Clear Sky Science · sv
VLM-styrd nätverkskoppling för degraderingsmodellering vid degraderingsmedveten fusion av infraröda och synliga bilder
Skarpare nattseende för en brusig värld
Moderna kameror kan se i mörker, känna värme och övervaka vägen åt oss — men deras bilder är ofta långt ifrån perfekta. Gatlyktor blixtrar, skuggor slukar detaljer och sensorer lägger till prickigt brus. Denna studie presenterar ett nytt sätt att slå samman vanliga färgvideor med värmesensoriska infraröda bilder så att slutbilden blir tydligare och mer pålitlig, även när båda ingångarna är kraftigt degraderade. Metoden kan göra autonoma fordon, övervakningssystem och andra smarta kameror mer pålitliga i de situationer där vi behöver dem som mest: på natten, i dåligt väder och i röriga verkliga miljöer.
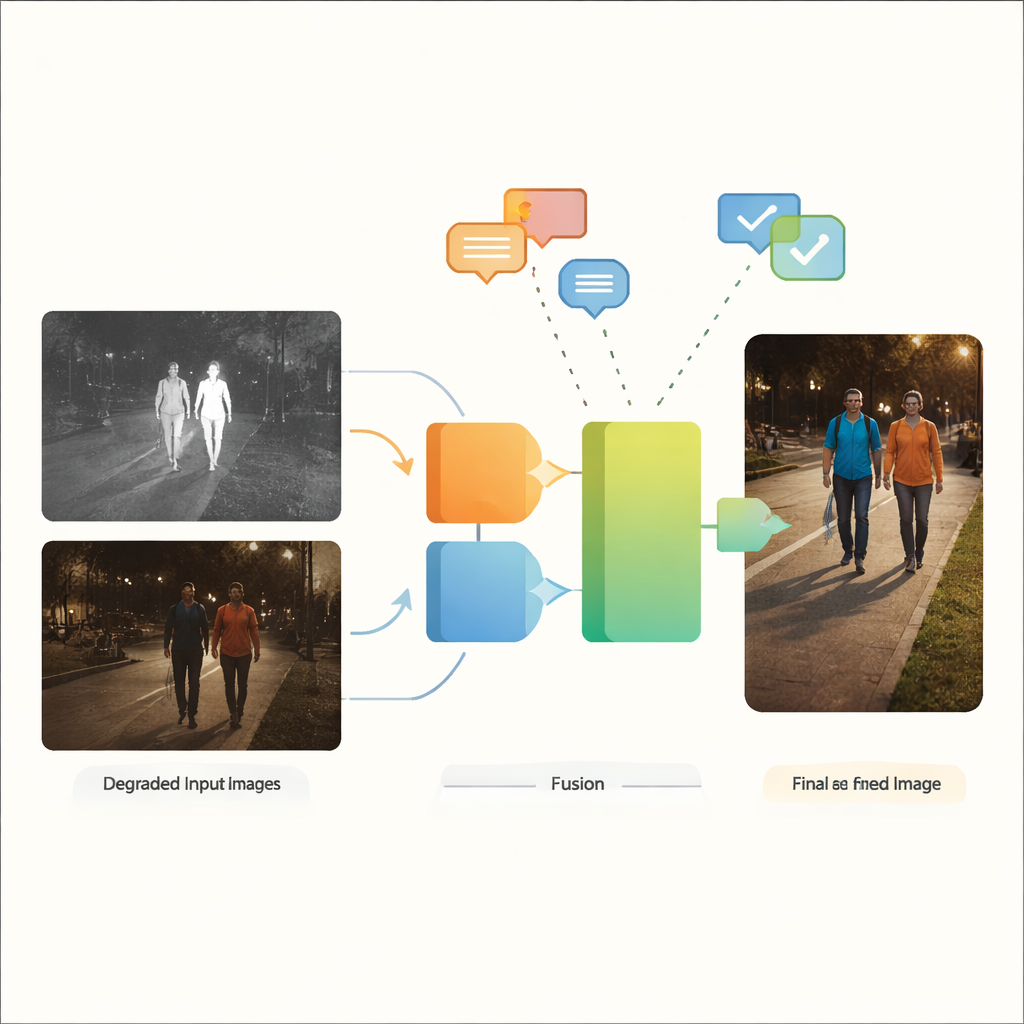
Därför är två ögon bättre än ett
Synlighetskameror fångar de rika färgerna och strukturerna som människor är vana att se, men de har svårt i svagt ljus, bländning och djupa skuggor. Infraröda kameror, däremot, känner av värme och kan lätt urskilja varma objekt såsom människor eller fordon i mörkret, även om deras bilder ofta ter sig platta och saknar fin detalj. Fusion av infraröda och synliga bilder syftar till att kombinera det bästa av båda: de klara konturerna hos varma mål från infrarött med den kontextuella detaljen och färgen från synligt ljus. Traditionellt antar dock de flesta fusionsmetoder att båda ingångsbilderna redan är rena och av hög kvalitet — en dålig match för verkliga gator, städer och industrimiljöer där oskärpa, brus, svagt ljus och överexponering är regel snarare än undantag.
När förbehandling inte räcker
Befintliga system hanterar vanligtvis dåliga bilder i två åtskilda steg. Först ljusar separata förbättringsverktyg upp mörka scener, minskar brus eller korrigerar kontrast. Först därefter blandar ett fusionsnät de förbättrade bilderna. Detta tvåstegsanslag har flera brister. Det tvingar ingenjörer att välja och finjustera olika förbättringsverktyg för varje typ av defekt och varje sensor, vilket gör arbetsflöden sköra och komplexa. Viktigare är att all information som går förlorad eller förvrängs under fristående förbättring inte kan återställas senare i fusionssteget. Nyare forskning har introducerat specialiserade nätverk anpassade till en specifik degradering eller använt språkstyrda modeller för att hantera en enda dålig modalitet i taget. Men när både infraröda och synliga bilder är degraderade — och ofta på olika sätt — förlitar sig dessa strategier fortfarande i hög grad på manuell förbehandling och har svårt att klara blandade, verkliga förhållanden.
Ett fusionsnät som förstår degradering
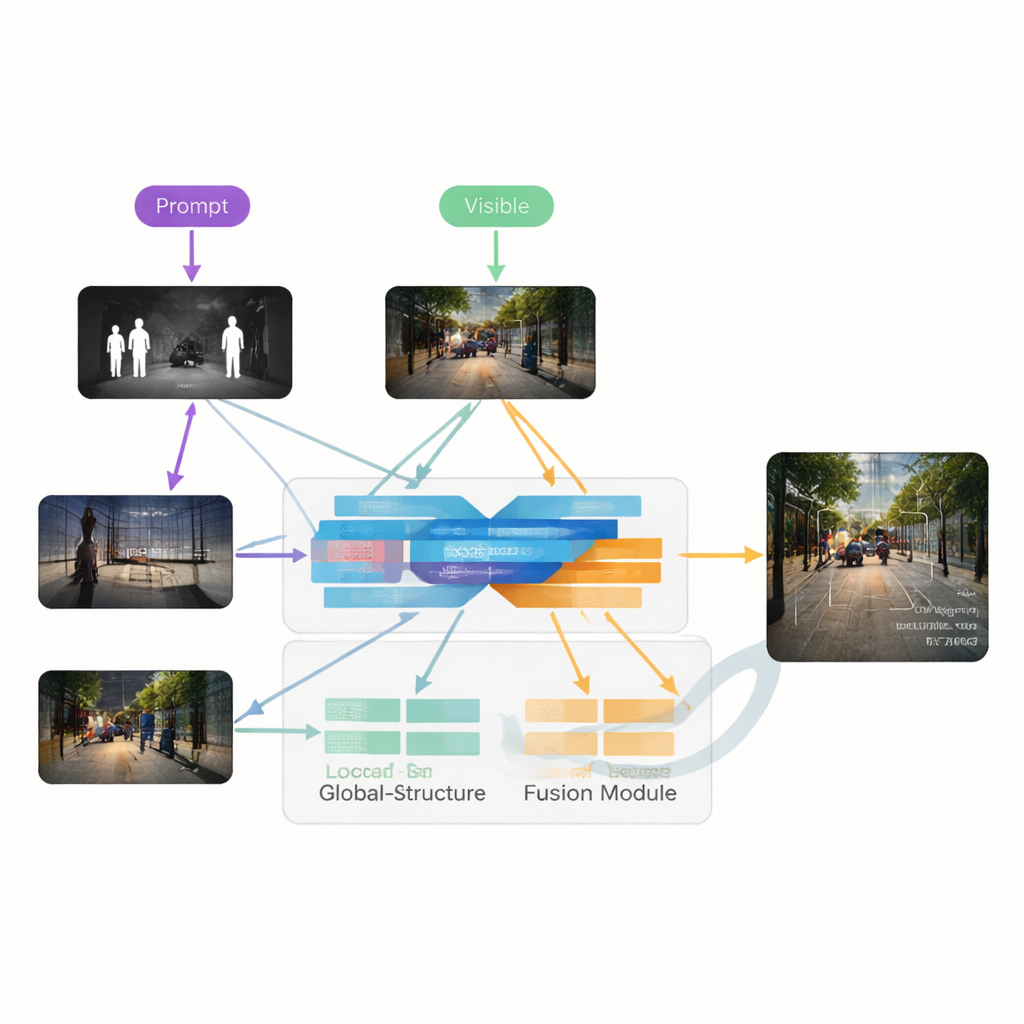
Författarna föreslår VGDCFusion, ett nytt djupinlärningsramverk som väver in degraderingshantering direkt i fusionsprocessen. Nyckelidén är att låta nätverket veta, i ord, vilka problem det bör förvänta sig och sedan använda den kunskapen i varje steg av feature-extraktion och sammansmältning. Korta textpromptar beskriver uppgiften (infraröd–synlig fusion) och de specifika problem som förekommer, såsom svagt ljus, överexponering, låg kontrast eller brus. En kraftfull vision–språk-modell — liknande system i stil med CLIP — omvandlar dessa promptar till kompakta numeriska beskrivningar. Dessa beskrivningar styr två huvudbyggstenar: Specific-Prompt Degradation-Coupled Extractor (SPDCE), som arbetar separat för varje modalitet, och Joint-Prompt Degradation-Coupled Fusion (JPDCF), som blandar information över modaliteter samtidigt som den uppmärksammar vilken typ av degradering som återstår.
Hur den guidade fusionsprocessen fungerar
Inuti varje SPDCE-modul styr promptbaserad vägledning nätverket mot de features som är viktiga och bort från artefakter. Multiskaliga konvolutionslager undersöker små omgivningar för att bevara kanter och texturer, medan Transformer-lager fångar större struktur och kontext. Tillsammans lär de sig att framhäva, till exempel, viktiga värmesignaturer i en brusig infraröd ruta eller svaga vägmarkeringar i en underexponerad synlig bild, samtidigt som sensorsbrus och ljusdefekter dämpas. Parallellt tar JPDCF-modulerna de uppstädade features från båda grenarna och kombinerar dem, återigen under promptstyrning. De använder spatial och kanaluppmärksamhet för att betona informativa regioner, filtrera kvarvarande degradering och föra samman kompletterande ledtrådar — såsom att alignera en ljus infraröd kontur av en fotgängare med färg och bakgrundsstruktur från den synliga kameran — innan de rekonstruerar en sammanslagen, trefärgskanals utgångsbild.
Sätta metoden på prov
För att demonstrera dess användbarhet utvärderade teamet VGDCFusion på flera offentliga dataset som inkluderar svagt ljus och överexponerade synliga bilder samt brusiga eller lågkontrast-infraröda bilder. De jämförde sin metod med en rad toppmoderna fusionsmetoder som spänner över autoenkodare, konvolutionsnät, generativa adversariella nätverk och Transformers. Med standardmått för bildkvalitet producerade VGDCFusion konsekvent sammanslagna bilder med skarpare kanter, bättre kontrast och mer naturlig färg, även när konkurrerande metoder gavs fördelen av noggrant finjusterad förbehandling. Det nya tillvägagångssättet förbättrade nyckelmetriker med omkring 15 % i genomsnitt i kraftigt degraderade scenarier. När de sammanslagna bilderna matades in i ett populärt objektdetekteringssystem ledde det också till högre detekteringsnoggrannhet än att använda antingen infraröda eller synliga bilder ensam, eller att använda andra fusionsnät.
Tydligare syn för säkrare system
Enkelt uttryckt visar detta arbete att det att berätta för ett bildfusionsnät vilka typer av visuella problem som förväntas — och låta det korrigera och fusera i ett tätt sammankopplat steg — kan ge renare, mer informativa bilder än att behandla förbättring och fusion som separata uppgifter. Genom att koppla degraderingsmodellering till fusionsprocessen och använda språkstyrda ledtrådar på varje lager kan VGDCFusion anpassa sig till varierande och blandade former av bilddegradering utan ständig manuell omjustering. Denna typ av intelligent, degraderingsmedveten fusion kan hjälpa framtida visionssystem, från självkörande bilar till säkerhetskameror, att se mer pålitligt i de röriga, ofullkomliga förhållanden som råder i verkliga världen.
Citering: Zhao, J., Zhang, T. & Cui, G. A VLM guided network coupling degradation modeling for degradation aware infrared and visible image fusion. Sci Rep 16, 8249 (2026). https://doi.org/10.1038/s41598-026-38181-8
Nyckelord: fusion av infrarött och synligt ljus, svagljusavbildning, vision-språk-modeller, bilddegradering, perception för autonom körning