Clear Sky Science · sv
Tensoruppdelning utan rang via metrisk inlärning
Att hitta mönster i ett hav av data
Modern vetenskap drunknar i komplex data: staplar av medicinska skanningar, kartor över hjärnaktivitet, astronomiska bilder och simuleringar av material. Att göra denna data begriplig innebär ofta att pressa den till enklare former utan att tappa det som verkligen betyder något. Denna artikel introducerar ett nytt sätt att göra det på. Istället för att försöka återskapa varje pixel troget, fokuserar den på att fånga de verkliga relationerna mellan prover – vilken hjärna liknar vilken, vilken galaxform påminner om vilken – så att den resulterande kartan över data speglar mening snarare än rå detalj.
Från att återskapa bilder till att mäta likhet
Traditionella verktyg för att förenkla flerdimensionell data, kända som tensoruppdelningar, fungerar lite som att bryta ett ackord i toner. De faktoriserar ett data"block" till ett litet antal grundläggande mönster plus vikter. För att göra detta måste man i förväg ange hur många mönster – ”rangen” – som är tillåtna, och de bedömer framgång utifrån hur väl den ursprungliga datan kan rekonstrueras. Det är idealiskt för kompression eller brusreducering, men inte nödvändigtvis för uppgifter som ”är dessa två ansikten samma person?” eller ”tillhör denna hjärnskanning en autistisk eller en typisk person?” där korrekt gruppering betyder mer än perfekt återgivning.
Parallellt har djupinlärning populariserat en annan idé: istället för att algebraiskt dekomponera en tensor, lär man en kompakt numerisk kod, eller inbäddning, via ett neuralt nätverk. Klassiska autoenkodare fokuserar fortfarande på rekonstruktion. Detta arbete vänder på målet. Det föreslår ett ”ingen-rang”-ramverk som inte låser en rang i förväg och som inte bryr sig om pixelperfekt återställning. Istället lär det en distansmått så att punkter som bör vara nära (samma person, samma diagnos, samma fysikaliska klass) hamnar som grannar i inbäddningsrummet, och punkter som bör vara olika skjuts isär.
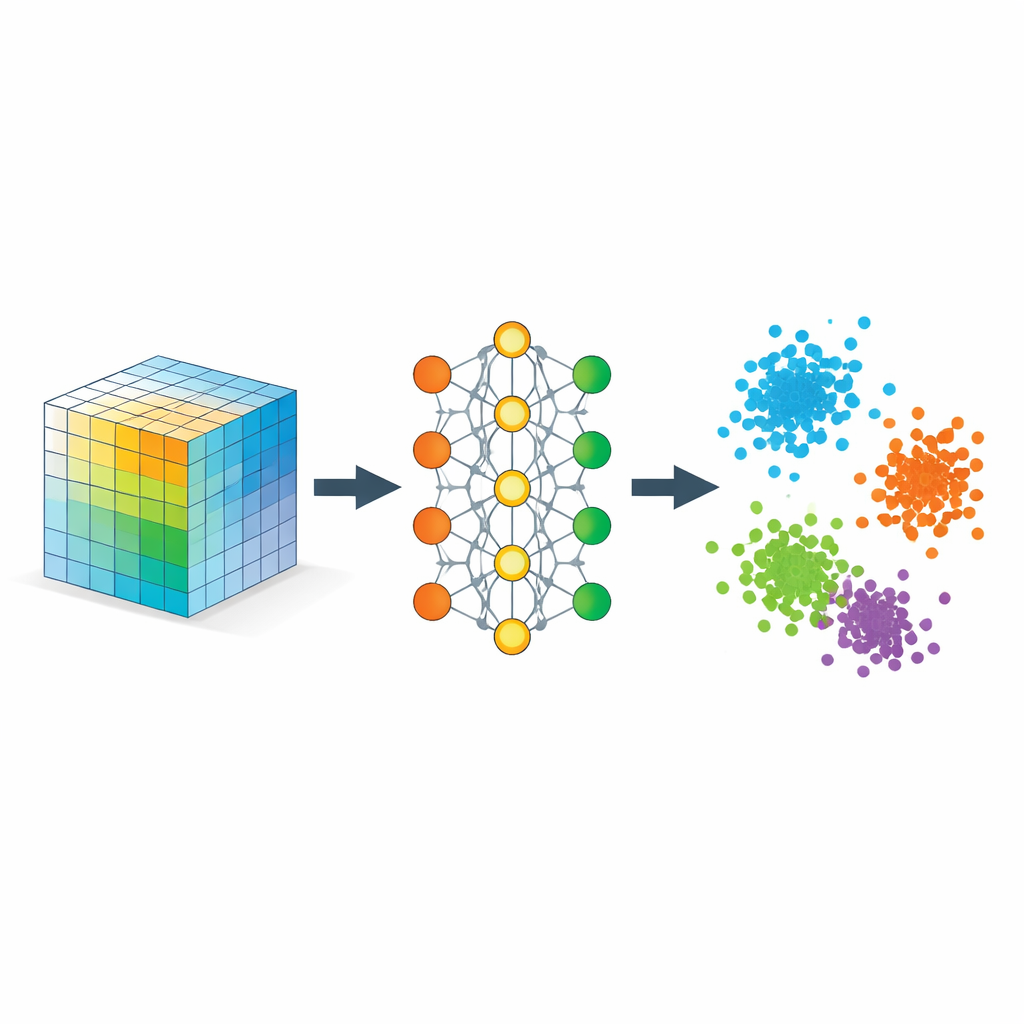
Att lära nätverket vad ”nära” ska betyda
Huvudingrediensen är en strategi kallad metrisk inlärning, här implementerad genom tripletter av exempel: ett ankarexempel, ett positivt exempel av samma typ och ett negativt exempel av en annan typ. Under träningen belönas nätverket när ankaret är närmare det positiva än det negativa med en säkerhetsmarginal. Över många sådana tripletter skulpterar denna enkla regel inbäddningsrummet så att avstånden speglar semantisk likhet snarare än rå pixellikhet. Ytterligare regulariserare uppmuntrar nätverket att sprida information jämnt över dimensionerna, undvika att allt kollapsar till en linje, och behålla lokala grannskap någorlunda intakta, så att närliggande punkter i ursprungsdatan förblir närliggande i inbäddningen.
Matematiskt visar författarna att denna inbäddning beter sig som en flexibel tensoruppdelning, men utan en förinställd rang. De inlärda koordinaterna kan tolkas som faktorer i en klassisk uppdelning av en likhetstensor vars poster mäter hur starkt olika delar av datan överensstämmer. Eftersom modellen bestraffar redundanta riktningar tenderar den att använda alla inbäddningsdimensioner effektivt, vilket låter datan själv avgöra hur många meningsfulla komponenter som behövs. Samtidigt ger de teoretiska garantier för att standardiserade träningsprocedurer konvergerar och att den resulterande geometrin troget separerar klasser utan att vilt förvränga meningsfulla lokala relationer.
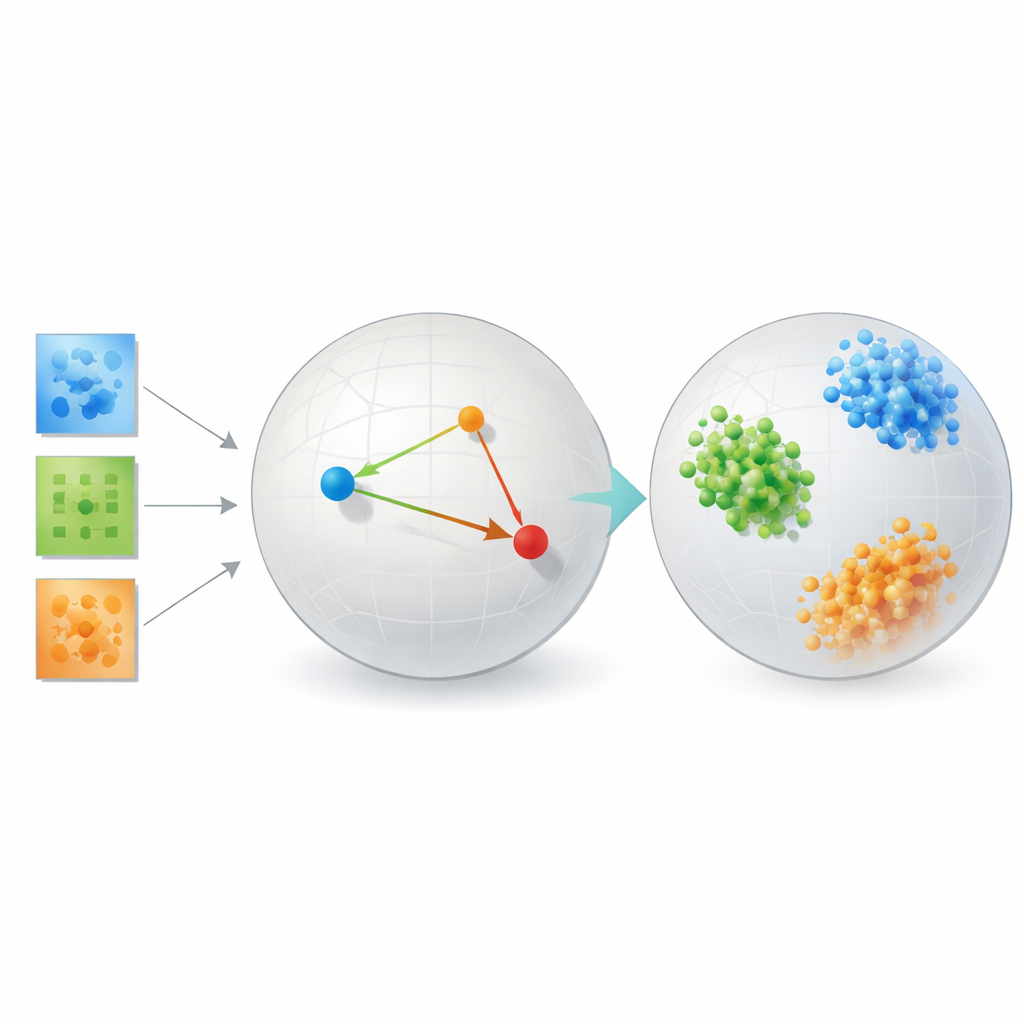
Att sätta metoden på prov
För att visa att deras angreppssätt inte bara är elegant teori testar författaren det på flera mycket olika problem. I ansiktsigenkänningsbenchmarks grupperar de inlärda inbäddningarna bilder av samma person i täta, välavgränsade kluster och överträffar dramatiskt klassiska metoder såsom huvudkomponenter, populära visualiseringsverktyg som t-SNE och UMAP, samt traditionella tensoruppdelningar som förlitar sig på fasta rangtal. På hjärnans konnektivitetsdata från personer med och utan autism upptäcker metoden ett rum där de två grupperna är mer tydligt separerade än med rekonstruktionsfokuserade tensorverktyg eller autoencoder-nätverk, vilket tyder på att den fångar kliniskt relevanta mönster i hur hjärnregioner interagerar.
Studien inkluderar också kontrollerade simuleringar av galaxformer och kristallstrukturer, där de ”sanna” kategorierna är exakt kända. Här klustrar det metriska inlärningsramverket nästan perfekt de syntetiska galaxerna och kristallerna efter deras underliggande fysikaliska typer. I alla dessa tillämpningar byter metoden konsekvent viss trohet mot ursprunglig pixellayout mot en representation där likhet och skillnad ligger i linje med vetenskaplig mening. Viktigt är att den gör detta utan de enorma datamängder och beräkningsresurser som ofta krävs för att träna transformerbaserade djupa modeller, vilka hade svårt att prestera på dessa relativt små vetenskapliga dataset.
Varför detta spelar roll för framtida vetenskaplig data
För forskare som söker mönster i begränsad, högdimensionell data erbjuder detta arbete ett tilltalande perspektivskifte. Istället för att gissa en rang och optimera för rekonstruktion kan forskare direkt efterfråga en inbäddning som speglar de relationer de bryr sig om: samma diagnos, samma materialfas, samma astrofysiska klass. Det föreslagna ingen-rang metriska inlärningsramverket visar att sådana inbäddningar kan vara både tolkbara och kraftfulla, särskilt när data är knapp. Som författaren noterar återstår utmaningar – inklusive att hantera klassobalans och att skala till många kategorier – men budskapet är klart: i många vetenskapliga problem kan det vara mer värdefullt att lära sig en bra notion av likhet än att återskapa varje detalj av den ursprungliga signalen.
Citering: Bagherian, M. No-rank tensor decomposition via metric learning. Sci Rep 16, 8326 (2026). https://doi.org/10.1038/s41598-026-38221-3
Nyckelord: metrisk inlärning, tensoruppdelning, representationsinlärning, dimensionsreduktion, vetenskaplig dataanalys