Clear Sky Science · sv
Resursallokering stödd av digitala tvillingar via generativ adversariell imitation learning i komplexa moln‑kant‑änd‑scenarier
Smartare data‑motorvägar för sakernas internet
När städer, fabriker och hem fylls med uppkopplade sensorer och enheter genereras enorma datamängder som måste bearbetas snabbt och pålitligt. Att skicka allt till avlägsna molnservrar kan bli för långsamt, medan små enheter i ”kanten” ofta saknar tillräcklig beräkningskraft. Denna artikel undersöker ett nytt sätt att automatiskt dirigera och fördela beräknings-, lagrings‑ och nätverksresurser över enheter, närliggande kantservrar och molnet – så att smarta applikationer förblir snabba och robusta även när verkliga förhållanden är stökiga och oförutsägbara.
Varför dagens metoder har svårt
Moderna system förlitar sig ofta på djup förstärkningsinlärning, där en algoritm lär sig genom trial‑and‑error med belöningssignaler från omgivningen. I komplexa, brusiga nätverk är dessa belöningar dock svåra att definiera och mäta. Om belöningsfunktionen är felaktig eller förvrängd av störningar kan systemet lära sig osäkra eller slösaktiga beteenden. Många befintliga metoder förutsätter dessutom rik förkunskap om trafikmönster och enhetsbeteenden, vilket sällan finns i drift i industriella nät. Utöver detta optimerar de flesta lösningar bara en typ av resurs åt gången — exempelvis beräkningskraft — och bortser från lagring eller nätverksbandbredd, trots att alla tre samverkar för att bestämma verklig prestanda.
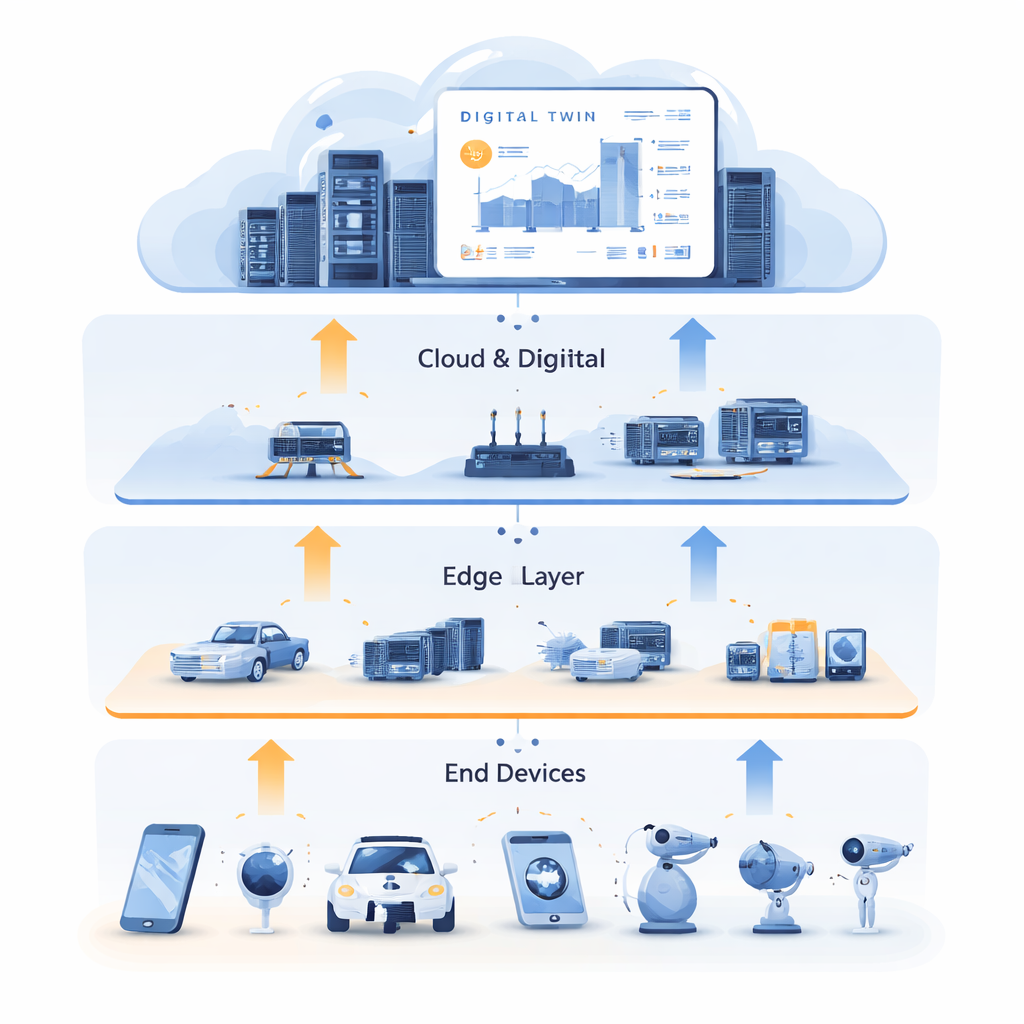
Lära från en digital tvilling
För att bryta detta dödläge kombinerar författarna resursallokering med Digital Twin‑teknik. En digital tvilling är en detaljerad virtuell replika av det fysiska nätverket, underhållen i molnet. Den speglar tillståndet hos kantservrar, länkar och uppgifter över tid, med hjälp av rik historisk data från sensorer och loggar. I detta arbete är den digitala tvillingen inte bara en instrumentpanel; den blir en träningsarena. Systemet använder tidigare data för att generera ”expert”‑exempel på goda beslut, som fångar hur uppgifter bör delas mellan beräkning och cachelagring, och var de bör bearbetas för låg fördröjning. Denna träning sker offline utan att störa live‑tjänster och utnyttjar molnets stora beräkningsresurser för att utforska många tänkbara situationer.
Imitation istället för trial‑and‑error
I stället för att lära direkt från belöningar antar den föreslagna E‑GAIL‑modellen imitation learning: agenten försöker bete sig som en expert. Först bygger författarna flera expertpolicys med en Actor–Critic‑ram förstärkt med ett NoisyNet‑lager. Genom att injicera noggrant kontrollerat brus i beslutsnätverket utsätts dessa experter för många olika förhållanden — inklusive störningar som efterliknar verklig trådlös interferens och fluktuerande arbetsbelastningar — så att deras trajektorier blir mer realistiska. Därefter förenar systemet flera enskilda experttrajektorier till en enda ”multi‑expert”‑referens med verktyg från spelteori. Genom att söka en Nash‑jämvikt mellan experterna undviks konflikter och en konsensusstrategi uppstår som täcker ett bredare spektrum av möjliga scenarier.
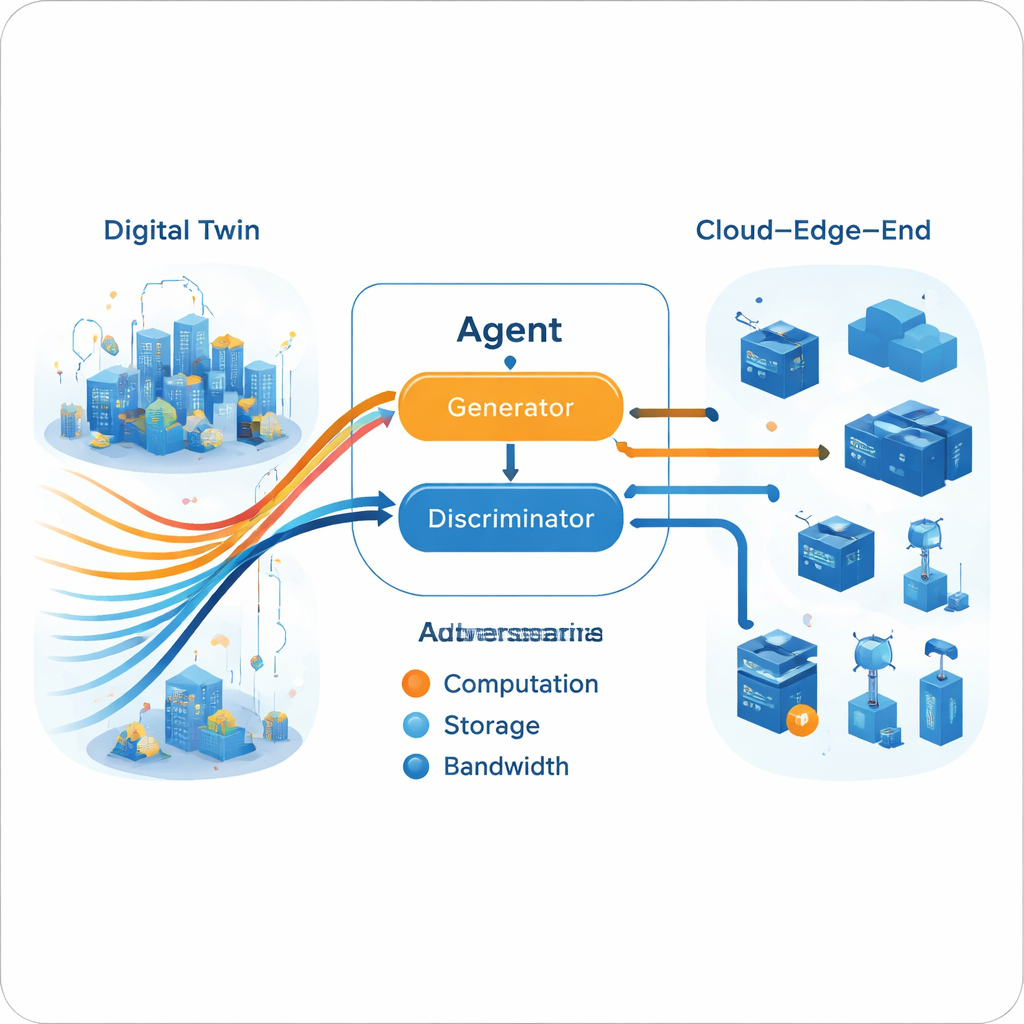
En generativ adversariell motor för beslut
När multi‑expert‑trajektorin byggts i den digitala tvillingen lär den live‑agenten sig att efterlikna den med en generativ adversariell uppsättning, liknande de nätverk som genererar bilder. En generator föreslår resursallokeringsåtgärder givet det aktuella nätverkstillståndet, medan en diskriminator försöker avgöra om en sekvens åtgärder kommer från agenten eller från experttrajektorierna. Med tiden pressar detta adversariella spel generatorn att producera beslut som diskriminatorn inte kan skilja från expertbeteende. Avgörande är att denna process inte kräver en explicit belöningsfunktion från den verkliga miljön. Träningen delas upp: tung offline‑inlärning (i molnet) förfinar experterna och generatorn, medan lättare online‑uppdateringar (vid kanten) håller modellen i fas med aktuella förhållanden och möter kantens praktiska hårdvarubegränsningar.
Hur bra fungerar det?
Författarna jämför E‑GAIL med flera populära baslinjer, inklusive djup Q‑inlärning, spelteoretisk offloading, giriga heuristiker, moln‑endast bearbetning och slumpmässig allokering. Över många experiment — med variationer i antal ändenheter, kanaler, uppgiftsblandningar, arbetsbelastningar, datastorlekar, avstånd och brusmönster — uppnår E‑GAIL konsekvent end‑to‑end‑fördröjningar mycket nära expertpolicyns och märkbart bättre än andra automatiska metoder. Den anpassar sig väl när uppgifter skiftar mellan beräkningsintensiva och lagringsintensiva, när nätverket växer eller när interferensen ökar. Den digitala tvillingen snabbar upp genereringen av experttrajektorier och förbättrar deras kvalitet, medan multi‑expert‑fusionen breddar de scenarier agenten kan hantera utan att behöva omskola från grunden.
Vad detta betyder för vardagssystem
För en icke‑specialist är huvudbudskapet att detta tillvägagångssätt låter nätverk sköta sig själva mer intelligent i osäkra förhållanden. I stället för att handkonstruera regler eller förlita sig på bräcklig trial‑and‑error‑inlärning lär sig E‑GAIL från rik, simulerad erfarenhet som levereras av en digital tvilling och från flera erfarna ”experter” vars råd försonas matematiskt. Resultatet är en resursallokerare som snabbt kan avgöra var uppgifter ska köras och var data bör lagras, och som håller svarstiderna låga även när förhållanden förändras. I framtida industriella system och smarta städer kan sådana självlärande koordinatorer tyst jonglera beräkning, lagring och bandbredd bakom kulisserna, vilket gör vår uppkopplade värld snabbare, mer tillförlitlig och mer energieffektiv.
Citering: Zhang, X., Xin, M., Li, Y. et al. DT-aided resource allocation via generative adversarial imitation learning in complex cloud-edge-end scenarios. Sci Rep 16, 7657 (2026). https://doi.org/10.1038/s41598-026-38367-0
Nyckelord: digital tvilling, edge‑datalagring, imitation learning, resursallokering, Industriella sakernas internet