Clear Sky Science · sv
Beskära trädskogsmodell och omprovtagning för problem med klassobalans
Varför sällsynta fall spelar roll i smarta förutsägelser
Många beslut som drivs av artificiell intelligens bygger på att upptäcka det sällsynta: en bedräglig kreditkortsbetalning, ett tidigt tecken på sjukdom eller ett farligt fel i en maskin. I dessa situationer är de viktiga fallen kraftigt underrepresenterade jämfört med de vanliga, och de flesta inlärningsalgoritmer tenderar att förbise dem. Den här artikeln presenterar ett sätt att få en populär metod, Random Forests, att bli mycket mer uppmärksam på dessa sällsynta men avgörande fall—samtidigt som modellen blir smalare och snabbare.
Problemet med ojämna exempel
Standardmaskininlärning fungerar bäst när data är välbalanserade—när det finns ungefär lika många exempel för varje utfall. I verkligheten dominerar dock sällsynta händelser många uppgifter. Till exempel visar bara en liten andel medicinska bilder en tumör, och bara en mycket liten andel transaktioner är bedrägliga. Denna obalans gör det lätt för en algoritm att se bra ut på papper genom att för det mesta förutsäga det vanliga utfallet, även om den upprepade gånger missar det sällsynta. När klyftan mellan vanliga och sällsynta fall växer, driver modellens beslutgräns mot majoriteten och den sällsynta klassen blir svårare att känna igen.
Väga upp med smart provtagning
Forskare försöker ofta ombalansera sådan data innan modeller tränas. Ett alternativ är att korta ner majoritetsklassen (under-sampling) genom att kassera några vanliga fall för att matcha antalet sällsynta. Ett annat är att kopiera eller generera extra sällsynta exempel (over-sampling) och därigenom öka deras närvaro utan att förlora ursprungliga data. En tredje, hybridmetod blandar båda idéerna genom att ta bort några majoritetsexempel samtidigt som minoriteten förstärks. Varje taktik har kompromisser: att korta ner riskerar att kasta bort användbar information, medan att duplicera många exempel kan göra träningen långsammare och leda till överanpassning. Författarna använder alla tre strategier för att skapa mer jämna träningsset anpassade till den aktuella datan.
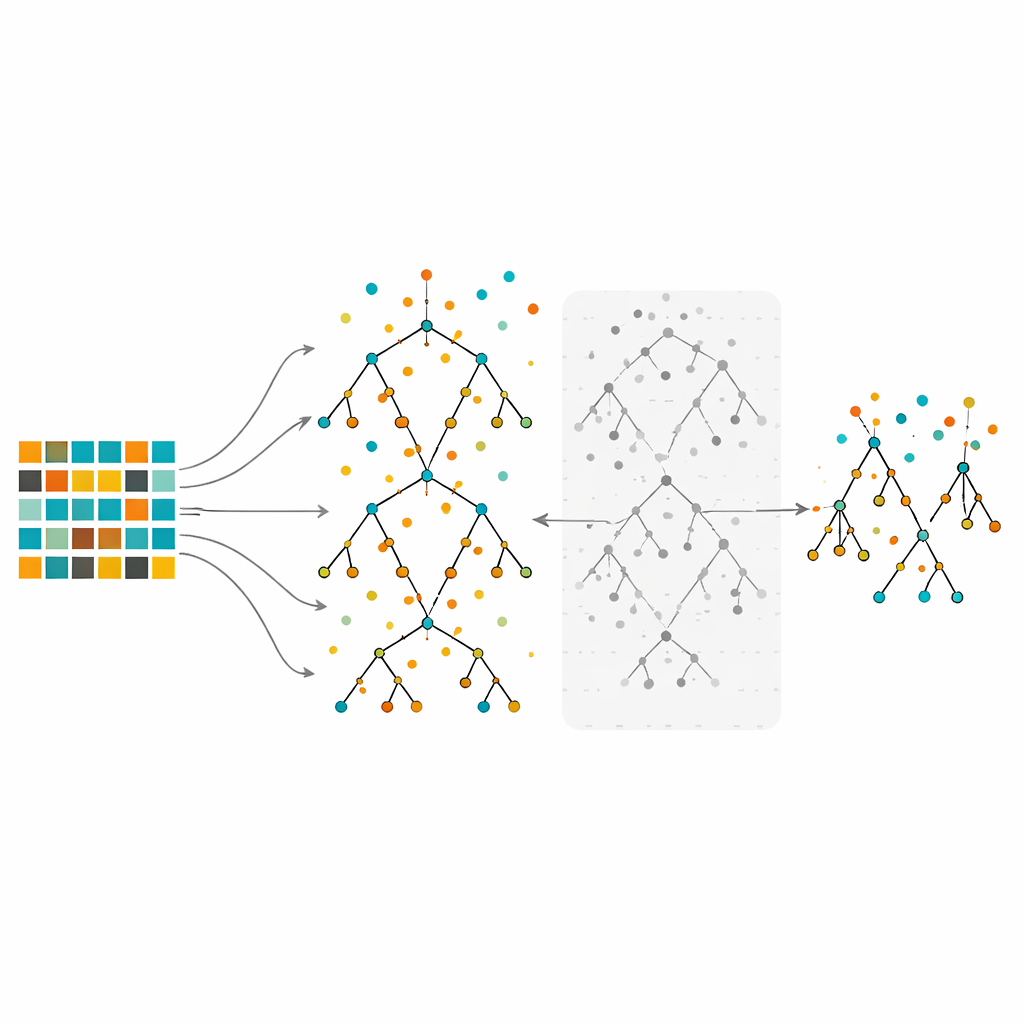
Träna och beskära en skog av beslutsträd
Studien fokuserar på Random Forests, en ensemblemetod som bygger många beslutsträd på något olika snitt av datan och sedan kombinerar deras röster. Random Forests är kända för att hantera komplex data och belysa vilka funktioner som betyder mest. Men när de tränas på starkt obalanserad data kan även stora skogar vara förskjutna mot majoritetsklassen. I den föreslagna metoden ombalanserar författarna först datan med hjälp av under-sampling, over-sampling eller deras hybrid. De växer sedan många träd med den vanliga Random Forest-proceduren, men med en viktig twist: i stället för att behålla varje träd utvärderar de varje träd med out-of-bag-observationer—datapunkter som inte användes för att växa just det trädet—och skiljer bort hälften med de sämsta felnivåerna. Detta beskärningssteg ger en mindre, mer selektiv skog byggd av de mest pålitliga träden.
Testning på många verkliga datamängder
För att se hur väl denna beskurna skog presterar testar författarna metoden på tio publikt tillgängliga datamängder som speglar ett brett spektrum av tillämpningar, från medicinska och biologiska mätningar till skräppostfiltrering och ljudklassificering. Varje datamängd har två klasser, där den ena tydligt är sällsyntare än den andra, och de varierar i storlek, antal funktioner och grad av obalans. Den nya metoden jämförs med flera väl använda tillvägagångssätt: k-närmsta grannar, ett enskilt beslutsträd, en standard Random Forest, en Balanced Random Forest-variant och support vector machines. Över olika provtagningsstrategier uppnår den beskurna skogen konsekvent lägre klassificeringsfel än alternativen på de flesta datamängder. Kombinationen av hybridprovtagning och beskärning ger de bästa övergripande resultaten, både vad gäller noggrannhet och stabil prestanda över alla tio uppgifter.
Skarpare modeller som slösar mindre kraft
Utöver noggrannhet förbättrar tillvägagångssättet också effektiviteten. Genom att klippa bort de mindre effektiva träden blir den slutliga ensemblen mindre och kräver mindre beräkning för träning och för att göra förutsägelser, utan att offra—och ofta förbättra—sin förmåga att upptäcka sällsynta fall. Statistiska tester bekräftar att vinsterna över konkurrerande metoder inte beror på slumpen. För praktiker som står inför obalanserad data visar detta arbete att noggrann ombalansering av träningssetet och sedan beskärning av en Random Forest baserat på out-of-bag-prestanda kan ge modeller som både är mer precisa och mer effektiva. I vardagstermer hjälper metoden våra algoritmer att lägga rätt uppmärksamhet vid de sällsynta men viktiga signalerna som döljer sig i ett hav av ordinära exempel.
Citering: Faiz, N., Iftikhar, S., Jan, S. et al. Pruning tree forest and re-sampling for class imbalanced problem. Sci Rep 16, 8087 (2026). https://doi.org/10.1038/s41598-026-38320-1
Nyckelord: klassobalans, random forest, omprovtagning, maskininlärning, ensemblemetoder