Clear Sky Science · sv
En hybrid staplad ensemble-inlärningsram för multilabel-textkänsloavkänning
Varför det spelar roll att läsa känslor i text
Varje dag häller människor ut sina känslor i inlägg på sociala medier, recensioner och meddelanden. Dold i denna ordström finns tidiga varningssignaler om psykiska problem, ökande hatpropaganda och allmänhetens reaktioner på kriser och katastrofer. Men datorer ser vanligtvis bara ”positivt” eller ”negativt” sentiment och missar den blandning av känslor som verkliga människor ofta uttrycker samtidigt. Den här artikeln undersöker ett nytt sätt att lära maskiner att känna igen flera känslor i ett och samma textstycke, och att göra det inte bara på engelska utan också på språk som sällan drar nytta av avancerad artificiell intelligens.
Att gå bortom enkelt positivt eller negativt
Traditionella sentimentanalysverktyg är som trubbiga termometrar: de kan säga om stämningen är god eller dålig, men inte om någon känner ilska, rädsla, hopp eller lättnad samtidigt. Författarna menar att förståelsen av denna rikare emotionella palett är avgörande för tillämpningar som katastrofinsatser, stöd i terapi och kundservice. Ett meddelande som blandar rädsla och brådska kan till exempel kräva omedelbar uppmärksamhet, medan ett som förenar sorg och optimism kan behöva en annan typ av stöd. Att fånga flera känslor parallellt — känt som ”multilabel” känsloavkänning — är därför ett viktigt steg mot mer känsliga, människoorienterade system.
Ge röst åt förbisedda språk
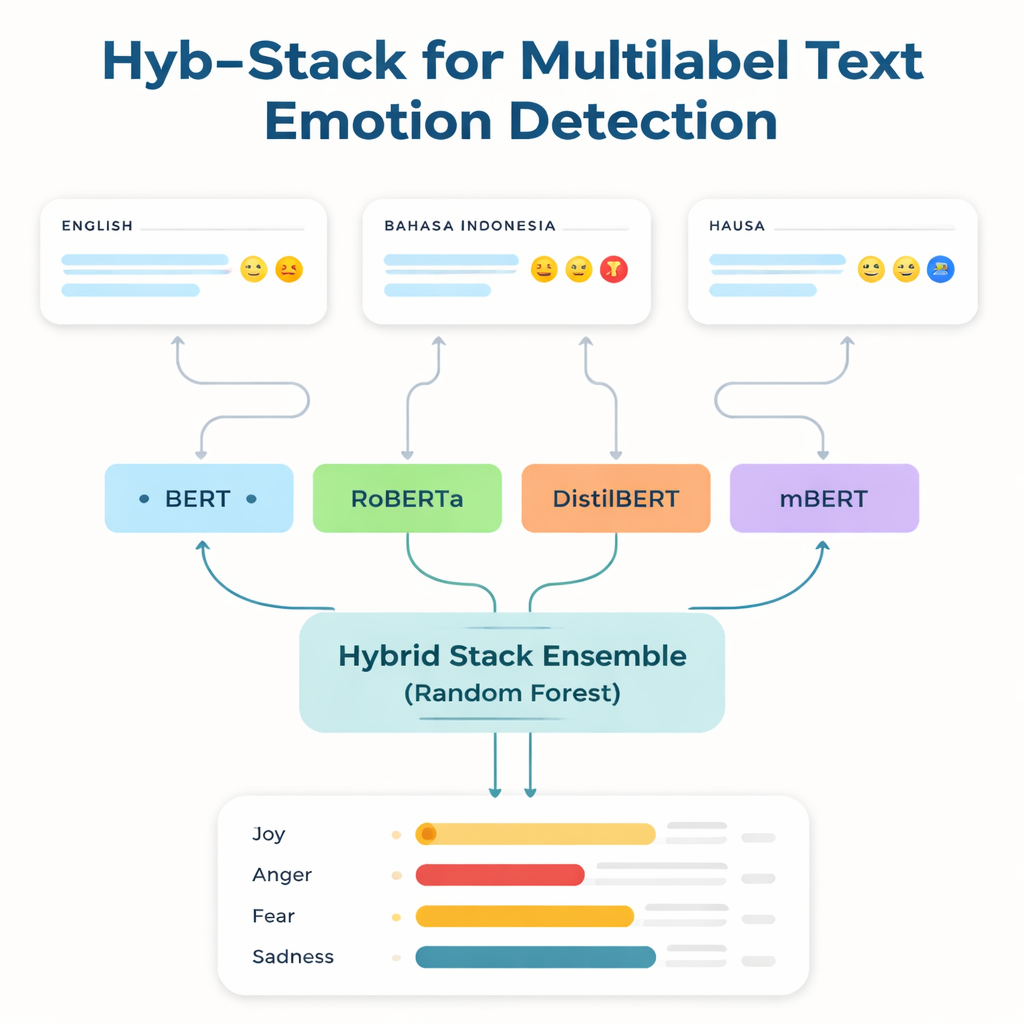
De mest kraftfulla språkteknologierna tränas och finjusteras för engelska och ett fåtal andra vida använda språk. Talare av språk med få resurser — de som har lite etiketterad data och få digitala verktyg — hamnar ofta på efterkälken. För att tackla denna klyfta fokuserar forskarna på tre dataset: en välkänd engelsk känslobenchamark; en Bahasa Indonesia-samling centrerad kring kränkande och hatfyllda yttringar; och ett helt nytt Hausa-Twitterkorpus som de skapade, kallat HaEmoC_V1. Hausa-datasetet innehåller mer än tolv tusen noggrant rensade och annoterade tweets, där varje tweet är taggad med en eller flera av elva känslor som ilska, glädje, förtroende, pessimism och förväntan. Expertgranskare kontrollerade etiketterna och överensstämmelsespoängen visade att annotationerna är både konsekventa och pålitliga.
Kombinera flera smarta läsare till en
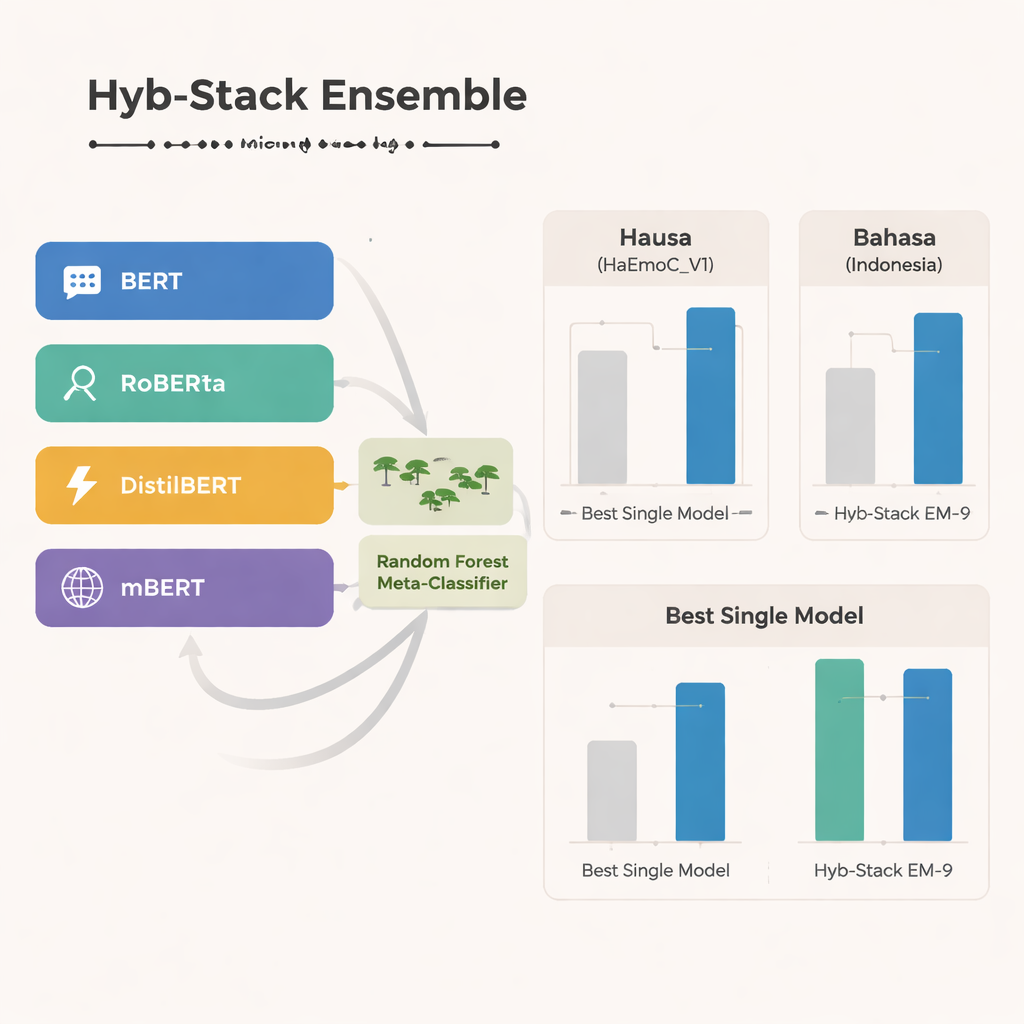
I studiens kärna finns Hyb-Stack, en hybrid staplad ensemble — en slags ”expertråd” för språk. Fyra avancerade transformerbaserade modeller (BERT, RoBERTa, DistilBERT och den flerspråkiga mBERT) finjusteras vardera för att läsa emotionella signaler i text. Istället för att lita på bara en modell låter Hyb-Stack dem alla göra förutsägelser och matar sedan deras interna poäng in i en andra nivå beslutstagare: en Random Forest-klassificerare. Denna metaklassificerare lär sig hur de olika modellernas styrkor ska viktas och fångar komplexa mönster i hur känslor samförekommer. Teamet testar också enklare ensemblemetoder som bara medelvärdesbildar förutsägelser, med eller utan viktning baserat på tidigare prestanda, för att se om den mer komplicerade stackningen verkligen lönar sig.
Hur väl den hybrida metoden presterar
Över alla tre språken utmärker sig den flerspråkiga mBERT som den enskilt starkaste modellen och presterar särskilt väl på den nybyggda Hausa-datan och Bahasa Indonesia-datat för hatretorik. Ändå går den hybrida ensemblen ännu längre. En särskild kombination — kallad EM-9, som slår samman BERT, DistilBERT och mBERT inom Hyb-Stack-ramverket — levererar konsekvent de bästa resultaten. Den uppnår högre F1-poäng, en vanlig måttstock för noggrannhet, än någon enskild modell eller enkel medelvärdesmetod, med de största vinsterna i de resursfattiga Hausa- och Bahasa Indonesia-datamängderna. Detaljerade felanalyser visar att kvarstående misstag vanligtvis uppstår mellan närbesläktade känslor, såsom glädje kontra överraskning eller sorg kontra rädsla, vilket speglar människans naturliga känslighet snarare än tydliga systemfel.
Vad detta betyder för system i verkliga världen
För en allmän läsare är huvudsaken att kombinera flera AI-modeller på ett smart sätt kan hjälpa datorer att läsa känslor i text mer korrekt, särskilt på språk som länge försummats i tekniken. Genom att bygga ett högkvalitativt Hausa-känslokorpus och visa att hybridensembler överträffar enskilda modeller och enkla röstningsscheman, visar författarna en praktisk väg mot mer inkluderande, känslomässigt medvetna verktyg. Framtida arbete kommer att utvidga tillvägagångssättet till mer subtila emotionella nyanser, kodblandat språk, emojis och ytterligare underrepresenterade språk, med målet att skapa system som kan uppfatta inte bara om människor är glada eller ledsna utan också hur och varför de känner som de gör — oavsett vilket språk de talar.
Citering: Adamu, H., Azmi Murad, M.A. & Nasharuddin, N.A. A hybrid stacked ensemble learning framework for multilabel text emotion detection. Sci Rep 16, 7714 (2026). https://doi.org/10.1038/s41598-026-38172-9
Nyckelord: känsloavkänning, flerspråkig NLP, ensemble-inlärning, transformermodeller, språk med få resurser