Clear Sky Science · sv
Förfrågnings-effektiv beslutsbaserad adversarial attack med låg förfrågningsbudget
Varför små störningar i bilder kan lura intelligenta maskiner
Modern artificiell intelligens kan känna igen ansikten, djur och vardagsföremål med imponerande noggrannhet. Ändå kan samma system luras av förändringar i en bild som är så små att människor knappt ser dem. Denna artikel undersöker ett nytt sätt att skapa sådana ”luring”-bilder samtidigt som man ställer så få frågor som möjligt till AI:n, vilket blottlägger både hur bräckliga dagens modeller kan vara och hur angripare skulle kunna utnyttja dem i verkliga situationer.
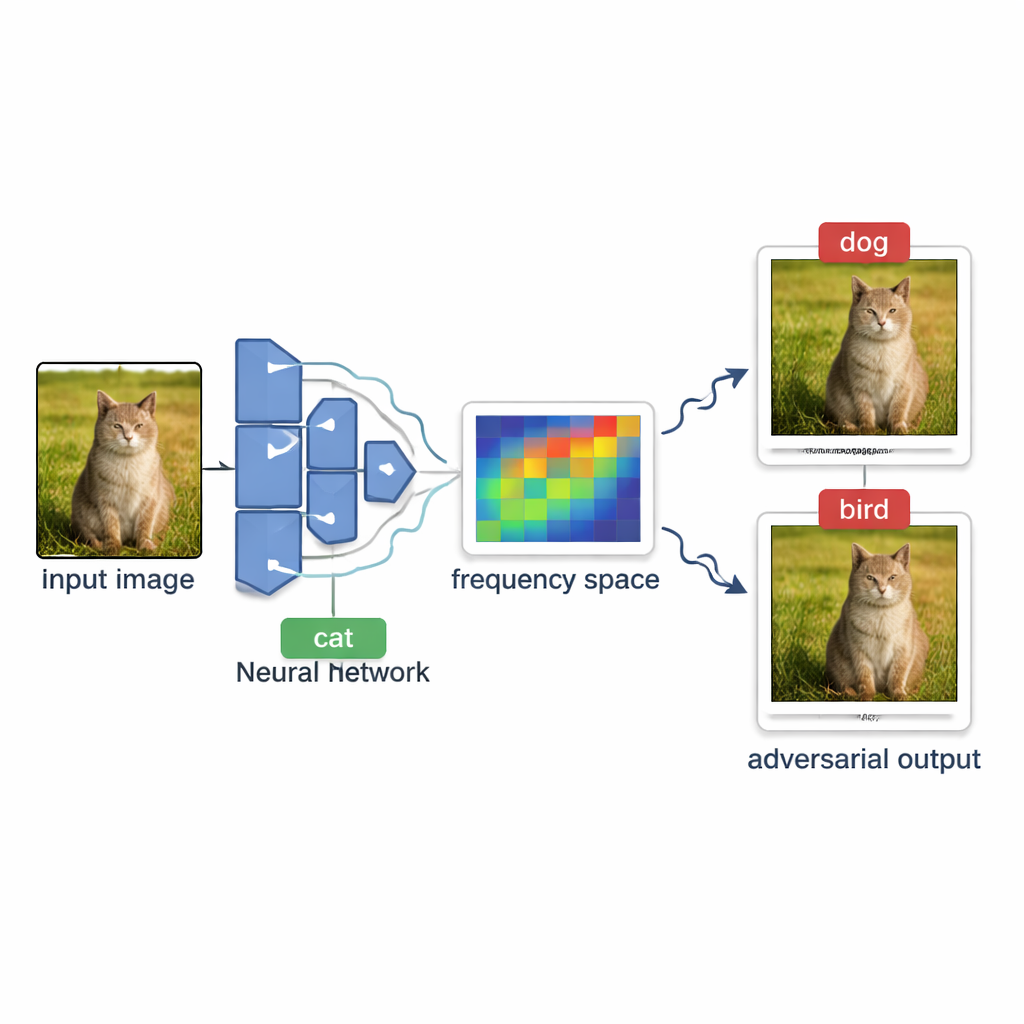
Hur angripare sonderar AI-system från utsidan
I många verkliga tjänster—som automatisk fotomärkning eller innehållsfilter—uppträder modellen som en svart låda. Utomstående kan ladda upp en bild och bara se den slutliga etiketten, exempelvis ”hund” eller ”stoppskylt”, men aldrig de interna konfidenspoängen eller modellens struktur. Att skapa en vilseledande bild under dessa villkor kallas en beslutsbaserad black-box-attack. Utmaningen är att försiktigt skruva på en normal bild tills modellen etiketterar fel, utan att kunna se hur ”nära” modellen är att ändra sig och utan att skicka så många testbilder att systemet märker det eller att förfrågningarna blir för kostsamma.
Ett nytt sätt att söka med mycket få frågor
Författarna introducerar OPOQA (One Plane One Query Attack), en metod utformad för att vara sparsam med förfrågningar samtidigt som den skapar högkvalitativa adversariala bilder. Istället för att upprepade gånger prova längs en enda gissad riktning arbetar OPOQA i omgångar. I varje omgång utgår den från en redan vilseledande bild och den ursprungliga rena bilden, och föreslår sedan flera nya kandidatbilder som ligger i noggrant valda riktningar. Avgörande är att varje riktning provas högst en gång, vilket frigör den begränsade förfrågningsbudgeten för att utforska många fler möjligheter istället för att överförfina en enstaka gissning.
Rida på bildens mjuka vågor
För att välja lovande riktningar lutar OPOQA sig mot idén att de mest effektiva, svårupptäckta förändringarna ofta är jämna, breda skift snarare än skarp pixelbrus. Metoden använder ett matematiskt verktyg kallat diskret cosinustransform för att flytta bilden till en ”frekvens”-vy, där långsamma, mjuka variationer samlas i ett kompakt område. Den slumpmässigt provtar några av dessa lågfreventa komponenter, omvandlar dem tillbaka till vanliga pixeländringar och använder dem som grundläggande riktningar för utforskning. Varje provad riktning hjälper till att definiera en plan tvådimensionell yta som förbinder originalbilden, den nuvarande adversariala bilden och en ny kandidat. På var och en av dessa ytor väljer OPOQA en enda punkt att testa, i balans mellan två mål: komma närmare originalbilden samtidigt som man fortfarande sannolikt pressar modellen till ett felaktigt beslut.

Välja bästa kandidat och anpassa i farten
När OPOQA har genererat en liten uppsättning kandidatbilder mäter den hur långt varje bild ligger från originalet och sorterar dem från minst till mest förändrad. Därefter förfrågar den modellen i den ordningen. I samma ögonblick som den hittar en kandidat som modellen klassificerar fel, upphör den och behandlar den bilden som ny utgångspunkt för nästa omgång. Om ingen av kandidaterna lyckas lura modellen behåller OPOQA den tidigare bästa adversariala bilden men justerar en intern ratt som styr hur konservativ eller aggressiv nästa uppsättning steg ska vara. Denna ”giriga” strategi—att alltid acceptera den bästa tillgängliga felklassificerade bilden och dynamiskt finjustera stegstorleken—låter attacken nollställa på subtila, effektiva störningar utan att slösa förfrågningar på ointressanta riktningar.
Vad experimenten avslöjar om AIs svagheter
Forskarlaget testade OPOQA på 200 bilder från det storskaliga ImageNet-benchmarket och sex mycket använda neurala nätverksmodeller, inklusive Inception-v3, ResNet, VGG, DenseNet och vision-transformers. Under en strikt gräns på 1 000 modellförfrågningar per bild matchade eller överträffade OPOQA flera ledande attackmetoder. Till exempel lurade den Inception-v3 i 94 procent av bilderna samtidigt som förändringarna hölls så små att de nästan var osynliga för mänskliga ögon, vilket förbättrade den tidigare bästa metoden med flera procentenheter. Över modellerna tenderade OPOQA att nå höga framgångsgrader tidigare—med färre förfrågningar—även om vissa konkurrerande metoder kom i kapp eller passerade när de gavs mycket stora förfrågningsbudgetar och tid för finjustering.
Vad detta innebär för vardaglig AI-säkerhet
Studien visar att dagens visionsystem kan luras även när angripare endast ser slutgiltiga beslut och har begränsade möjligheter att sondera modellen. Genom att smart utforska mjuka, lågfrekventa förändringar och noggrant ransonera varje förfrågan kan OPOQA skapa bilder som ser likadana ut för människor men leder maskiner snett. För icke-experter är slutsatsen att AI:s ”seende” fortfarande är relativt bräckligt: det kan knuffas ur kurs på subtila sätt som är svåra att upptäcka. Att känna igen och studera sådana effektiva attacker är ett viktigt steg mot att härda verkliga system—som övervakningskameror, medicinska bildverktyg och autonoma fordon—mot manipulation som annars kan gå oupptäckt.
Citering: Tuo, Y., Yin, M. & Che, S. Query-efficient decision-based adversarial attack with low query budget. Sci Rep 16, 6886 (2026). https://doi.org/10.1038/s41598-026-38428-4
Nyckelord: adversariala exempel, black-box-attacker, säkerhet för djupinlärning, bildklassificering, förfrågnings-effektiv attack