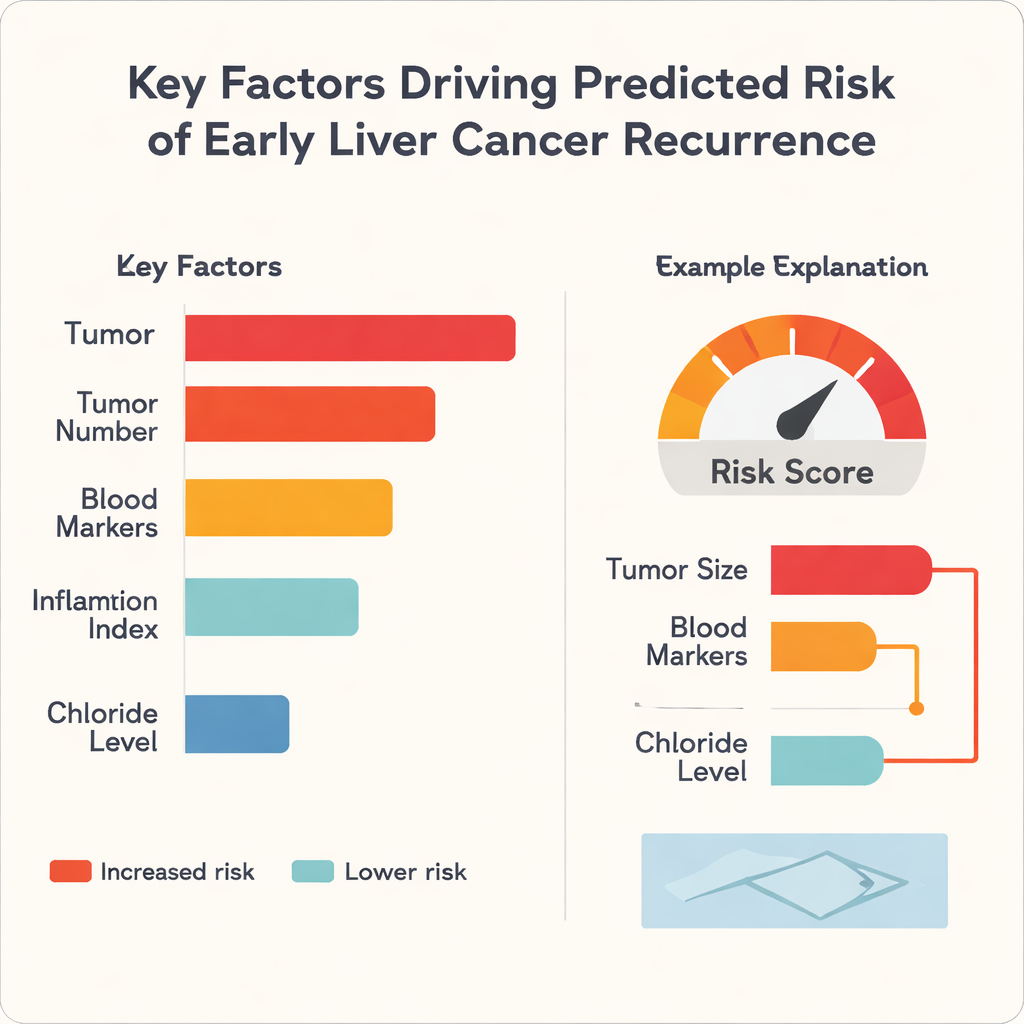
Vad detta kan innebära i kliniken
Eftersom modellen körs på data som sjukhus redan samlar in och inte kräver särskilda skanningar eller dyra genetiska tester, skulle den kunna införas i många olika vårdmiljöer, även de med begränsade resurser. Före operation kan läkare använda den för att identifiera personer som behöver tätare uppföljning eller som kan ha nytta av tilläggsbehandlingar efter operation, samtidigt som verkligt låg-risk-patienter kan undvikas onödiga tester och oro. Författarna påpekar att deras studie är retrospektiv och baserad på en specifik patientpopulation, så prospektiva prövningar i mer varierade miljöer behövs fortfarande. Ändå visar deras arbete hur transparent, förklarbar AI kan omvandla välkända laboratorievärden och röntgenfynd till meningsfulla, individualiserade prognoser som stöder gemensamt beslutsfattande mellan patienter och deras vårdteam.
Citering: Guo, DF., Wen, Q., Zhang, X. et al. An interpretable machine learning model using routine clinical data for early recurrence prediction in hepatocellular carcinoma. Sci Rep 16, 7520 (2026). https://doi.org/10.1038/s41598-026-38484-w
Nyckelord: återfall av levercancer, maskininlärningsmodell, klinisk riskprognos, tolkbar AI, hepatocellulärt karcinom