Clear Sky Science · sv
SAT: shift alignment transformer för videobrusborttagning utan flödesuppskattning
Skarpare videor från brusiga scener
Alla som försökt filma inomhus på kvällen eller med en mobil i begränsat ljus känner igen resultatet: korniga, fladdrande videor där detaljer verkar krypa och färger ser felaktiga ut. Denna artikel presenterar ett nytt sätt att rensa upp sådana videor och omvandla dem till klarare, mer stabila sekvenser utan att förlita sig på den tunga rörelsespårningsmjukvara som normalt behövs. Metoden, kallad Shift Alignment Transformer, är utformad för att bevara fina detaljer samtidigt som den är tillräckligt effektiv för att vara praktisk.
Varför videorengöring är så svårt
Att ta bort brus från ett enskilt fotografi är redan en utmaning; att göra samma sak för video är ännu svårare. Å ena sidan är varje bildruta förorenad av slumpmässiga prickar och färgskiftningar. Å andra sidan är bildrutorna kopplade över tiden: föremål rör sig, kameran skakar och detaljer dyker upp och försvinner. Traditionella metoder för videobrusborttagning har lutat sig mot att uppskatta rörelse mellan bildrutor, ofta via ett verktyg kallat optiskt flöde, som försöker spåra var varje pixel flyttar sig från en bildruta till nästa. Dessa rörelseuppskattningar kan dock lätt falla sönder när videon är extremt brusig eller rörelsen är snabb och komplex, och de tillför dessutom en stor beräkningsbörda som kan sakta ner systemen avsevärt.
En ny metod för att aligna utan spårning
I stället för att uttryckligen försöka följa varje pixel tar Shift Alignment Transformer (SAT) en annan väg: den låter nätverket implicit upptäcka hur bildrutorna relaterar till varandra genom att försiktigt skifta och jämföra features. Modellen bygger på en modern arkitektur känd som Transformer, som är skicklig på att hitta långsiktiga samband i data. Inom detta ramverk introducerar författarna en Spatial-Temporal Shift Module som varsamt rör om information både över tid och i rummet. I tidsdimensionen skiftar modellen cykliskt bildruteegenskaper så att varje lager gör att varje bildruta kan ”se” längre in i det förflutna och framtiden. I rummet delas features upp i många små grupper som knuffas i olika riktningar. Denna kombination efterliknar effektivt hur objekt kan röra sig i videon, vilket gör att nätverket kan aligna information från olika bildrutor utan att någonsin beräkna ett explicit rörelsefält.
Hur de nya byggstenarna fungerar
För att utnyttja dessa skift maximalt utformar författarna ett särskilt attention-block som blandar information inom och mellan bildrutor. Först samlas de skiftade features från intilliggande rutor och jämförs genom en cross-attention-operation: modellen lär sig vilka regioner i andra rutor som bäst stödjer den aktuella rutan på varje plats. Samtidigt fokuserar en separat attention-operation på relationer inom varje enskild ruta och förstärker lokal struktur och textur. Dessa två strömmar slås sedan ihop och passerar enkla bearbetningslager i ett mångskaligt U-format nätverk som går från grov till fin upplösning och tillbaka. Denna uppbyggnad låter systemet hantera både stora kamerarörelser och mycket små detaljer som tunna kanter eller små mönster, och bygger gradvis upp en ren version av varje bildruta.
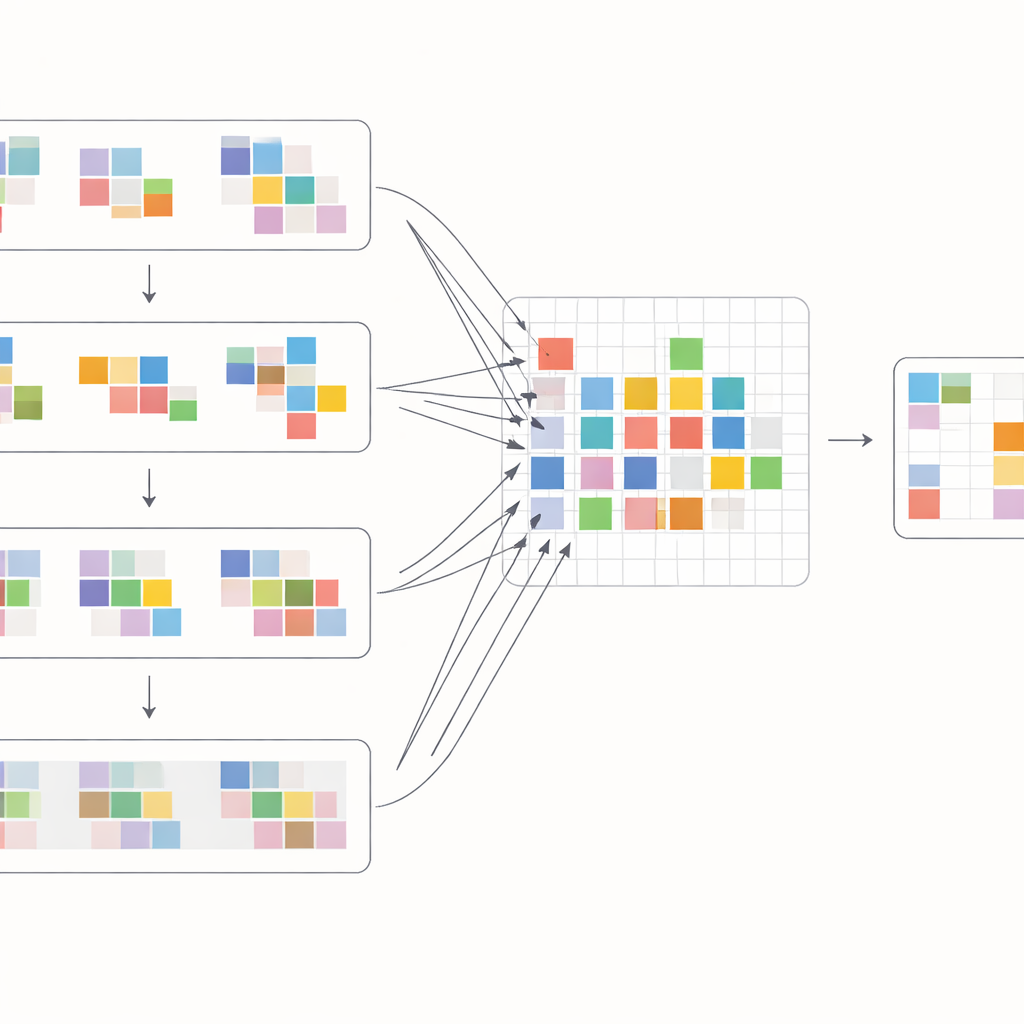
Hur väl det fungerar i praktiken
Forskarna testar sitt tillvägagångssätt på två krävande benchmarkar. Den första involverar rena videor som artificiellt förorenas med olika nivåer av slumpbrus, vilket låter dem mäta exakt hur nära de återställda rutor kommer originalen. Här matchar eller överträffar den nya metoden konsekvent kvaliteten hos tidigare konvolutionella och rekurrenta nätverk, och kommer nära de bästa befintliga transformerbaserade modellerna samtidigt som den använder mindre beräkningar. Den andra benchmarken använder verkliga inspelningar från bildsensorer i svagt ljus, där bruset är ojämnt, färgat och mycket svårare att förutsäga. På detta mer realistiska test presterar Shift Alignment Transformer tydligt bättre än tidigare state-of-the-art-metoder, och producerar videor som ser renare, skarpare och mer stabila över tid ut, med färre färgskiftningar och färre kvarvarande artefakter.
Vad detta betyder för framtida videoverktyg
Enkelt uttryckt visar författarna att det är möjligt att effektivt brusrensa videor utan att uttryckligen spåra rörelse, genom att kombinera smarta skift i tid och rum med attention-baserad featurematchning. Deras Shift Alignment Transformer erbjuder en stark balans mellan noggrannhet och effektivitet, särskilt för verkliga svagt ljus-situationer där traditionell rörelseuppskattning är bräcklig. När attention-baserade modeller blir mer effektiva kan metoder som denna hitta in i vardagliga kameror och strömningstjänster och hjälpa till att förvandla brusiga, svåra att se klipp till jämna, skarpa videor med minimalt krångel för användaren.
Citering: Zhang, X., Fan, S., Zhang, H. et al. SAT: shift alignment transformer for video denoising without flow estimation. Sci Rep 16, 8207 (2026). https://doi.org/10.1038/s41598-026-38431-9
Nyckelord: videobrusborttagning, transformer, bildbrus, video i svagt ljus, datorseende