Clear Sky Science · sv
MDI‑YOLO: en lättviktsmodell för multidimensionell funktionsfusion baserad på transformer‑CNN för detektion av små objekt
Skarpare blick från ovan
Från trafikövervakning till katastrofinsatser håller drönare och satelliter i allt högre grad uppsikt över vår värld. Men de saker vi oftast bryr oss mest om i dessa bilder — små bilar, människor, båtar och flygplan — visas ofta bara som ett fåtal pixlar. Artikeln om MDI‑YOLO tar itu med en enkel men avgörande fråga: hur kan datorer pålitligt hitta dessa pyttesmå objekt i realtid, även på låg‑effekt enheter som bärs av drönare?
Varför små objekt är svåra att upptäcka
I flyg‑ och satellitbilder är intresseobjekten vanligtvis mycket små, ofta tätt packade och delvis dolda av byggnader, träd eller skuggor. Standarddetektorer ställs inför en avvägning: lättviktiga modeller körs snabbt på kant‑enheter som omborddatorer i drönare men missar många små mål; tyngre, mer precisa modeller är för långsamma och resurskrävande för praktiskt bruk i fält. Små objekt tenderar också att smälta in i komplexa bakgrunder — tänk grå bilar på grå vägar — så deras karakteristiska drag kan lätt försvinna när bilder komprimeras och bearbetas av djupa nätverk.
En ny blandning av global och lokal syn
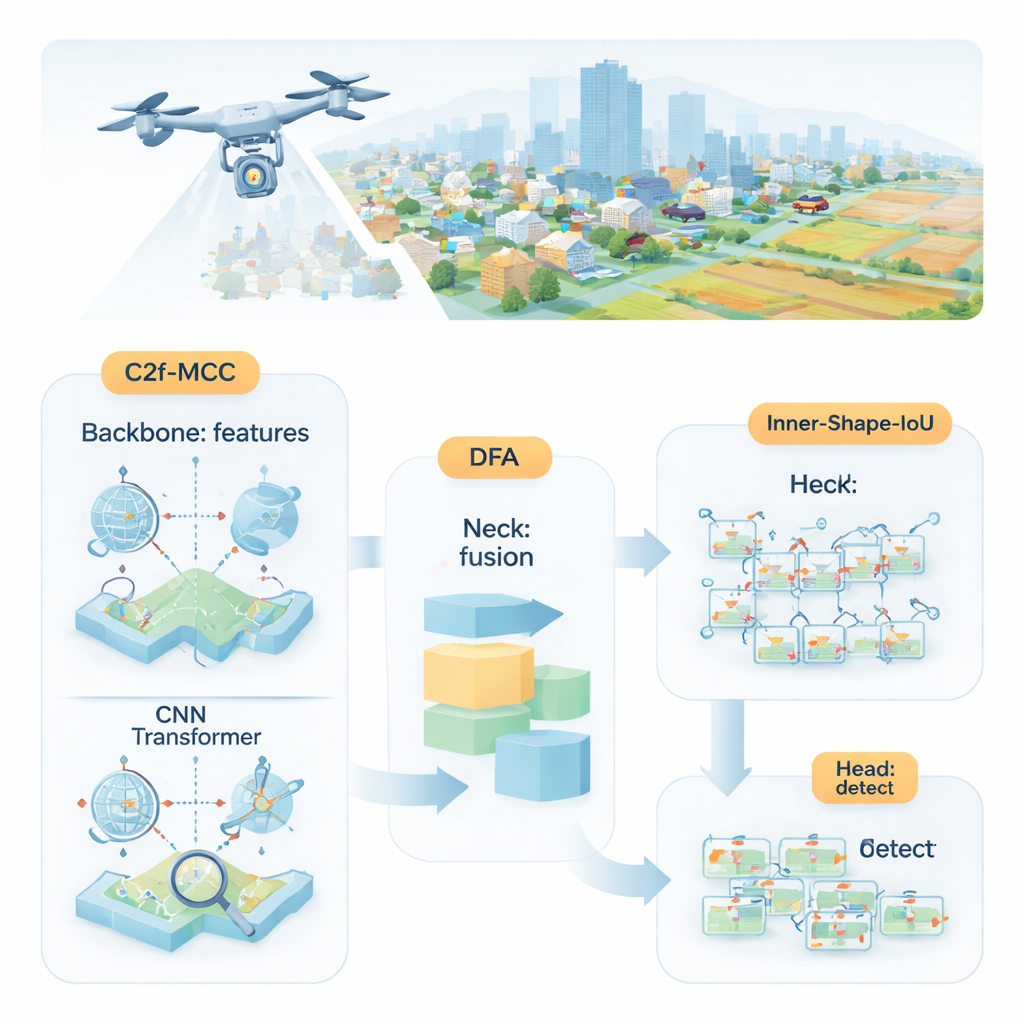
Forskarna föreslår MDI‑YOLO, en omdesignad version av den populära YOLOv8‑detektorn som håller modellen kompakt samtidigt som dess förmåga att hitta pyttesmå mål skärps. I kärnan finns en ny byggsten kallad C2f‑MCC, som delar upp den visuella informationen i nätverket i två vägar. Den ena vägen använder transformer‑liknande bearbetning, vilket är bra på att fånga långräckviddsrelationer i hela bilden — till exempel hur en pixelklump passar in i en större väg eller landningsbana. Den andra vägen håller sig till klassiska konvolutionsfilter, som utmärker sig på att plocka ut lokala detaljer som kanter och texturer. Genom att gruppera kanaler och skicka endast en del av datan genom den tyngre transformer‑vägen får modellen global kontext utan att växa sig stor eller bli långsam.
Hjälper nätverket att fokusera på det som betyder något
Även med bättre byggstenar måste nätverket ändå avgöra var det ska rikta uppmärksamheten. För att vägleda detta introducerar författarna en mekanism de kallar Directional Fusion Attention (DFA). Denna modul ser mönster längs bildens bredd- och höjdled samt en övergripande sammanfattning av scenen, och lär sig hur olika regioner och funktionskanaler ska viktas. I praktiken uppmuntrar DFA modellen att koncentrera sig på sannolika objektområden — såsom fordonsformade fläckar på vägar — och tona ner repetitiva eller förvillande bakgrundstexturer. Denna kombinerade spatiala och kanalbaserade fokus gör det lättare att separera små mål från röriga omgivningar eller bakgrundsregioner med liknande utseende.
Ritar snävare rutor runt pyttesmå mål
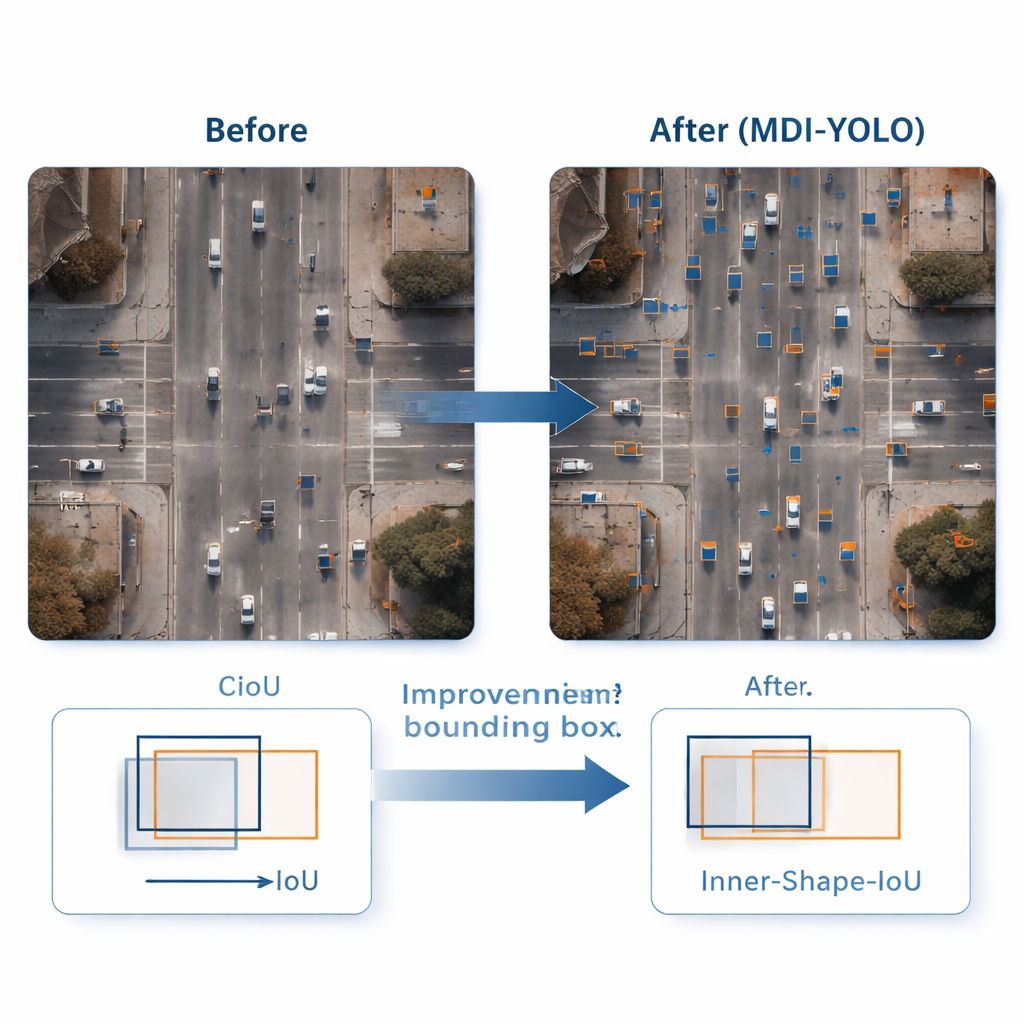
Att upptäcka ett objekt är bara halva jobbet; detektorern måste också precis markera dess omkrets. Standardträning jämför förutsagda rektanglar med de sanna med ett "överlapps"-mått, men detta kan vara okänsligt när objekten är små eller oregelbundet formade. Författarna utformar en ny förlustfunktion, Inner‑Shape‑IoU, som bedömer rutor inte bara efter hur mycket de överlappar, utan också efter hur väl deras form, storlek och centrala region stämmer överens med det verkliga objektet. Genom att kombinera två kompletterande mått bestraffas rutor som bara matchar kanterna men missar kärnan i målet, vilket leder till mer precisa avgränsningar — särskilt för små, tätt packade eller långsträckta objekt.
Påvisade förbättringar utan extra tyngd
För att testa MDI‑YOLO körde teamet experiment på två krävande publika benchmarks: VisDrone2019, med drönarbilder från städer och trafik, och DOTAv1.0, en stor samling flygbilder med många små, tätt packade objekt. Utan att förlita sig på förtränade modeller förbättrade MDI‑YOLO standardmått för noggrannhet med flera procentenheter över grundmodellen YOLOv8 samtidigt som antalet parametrar förblev i stort sett oförändrat och inferenstiderna förblev snabba. Jämfört med en rad populära detektorer — från lättviktiga YOLO‑varianter till tyngre transformer‑baserade system — erbjöd den en sällsynt kombination av hög noggrannhet, låg beräkningskostnad och robusthet över olika scenarier.
Vad detta betyder i praktiken
För icke‑specialister är slutsatsen att MDI‑YOLO ger drönare och fjärranalysystem skarpare, mer pålitliga "ögon" utan att kräva stora, strömkrävande datorer. Genom att smart blanda global kontext, lokal detalj, riktad uppmärksamhet och ett mer kräsnt sätt att träna avgränsningsrutor gör metoden det lättare att upptäcka små objekt som är viktiga för säkerhet, övervakning och kartläggning. Denna typ av effektivt, högprecisionseende är ett viktigt steg mot smartare luftburna plattformar som kan agera autonomt, reagera snabbt och användas i bred skala i verkliga världen.
Citering: Shi, H., Wu, Y., Xu, Y. et al. MDI-YOLO a lightweight transformer-CNN-based multidimensional feature fusion model for small object detection. Sci Rep 16, 7233 (2026). https://doi.org/10.1038/s41598-026-38378-x
Nyckelord: dronavbildning, detektion av små objekt, fjärranalys, YOLO, datorseende