Clear Sky Science · sv
Federerat lärande för heterogena elektroniska journalssystem med kostnadseffektiv urval av deltagare
Varför det är så svårt att dela sjukhusdata
Moderna sjukhus samlar in enorma mängder digital information om sina patienter, från laboratorietester och vitala parametrar till läkemedel och ingrepp. I teorin borde det gå att bygga smartare datormodeller som förutser vilka patienter som löper risk och vilka behandlingar som kan hjälpa bäst genom att kombinera dessa poster över många institutioner. I praktiken använder dock sjukhusen olika mjukvarusystem, lagrar data i inkompatibla format och måste strikt skydda patienternas integritet och budgetar. Denna studie undersöker hur sjukhus kan lära av varandras data utan att kopiera dem eller överskrida kostnaderna.
Träna tillsammans utan att dela råa journaler
Författarna bygger vidare på en metod som kallas federerat lärande, där varje sjukhus tränar en lokal modell på sina egna patientjournaler och sedan endast delar modelluppdateringar, inte rådata. Ett centralt ”värd”-sjukhus koordinerar processen och syftar till att förbättra en prediktionsmodell för sina egna behov, till exempel att förutse komplikationer på intensivvårdsavdelningen. Andra sjukhus, kallade deltagare, medverkar mot ersättning. Denna uppställning undviker att känsliga journaler flyttas mellan institutioner, men väcker två svåra frågor: hur man hanterar många olika journalsystem och hur man undviker att betala partner som inte faktiskt hjälper modellen.
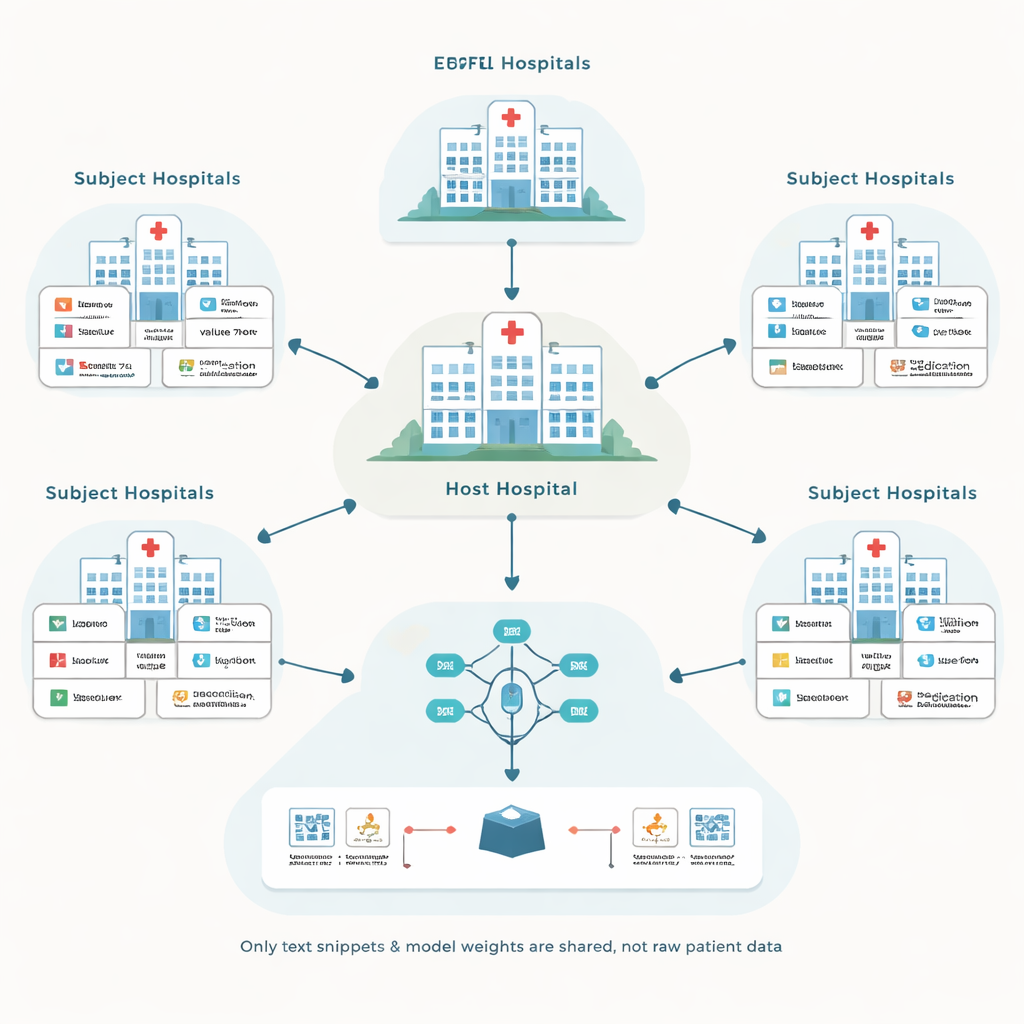
Att omvandla röriga journaler till ett gemensamt språk
Elektroniska journalsystem skiljer sig kraftigt i hur de märker och kodar information. Ett sjukhus kan lagra ett blodsockervärde under en numerisk kod, medan ett annat använder en annan kod för samma test. Traditionella lösningar försöker konvertera allt till en enda, noggrant utformad standarddatabas, vilket är dyrt och kräver många experttimmar. Istället omvandlar det föreslagna ramverket, kallat EHRFL, varje medicinskt händelse till en kort textfras. Till exempel blir en laboratorieanteckning som ett glukosvärde en fras som ”lab event glucose value 70 mg/dL.” Eftersom varje sjukhus redan har ordböcker som mappar lokala koder till läsbara namn kan denna konvertering automatiseras utan omfattande manuell justering.
Bygga patientprofiler från text
När händelser skrivits som text använder EHRFL moderna språkmodeller för att omvandla varje händelse till en numerisk vektor, och sammanfogar sedan många händelser till en enda ”patientembedding” – en kompakt sammanfattning av personens medicinska historia över ett tidsfönster. Dessa embeddings matas in i ett prediktionslager som hanterar flera kliniska uppgifter samtidigt, såsom att förutse död på sjukhus eller njurskada efter en intensivvårdsinskrivning. Författarna kör federerad träning på fem stora, verkliga intensivvårdsdatamängder som spänner över olika sjukhus, tidsperioder och journalsystem. Över en rad algoritmer, inklusive vanliga federerade metoder, presterar modeller tränade med detta textbaserade tillvägagångssätt konsekvent bättre än modeller tränade på ett enskilt sjukhus, även när underliggande dataformat skiljer sig åt.
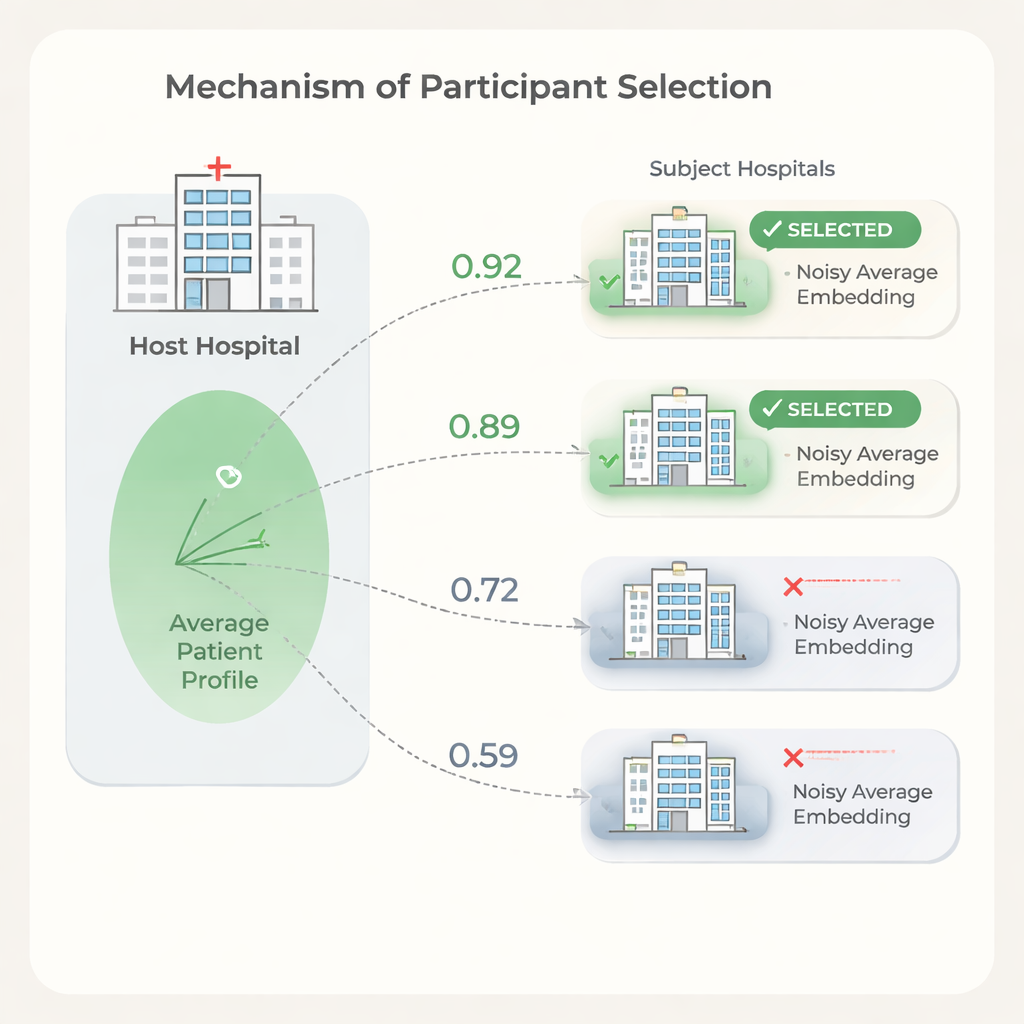
Välja rätt partner samtidigt som integriteten skyddas
Fler partnersjukhus betyder inte alltid bättre resultat. Vissa institutioner har patientpopulationer eller journalmönster som är så skilda från värdens att deras medverkan kan sakta ner träningen eller försämra prestandan något, samtidigt som kostnaden ökar. För att hantera detta föreslår författarna ett urvalssteg baserat på likhet mellan sjukhusens genomsnittliga patientembeddings. Värden tränar först en modell på sina egna data, delar modellvikterna, och varje kandidat-sjukhus använder dem för att beräkna patientembeddings. För att skydda integriteten kappar varje deltagare extrema värden i sina embeddings, beräknar ett medelvärde till en enda vektor och lägger sedan till noggrant kalibrerat slumpmässigt brus innan de endast skickar denna brusade medelvikt till värden. Värden jämför sitt eget medel med varje deltagares med enkla likhetsmått och väljer endast de mest liknande sjukhusen att gå vidare till full federerad körning.
Spara pengar utan att tappa noggrannhet
Experiment visar att likheten mellan sjukhusens genomsnittliga patientembeddings korrelerar med hur mycket varje sjukhus hjälper eller skadar värdens prediktionsprestanda. Genom att använda denna signal för att välja partner kan värden utesluta låg-likhets-sjukhus samtidigt som prediktionskvaliteten bibehålls eller till och med förbättras jämfört med att använda alla tillgängliga platser. Författarna skisserar också en kostnadsmodell som visar att eftersom avgifter för dataanvändning och träningstid skalar med antalet deltagande sjukhus, kan även måttliga minskningar i antalet partner ge betydande besparingar. Samtidigt är urvalsstegets beräkningar lätta: modellen tränas en gång och varje sjukhus utför endast enkla beräkningar på en enda genomsnittlig vektor.
Vad detta betyder för framtidens sjukvårds-AI
För läsare utanför fältet är huvudbudskapet att det kan vara möjligt för sjukhus att ”lära tillsammans” utan att slå ihop råa patientjournaler, och att göra det på ett sätt som respekterar både integritet och ekonomiska begränsningar. Genom att översätta skiftande journaler till en gemensam textform och sedan använda integritetsskyddade sammanfattningar av patientpopulationer för att välja kompatibla partner erbjuder EHRFL ett praktiskt recept för att bygga sjukhusspecifika prediktionsverktyg. Även om studien fokuserar på intensivvårdsdata kan samma idéer utvidgas till öppenvårdskliniker, akutmottagningar och till och med icke-medicinska domäner där organisationer vill samarbeta om bättre modeller utan att ge upp kontrollen över sina data.
Citering: Kim, J., Kim, J., Hur, K. et al. Federated learning for heterogeneous electronic health record systems with cost effective participant selection. Sci Rep 16, 6876 (2026). https://doi.org/10.1038/s41598-026-38299-9
Nyckelord: federerat lärande, elektroniska patientjournaler, patientsekretess, klinisk prediktion, sjukvårds-AI